hualinux 进阶 1.7:kubeadm1.18搭建k8s群集 (最详细的手把手版)
目录
一、环境说明
1.1常用问答
1.2 实验目标
1.3 相关配置说明
1.3.1关闭selinux
1.3.2关闭防火墙
1.3.3 时间同步
1.3.4 安装常用软件
1.3.5 安装epel和remi源(本章可不要)
1.4所涉及的软件及版本
1.5 Kubernetes全局架构图
二、安装kubeadm(master和node)
2.1 安装前准备(所有节点)
2.1.1 关闭swap
2.1.2 安装docker-ce及添加镜像加速器
2.2 kubeadm安装(所有节点)
三、创建master节点(master)
3.1 创建master节点kubeadm init
3.1.1 init初始化前配置
3.1.2 执行init
3.1.3 kubeadm ini大概流程
3.2安装容器网络插件
3.2.1 查看节点状态
3.3安装DashBoard插件
3.3.1 安装
3.3.2 配置
四、创建node节点并加入master中(node)
4.1 kubeadm join 的工作流程
4.2 kubeadm安装
4.3 加入集群
五、 安装容器存储插件Rook(可选 )
5.1 Rook介绍
5.2 为什么我要选择 Rook 项目呢
5.3 安装 Rook-ceph
5.3.1 安装common.yaml 和operator.yaml
5.3.2 查看相关状态
5.3.3 创建群集
前面花了5章讲了docker,现在就讲docker其中的一种编排工具k8s,学习k8s建议先用集成工具,不要一起来就直接二进制安装,搞得太复杂,这里推荐用kubeadm,而且高可用HA已经是GA了,有些公司已经用它跑生产环境。
kubeadmin有很多已经设置好,灵活性没有用二进制那么好,但是省了不少麻烦。一般规模不大的应用已经够用了
我这里不使用kubeadm的HA使用单主,因为是实验给初学者的,生产环境建议用HA
一、环境说明
Kubeadm 是一个工具,它提供了 kubeadm init 以及 kubeadm join 这两个命令作为快速创建 kubernetes 集群的最佳实践。
kubeadm 通过执行必要的操作来启动和运行一个最小可用的集群。它被故意设计为只关心启动集群,而不是之前的节点准备工作。同样的,诸如安装各种各样值得拥有的插件,例如 Kubernetes Dashboard、监控解决方案以及特定云提供商的插件,这些都不在它负责的范围。
相反,我们期望由一个基于 kubeadm 从更高层设计的更加合适的工具来做这些事情;并且,理想情况下,使用 kubeadm 作为所有部署的基础将会使得创建一个符合期望的集群变得容易。
1.1常用问答
问:minikuke和kubeadm有什么区别吗?
答:Minikube只是本地玩玩用的,官网给出Minikube适合做学习环境
minikube基本上你可以认为是一个实验室工具,只能单机部署,里面整合了k8最主要的组件,无法搭建集群,且由于程序做死无法安装各种扩展插件(比如网络插件、dns插件、ingress插件等等),主要作用是给你了解k8用的。而kudeadm搭建出来是一个真正的k8集群,可用于生产环境(HA需要自己做),和二进制搭建出来的集群几乎没有区别。
问:kubeadm目前还是不适用应该于生产环境吗?
答: 已经可以
kubeadm高可用的 Kubernetes 集群已经GA了,即:Etcd、Master 组件都应该是多节点集群
另一方面,Lucas 也正在积极地把 kubeadm phases 开放给用户,即:用户可以更加自由地定制 kubeadm 的每一个部署步骤。这些举措,都可以让这个项目更加完善,我对它的发展走向也充满了信心。
当然,如果你有部署规模化生产环境的需求,我推荐使用kops或者 SaltStack 这样更复杂的部署工具。
问: 怎么二进制部署kubernetes?毕竟kubeadm不适用于生产环境,用二进制部署还是挺复杂的
不建议直接使用二进制文件部署k8s。而建议你花时间了解一下kubeadm的高可用部署。宝贵的时间应该用在刀刃上。
1.2 实验目标
- 所有节点上安装 Docker 和 kubeadm
- 部署 Kubernetes Master节点
- 部署容器网络插件(master,node添加会自动安装配置)
- 部署 Kubernetes Worker node节点(添加进master)
- 部署 Dashboard 可视化插件(master上安装)
- 部署容器存储插件:Rook ceph(master上安装)
主要框架图为:

1.3 相关配置说明
参照kubeadm官网要求做了一下调整
- 电脑一始,CPU支持VT,内存≥8G,可用磁盘空间大于60G
- 安装VMware Workstation虚拟机,我这里是vm10
- 创建3个虚拟机,安装CentOS-8.x-x86_64,我这里是centos8.2
| 主机名 |
IP地址(NAT) |
IP地址(内网) |
描述 |
| vm82 |
eth0:192.168.128.82 |
eth1:192.168.3.82 |
最小化安装,2.5G内存,硬盘系统盘50G 充当master,最少2G内存 最好是3.5G或以上 |
| vm21 |
eth0:192.168.128.21 |
eth1:192.168.3.21 |
最小化安装,2G内存,硬盘系统盘50G 充当node节点1 发现2G都卡,最好2.8G或以上 |
| vm22 |
eth0: 192.168.128.22 |
eth1:192.168.3.22 |
最小化安装,2G内存,硬盘系统盘50G 充当node节点2 最好是2.8G或以上 |
注:因为总内存才8G,所以只能先把vm82开着,然后逐台开vm821、vm822
1.3.1关闭selinux
#临时关闭:
setenforce off
#永久性关闭:
sed -i 's/SELINUX=enforcing/SELINUX=disabled/' /etc/selinux/config
sed -n '/SELINUX=/p' /etc/selinux/config
#重启生效
shutdown -r now
1.3.2关闭防火墙
#禁止firewalld及开机启动
systemctl stop firewalld.service
systemctl disable firewalld.service1.3.3 时间同步
#yum和dnf都可以安装,推荐用dnf
#yum install chrony
dnf install chrony
#配置时间服务器,我这里使用的是中国区的
#备份配置
cp /etc/chrony.conf /etc/chrony.conf.orig
#注解掉pool
sed -i '/^pool/s/^/#/' /etc/chrony.conf
grep '#pool' /etc/chrony.conf
sed -i '/#pool/a\server cn.pool.ntp.org iburst' /etc/chrony.conf
sed -i '/#pool/a\server ntp.ntsc.ac.cn iburst' /etc/chrony.conf
sed -i '/#pool/a\server ntp1.aliyun.com iburst' /etc/chrony.conf
grep -A 3 '#pool' /etc/chrony.conf
#重启服务
systemctl restart chronyd.service1.3.4 安装常用软件
#centos8之前用yum
dnf install -y vim lrzsz wget curl man tree rsync gcc gcc-c++ cmake telnet1.3.5 安装epel和remi源(本章可不要)
yum install https://dl.fedoraproject.org/pub/epel/epel-release-latest-8.noarch.rpm -y
wget http://rpms.remirepo.net/enterprise/remi-release-8.rpm
rpm --import http://rpms.famillecollet.com/RPM-GPG-KEY-remi
rpm -ih remi-release-8.rpm
rm -f remi-release-8.rpm
1.4所涉及的软件及版本
| 软件 |
版本 |
安装方式 |
备注 |
| xshell |
6.0 |
win exe |
ssh连接连接工具 |
| Docer-ce |
19.03.12 |
yum,最新稳定版 |
master和node都需要 |
| Kubeadm |
1.18.5 |
yum,最新稳定版 |
master和node都需要 |
| weave |
2.6.5 |
kubectl apply |
master端,网络插件 |
| DashBoard |
2.0.3 |
kubectl apply |
master端,UI界面 |
| Rook |
1.3 |
kubectl apply |
master端,ceph存储插件 |
1.5 Kubernetes全局架构图

注意:
目前为止,在容器里运行 kubelet,依然没有很好的解决办法,我也不推荐你用容器去部署 Kubernetes 项目,正因为如此,kubeadm 选择了一种妥协方案:把 kubelet 直接运行在宿主机上,然后使用容器部署其他的 Kubernetes 组件。
- Kubernetes 主控组件(Master) 包含三个进程,都运行在集群中的某个节上,通常这个节点被称为 master 节点。这些进程包括:kube-apiserver、kube-controller-manager和kube-scheduler。
- 非 master 节点,也叫node节点,最主要的是kubelet,和 master 节点进行通信。
有兴趣的可以看一下 Kubernetes组件
二、安装kubeadm(master和node)
根据kubeadm官网文档安装要求
- 一台或多台运行着下列系统的机器:
- Ubuntu 16.04+
- Debian 9+
- CentOS 7
- Red Hat Enterprise Linux (RHEL) 7
- Fedora 25+
- HypriotOS v1.0.1+
- Container Linux (测试 1800.6.0 版本)
- 每台机器 2 GB 或更多的 RAM (如果少于这个数字将会影响您应用的运行内存)
- 2 CPU 核或更多
- 集群中的所有机器的网络彼此均能相互连接(公网和内网都可以)
- 节点之中不可以有重复的主机名、MAC 地址或 product_uuid。请参见这里 了解更多详细信息。
- 开启机器上的某些端口。请参见这里 了解更多详细信息。
- 禁用交换分区。为了保证 kubelet 正常工作,您 必须 禁用交换分区。
2.1 安装前准备(所有节点)
注:3台主机执行hostname命令分别得到“vm82、vm821、vm822”,并做了hosts绑定
echo '192.168.3.82 vm82' >>/etc/hosts
echo '192.168.3.21 vm821' >>/etc/hosts
echo '192.168.3.22 vm822' >>/etc/hosts
tail -3 /etc/hosts2.1.1 关闭swap
#swap没关等等(会影响kubelet的启动),swap的话可以通过设置swapoff -a来进行关闭,
swapoff -a && sysctl -w vm.swappiness=0
sed -i '/swap/s/^/#/' /etc/fstab
grep 'swap' /etc/fstab
2.1.2 安装docker-ce及添加镜像加速器
#修改内核参数,使它能支持转发功能,要不运行docker后,如果做端口映射会访问不到!
grep net.ipv4.ip_forward /etc/sysctl.conf
#设置转发为1
echo 'net.ipv4.ip_forward=1'>>/etc/sysctl.conf
#使用配置生效
sysctl -p
#查看是否生效
sysctl net.ipv4.ip_forward
K8s除了kubelet组件,其它都慢容器化的,所以要安装docker Docker centos
官方链接:https://docs.docker.com/engine/install/centos/#os-requirements
发现只有centos7的,不过测试也适合centos8
#卸载旧版本,如果存在的话
yum remove docker \
docker-client \
docker-client-latest \
docker-common \
docker-latest \
docker-latest-logrotate \
docker-logrotate \
docker-engine
#官方的docker安装很慢,我这里选择使用阿里云docker-ce镜像安装
dnf install -y dnf-utils device-mapper-persistent-data lvm2 fuse-overlayfs wget
yum-config-manager --add-repo \
https://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
wget https://mirrors.aliyun.com/docker-ce/linux/centos/7/x86_64/stable/Packages/\
containerd.io-1.2.13-3.2.el7.x86_64.rpm
yum install -y containerd.io-1.2.13-3.2.el7.x86_64.rpm
yum install -y docker-ce docker-ce-cli


ps:你没看错,是centos7,官网暂时没有centos8,经测试发现也适合centos8
#启动服务
systemctl start docker
#查看运行状态
systemctl status docker
#开机运行
systemctl enable docker#确保网络模块开机加载
lsmod | grep overlay
lsmod | grep br_netfilter#若上面命令无返回值输出或提示文件不存在,需执行以下命令:
cat>/etc/modules-load.d/docker.conf<#配置内核参数,将桥接的IPv4流量传递到iptables的链
cat >/etc/sysctl.d/k8s.conf<#华为云加速
国内访问 Docker Hub 有时会遇到困难,此时可以配置镜像加速器。国内很多云服
务商都提供了加速器服务,例如:
- DaoCloud 加速器
- 灵雀云加速器
- 华为云(需要登录)
- 阿里云docker镜像加速器(需要登录)
我这里使用免费的华为云加速器,我认识华为云镜像,找到 DockerHub官方镜像,点一下图标,如下图所示:
发现要登陆才会自动生成一个,如果没有注册的注册一个账号即可,我这里已经注解了,所以登录一下。登陆之后再点一下
DockerHub官方镜像图标,会变成如下所示:

sudo mkdir -p /etc/docker
sudo tee /etc/docker/daemon.json <<- 'EOF'
{
"registry-mirrors": ["https://8080000021119000000.mirror.swr.myhuaweicloud.com"]
}
EOF
#重导入配置
sudo systemctl daemon-reload
#重启docker
sudo systemctl restart docker
#备份
cp /etc/docker/daemon.json /etc/docker/daemon.json.orig

2.2 kubeadm安装(所有节点)
根据官网kubeadmin安装文档说明 需要在每台机器上都安装以下的软件包:
kubeadm: 用来初始化集群的指令。kubelet: 在集群中的每个节点上用来启动 pod 和 container 等。和 master 节点进行通信。kubectl: 用来与集群通信的命令行工具。kubeadm 不能 帮您安装或管理
kubelet或kubectl,所以您得保证他们满足通过 kubeadm 安装的 Kubernetes 控制层对版本的要求。如果版本没有满足要求,就有可能导致一些难以想到的错误或问题。然而控制层与 kubelet 间的 小版本号 不一致无伤大雅,不过请记住 kubelet 的版本不可以超过 API server 的版本。例如 1.8.0 的 API server 可以适配 1.7.0 的 kubelet,反之就不行了
kubeadm官网安装文档 发现网络不好,所以使用国内的源,我这里使用阿里云镜像的Kubernetes
#写入kubernetes源文件
cat < /etc/yum.repos.d/kubernetes.repo
[kubernetes]
name=Kubernetes
baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64/
enabled=1
gpgcheck=1
repo_gpgcheck=1
gpgkey=https://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg https://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg
EOF
#关闭selinux,默认我已经关闭了
setenforce 0 ps: 由于官网未开放同步方式, 可能会有索引gpg检查失败的情况, 这时请用
yum install -y --nogpgcheck kubelet kubeadm kubectl安装
#安装kubeadm(所有节点)
#同时会安装上kubelet kubeadm kubectl kubernetes-cni,并没有任何docker镜像下载
yum install -y kubeadm
#启动服务后一会也会停止掉,属于正常现象,因为 /etc/kubernetes/manifests/ 没有配置文件
systemctl enable kubelet && systemctl start kubelet
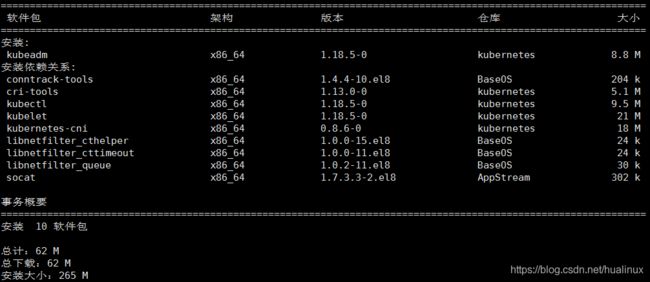
- kubeadm:k8集群的一键部署工具,通过把k8的各类核心组件和插件以pod的方式部署来简化安装过程
- kubelet:运行在每个节点上的node agent,k8集群通过kubelet真正的去操作每个节点上的容器,由于需要直接操作宿主机的各类资源,所以没有放在pod里面,还是通过服务的形式装在系统里面
- kubectl:kubernetes的命令行工具,通过连接api-server完成对于k8的各类操作
- kubernetes-cni:k8的虚拟网络设备,通过在宿主机上虚拟一个cni0网桥,来完成pod之间的网络通讯,作用和docker0类似。
#安装完了,重启一下
shutdown -r now
三、创建master节点(master)
3.1 创建master节点kubeadm init
3.1.1 init初始化前配置
/proc/sys/net/bridge/bridge-nf-call-iptables这个参数,需要设置为1,否则kubeadm预检也会通不过,貌似网络插件会用到这个内核参数。上面已经设置了
3.1.2 执行init
正常来说我们使用 kubeadm init来初始化启动一个集群就可以了,但是由于初始化过程中需要请求k8s.gcr.io下载镜像,可是国内的网络环境,呃...
所以我们这里采用把相关镜像手动下载下来的方法规避这个问题,下载完后再kubeadm init,由于本地已经有了相关镜像,所以就不会再请求k8s.gcr.io
[root@vm82 ~]# kubeadm config images list
W0711 17:50:27.488618 6541 configset.go:202] WARNING: kubeadm cannot validate component configs for API groups [kubelet.config.k8s.io kubeproxy.config.k8s.io]
k8s.gcr.io/kube-apiserver:v1.18.5
k8s.gcr.io/kube-controller-manager:v1.18.5
k8s.gcr.io/kube-scheduler:v1.18.5
k8s.gcr.io/kube-proxy:v1.18.5
k8s.gcr.io/pause:3.2
k8s.gcr.io/etcd:3.4.3-0
k8s.gcr.io/coredns:1.6.7#使用脚本自动安装
cat>kubeadm_config_images_list.sh<#执行之后,看一下7个镜像是否下载完整了
[root@vm82 ~]# docker images|grep k8s.gcr.io
k8s.gcr.io/kube-proxy v1.18.5 a1daed4e2b60 2 weeks ago 117MB
k8s.gcr.io/kube-apiserver v1.18.5 08ca24f16874 2 weeks ago 173MB
k8s.gcr.io/kube-controller-manager v1.18.5 8d69eaf196dc 2 weeks ago 162MB
k8s.gcr.io/kube-scheduler v1.18.5 39d887c6621d 2 weeks ago 95.3MB
k8s.gcr.io/pause 3.2 80d28bedfe5d 4 months ago 683kB
k8s.gcr.io/coredns 1.6.7 67da37a9a360 5 months ago 43.8MB
k8s.gcr.io/etcd 3.4.3-0 303ce5db0e90 8 months ago 288MB
#此命令初始化一个 Kubernetes master 节点
相关参数选项kubeadm-init
#我这里指定网络段,如果不指定中可以省略--pod,可以加 “--dry-run”试运行,不会有改动
kubeadm init --pod-network-cidr=172.168.6.0/16
可以看到终于安装成功了,kudeadm帮你做了大量的工作,包括kubelet配置、各类证书配置、kubeconfig配置、插件安装等等(这些东西自己搞不知道要搞多久,反正估计用过kubeadm没人会再愿意手工安装了)。执行结果如下
[root@vm82 ~]# kubeadm init --pod-network-cidr=172.168.6.0/16
W0711 23:46:55.175219 6606 configset.go:202] WARNING: kubeadm cannot validate component configs for API groups [kubelet.config.k8s.io kubeproxy.config.k8s.io]
[init] Using Kubernetes version: v1.18.5
[preflight] Running pre-flight checks
[WARNING IsDockerSystemdCheck]: detected "cgroupfs" as the Docker cgroup driver. The recommended driver is "systemd". Please follow the guide at https://kubernetes.io/docs/setup/cri/
[WARNING FileExisting-tc]: tc not found in system path
[WARNING Hostname]: hostname "vm82" could not be reached
[WARNING Hostname]: hostname "vm82": lookup vm82 on 192.168.128.2:53: no such host
[preflight] Pulling images required for setting up a Kubernetes cluster
[preflight] This might take a minute or two, depending on the speed of your internet connection
[preflight] You can also perform this action in beforehand using 'kubeadm config images pull'
[kubelet-start] Writing kubelet environment file with flags to file "/var/lib/kubelet/kubeadm-flags.env"
[kubelet-start] Writing kubelet configuration to file "/var/lib/kubelet/config.yaml"
[kubelet-start] Starting the kubelet
[certs] Using certificateDir folder "/etc/kubernetes/pki"
[certs] Generating "ca" certificate and key
[certs] Generating "apiserver" certificate and key
[certs] apiserver serving cert is signed for DNS names [vm82 kubernetes kubernetes.default kubernetes.default.svc kubernetes.default.svc.cluster.local] and IPs [10.96.0.1 192.168.128.82]
[certs] Generating "apiserver-kubelet-client" certificate and key
[certs] Generating "front-proxy-ca" certificate and key
[certs] Generating "front-proxy-client" certificate and key
[certs] Generating "etcd/ca" certificate and key
[certs] Generating "etcd/server" certificate and key
[certs] etcd/server serving cert is signed for DNS names [vm82 localhost] and IPs [192.168.128.82 127.0.0.1 ::1]
[certs] Generating "etcd/peer" certificate and key
[certs] etcd/peer serving cert is signed for DNS names [vm82 localhost] and IPs [192.168.128.82 127.0.0.1 ::1]
[certs] Generating "etcd/healthcheck-client" certificate and key
[certs] Generating "apiserver-etcd-client" certificate and key
[certs] Generating "sa" key and public key
[kubeconfig] Using kubeconfig folder "/etc/kubernetes"
[kubeconfig] Writing "admin.conf" kubeconfig file
[kubeconfig] Writing "kubelet.conf" kubeconfig file
[kubeconfig] Writing "controller-manager.conf" kubeconfig file
[kubeconfig] Writing "scheduler.conf" kubeconfig file
[control-plane] Using manifest folder "/etc/kubernetes/manifests"
[control-plane] Creating static Pod manifest for "kube-apiserver"
[control-plane] Creating static Pod manifest for "kube-controller-manager"
W0711 23:47:04.536014 6606 manifests.go:225] the default kube-apiserver authorization-mode is "Node,RBAC"; using "Node,RBAC"
[control-plane] Creating static Pod manifest for "kube-scheduler"
W0711 23:47:04.542916 6606 manifests.go:225] the default kube-apiserver authorization-mode is "Node,RBAC"; using "Node,RBAC"
[etcd] Creating static Pod manifest for local etcd in "/etc/kubernetes/manifests"
[wait-control-plane] Waiting for the kubelet to boot up the control plane as static Pods from directory "/etc/kubernetes/manifests". This can take up to 4m0s
[apiclient] All control plane components are healthy after 33.518941 seconds
[upload-config] Storing the configuration used in ConfigMap "kubeadm-config" in the "kube-system" Namespace
[kubelet] Creating a ConfigMap "kubelet-config-1.18" in namespace kube-system with the configuration for the kubelets in the cluster
[upload-certs] Skipping phase. Please see --upload-certs
[mark-control-plane] Marking the node vm82 as control-plane by adding the label "node-role.kubernetes.io/master=''"
[mark-control-plane] Marking the node vm82 as control-plane by adding the taints [node-role.kubernetes.io/master:NoSchedule]
[bootstrap-token] Using token: lm15t2.xxkc4z99tcfmwb7c
[bootstrap-token] Configuring bootstrap tokens, cluster-info ConfigMap, RBAC Roles
[bootstrap-token] configured RBAC rules to allow Node Bootstrap tokens to get nodes
[bootstrap-token] configured RBAC rules to allow Node Bootstrap tokens to post CSRs in order for nodes to get long term certificate credentials
[bootstrap-token] configured RBAC rules to allow the csrapprover controller automatically approve CSRs from a Node Bootstrap Token
[bootstrap-token] configured RBAC rules to allow certificate rotation for all node client certificates in the cluster
[bootstrap-token] Creating the "cluster-info" ConfigMap in the "kube-public" namespace
[kubelet-finalize] Updating "/etc/kubernetes/kubelet.conf" to point to a rotatable kubelet client certificate and key
[addons] Applied essential addon: CoreDNS
[addons] Applied essential addon: kube-proxy
Your Kubernetes control-plane has initialized successfully!
To start using your cluster, you need to run the following as a regular user:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
You should now deploy a pod network to the cluster.
Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at:
https://kubernetes.io/docs/concepts/cluster-administration/addons/
Then you can join any number of worker nodes by running the following on each as root:
kubeadm join 192.168.128.82:6443 --token lm15t2.xxkc4z99tcfmwb7c \
--discovery-token-ca-cert-hash sha256:d16143d499bc5c16eadaa7641dfe43761ab9411b82d11354b67a30fa0356e9ca
其中最后8段话,是提示:
Your Kubernetes control-plane has initialized successfully!
To start using your cluster, you need to run the following as a regular user:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
You should now deploy a pod network to the cluster.
Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at:
https://kubernetes.io/docs/concepts/cluster-administration/addons/
Then you can join any number of worker nodes by running the following on each as root:
kubeadm join 192.168.128.82:6443 --token lm15t2.xxkc4z99tcfmwb7c \
--discovery-token-ca-cert-hash sha256:d16143d499bc5c16eadaa7641dfe43761ab9411b82d11354b67a30fa0356e9ca kubeadm提示你,其他节点需要加入集群的话,只需要执行最后这条命令就行了,里面包含了加入集群所需要的token。同时kubeadm还提醒你,要完成全部安装,还需要安装一个网络插件kubectl apply -f [podnetwork].yaml,并且连如何安装网络插件的网址都提供给你了(很贴心啊有木有)。同时也提示你,需要执行
mkdir -p $HOME/.kube sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config sudo chown $(id -u):$(id -g) $HOME/.kube/config而需要这些配置命令的原因是:Kubernetes 集群默认需要加密方式访问。所以,这几条命令,就是将刚刚部署生成的 Kubernetes 集群的安全配置文件,保存到当前用户的.kube 目录下,kubectl 默认会使用这个目录下的授权信息访问 Kubernetes 集群。
如果不这么做的话,我们每次都需要通过 export KUBECONFIG 环境变量告诉 kubectl 这个安全配置文件的位置。
注:如其他node节点的话需要将此配置信息拷贝入node节点的对应目录。
#按上面提示执行:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
#上面工作做完之后,可以重启kubelet了
systemctl start kubelet
systemctl status kubelet
#执行一下下面命令,看是否生效
#查看pod情况
[root@vm82 ~]# kubectl get pods -n kube-system
NAME READY STATUS RESTARTS AGE
coredns-66bff467f8-bnrdz 0/1 Pending 0 103s
coredns-66bff467f8-zf4nb 0/1 Pending 0 103s
etcd-vm82 1/1 Running 0 117s
kube-apiserver-vm82 1/1 Running 0 117s
kube-controller-manager-vm82 1/1 Running 0 117s
kube-proxy-kvdhj 1/1 Running 0 102s
kube-scheduler-vm82 1/1 Running 0 117s
3.1.3 kubeadm ini大概流程
1.当你执行 kubeadm init 指令后,会进行检查,这一步检查,我们称为“Preflight Checks”,它可以为你省掉很多后续的麻烦。
2.在通过了 Preflight Checks 之后,kubeadm 要为你做的,是生成 Kubernetes 对外提供服务所需的各种证书和对应的目录。
kubeadm 为 Kubernetes 项目生成的证书文件都放在 Master 节点的 /etc/kubernetes/pki 目录下。在这个目录下,最主要的证书文件是 ca.crt 和对应的私钥 ca.key。
3. 证书生成后,kubeadm 接下来会为其他组件生成访问 kube-apiserver 所需的配置文件
#这些文件的路径是:/etc/kubernetes/xxx.conf: [root@vm82 ~]# ls /etc/kubernetes/ admin.conf controller-manager.conf kubelet.conf manifests pki scheduler.conf4.kubeadm 会为 Master 组件生成 Pod 配置文件。 Kubernetes 有三个 Master 组件 kube-apiserver、kube-controller-manager、kube-scheduler,而它们都会被使用 Pod 的方式部署起来。
在 kubeadm 中,Master 组件的 YAML 文件会被生成在 /etc/kubernetes/manifests 路径下。
5.kubeadm 就会为集群生成一个 bootstrap token。在后面,只要持有这个 token,任何一个安装了 kubelet 和 kubadm 的节点,都可以通过 kubeadm join 加入到这个集群当中。
这个 token 的值和使用方法会,会在 kubeadm init 结束后被打印出来。
6.在 token 生成之后,kubeadm 会将 ca.crt 等 Master 节点的重要信息,通过 ConfigMap 的方式保存在 Etcd 当中,供后续部署 Node 节点使用。这个 ConfigMap 的名字是 cluster-info。
7. kubeadm init 的最后一步,就是安装默认插件
3.2安装容器网络插件
所有插件都是在master节点上安装,它会自动推送到node节点上安装,如需要会连接上master
3.2.1 查看节点状态
#执行 kubectl get node 命令可以查看nodes信息,如下:
[root@vm82 ~]# kubectl get node
NAME STATUS ROLES AGE VERSION
vm82 NotReady master 2m47s v1.18.5
可以看到,这个 get 指令输出的结果里,Master 节点的状态是 NotReady,这是为什么呢?
在调试 Kubernetes 集群时,最重要的手段就是用 kubectl describe 来查看这个节点(Node)对象的详细信息、状态和事件(Event),我们来试一下:
[root@vm82 ~]# kubectl describe node vm82
Name: vm82
Roles: master
Labels: beta.kubernetes.io/arch=amd64
beta.kubernetes.io/os=linux
kubernetes.io/arch=amd64
kubernetes.io/hostname=vm82
kubernetes.io/os=linux
node-role.kubernetes.io/master=
Annotations: kubeadm.alpha.kubernetes.io/cri-socket: /var/run/dockershim.sock
node.alpha.kubernetes.io/ttl: 0
volumes.kubernetes.io/controller-managed-attach-detach: true
CreationTimestamp: Sat, 11 Jul 2020 23:47:34 +0800
Taints: node-role.kubernetes.io/master:NoSchedule
node.kubernetes.io/not-ready:NoSchedule
Unschedulable: false
Lease:
HolderIdentity: vm82
AcquireTime:
RenewTime: Sun, 12 Jul 2020 00:01:23 +0800
Conditions:
Type Status LastHeartbeatTime LastTransitionTime Reason Message
---- ------ ----------------- ------------------ ------ -------
MemoryPressure False Sat, 11 Jul 2020 23:56:55 +0800 Sat, 11 Jul 2020 23:47:32 +0800 KubeletHasSufficientMemory kubelet has sufficient memory available
DiskPressure False Sat, 11 Jul 2020 23:56:55 +0800 Sat, 11 Jul 2020 23:47:32 +0800 KubeletHasNoDiskPressure kubelet has no disk pressure
PIDPressure False Sat, 11 Jul 2020 23:56:55 +0800 Sat, 11 Jul 2020 23:47:32 +0800 KubeletHasSufficientPID kubelet has sufficient PID available
Ready False Sat, 11 Jul 2020 23:56:55 +0800 Sat, 11 Jul 2020 23:47:32 +0800 KubeletNotReady runtime network not ready: NetworkReady=false reason:NetworkPluginNotReady message:docker: network plugin is not ready: cni config uninitialized
Addresses:
InternalIP: 192.168.3.82
Hostname: vm82
Capacity:
cpu: 4
ephemeral-storage: 49794300Ki
hugepages-2Mi: 0
memory: 2336688Ki
pods: 110
Allocatable:
cpu: 4
ephemeral-storage: 45890426805
hugepages-2Mi: 0
memory: 2234288Ki
pods: 110
System Info:
Machine ID: c959e989d2124fc397bea1330baa9d8f
System UUID: 564d1ed1-542b-1505-c802-6141726fac60
Boot ID: ba7c83d4-ec61-480c-9e4c-3dae00748865
Kernel Version: 4.18.0-193.el8.x86_64
OS Image: CentOS Linux 8 (Core)
Operating System: linux
Architecture: amd64
Container Runtime Version: docker://19.3.12
Kubelet Version: v1.18.5
Kube-Proxy Version: v1.18.5
PodCIDR: 172.168.0.0/24
PodCIDRs: 172.168.0.0/24
Non-terminated Pods: (5 in total)
Namespace Name CPU Requests CPU Limits Memory Requests Memory Limits AGE
--------- ---- ------------ ---------- --------------- ------------- ---
kube-system etcd-vm82 0 (0%) 0 (0%) 0 (0%) 0 (0%) 13m
kube-system kube-apiserver-vm82 250m (6%) 0 (0%) 0 (0%) 0 (0%) 13m
kube-system kube-controller-manager-vm82 200m (5%) 0 (0%) 0 (0%) 0 (0%) 13m
kube-system kube-proxy-kvdhj 0 (0%) 0 (0%) 0 (0%) 0 (0%) 13m
kube-system kube-scheduler-vm82 100m (2%) 0 (0%) 0 (0%) 0 (0%) 13m
Allocated resources:
(Total limits may be over 100 percent, i.e., overcommitted.)
Resource Requests Limits
-------- -------- ------
cpu 550m (13%) 0 (0%)
memory 0 (0%) 0 (0%)
ephemeral-storage 0 (0%) 0 (0%)
hugepages-2Mi 0 (0%) 0 (0%)
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Starting 13m kubelet, vm82 Starting kubelet.
Normal NodeHasSufficientMemory 13m kubelet, vm82 Node vm82 status is now: NodeHasSufficientMemory
Normal NodeHasNoDiskPressure 13m kubelet, vm82 Node vm82 status is now: NodeHasNoDiskPressure
Normal NodeHasSufficientPID 13m kubelet, vm82 Node vm82 status is now: NodeHasSufficientPID
Normal NodeAllocatableEnforced 13m kubelet, vm82 Updated Node Allocatable limit across pods
Normal Starting 13m kube-proxy, vm82 Starting kube-proxy. 其中一句:
work not ready: NetworkReady=false reason:NetworkPluginNotReady message:docker: network plugin is not ready: cni config uninitialized
通过 kubectl describe 指令的输出,我们可以看到 NodeNotReady 的原因在于,我们尚未部署任何网络插件。
我们还可以通过 kubectl 检查这个节点上各个系统 Pod 的状态,其中,kube-system 是 Kubernetes 项目预留的系统 Pod 的工作空间(Namepsace,注意它并不是 Linux Namespace,它只是 Kubernetes 划分不同工作空间的单位):
#-n 后跟 namespace,查看指定的命名空间
[root@vm82 ~]# kubectl get pods -n kube-system
NAME READY STATUS RESTARTS AGE
coredns-66bff467f8-bnrdz 0/1 Pending 0 15m
coredns-66bff467f8-zf4nb 0/1 Pending 0 15m
etcd-vm82 1/1 Running 0 15m
kube-apiserver-vm82 1/1 Running 0 15m
kube-controller-manager-vm82 1/1 Running 0 15m
kube-proxy-kvdhj 1/1 Running 0 15m
kube-scheduler-vm82 1/1 Running 0 15m
可以看到,CoreDNS等依赖于网络的 Pod 都处于 Pending 状态,即调度失败,kube-controller-manager 更是直接CrashLoopBackOff了,这当然是符合预期的:因为这个 Master 节点的网络尚未就绪。
#weave-kube说明文档,安装如下:
[root@vm82 ~]# kubectl apply -f "https://cloud.weave.works/k8s/net?k8s-version=$(kubectl version | base64 | tr -d '\n')"
serviceaccount/weave-net created
clusterrole.rbac.authorization.k8s.io/weave-net created
clusterrolebinding.rbac.authorization.k8s.io/weave-net created
role.rbac.authorization.k8s.io/weave-net created
rolebinding.rbac.authorization.k8s.io/weave-net created
daemonset.apps/weave-net created
[root@vm82 ~]# #过一会查看一下,如果不行的话,再执行多一次
[root@vm82 ~]# kubectl get pods --all-namespaces -l name=weave-net
NAMESPACE NAME READY STATUS RESTARTS AGE
kube-system weave-net-ls6k5 0/2 ContainerCreating 0 9s注:如果上面的weave-net-vh4sx一直处理 ContainerCreating,则可以查看一下日志输出,看理什么问题,其中-c表示容器的名字可以通过 docker images 命令查看
kubectl -n kube-system logs -f weave-net-vh4sx -c weave-npc
#如果是master内存2G的话会很慢,估计要七八分钟
[root@vm82 ~]# kubectl get pods -n kube-system
NAME READY STATUS RESTARTS AGE
coredns-66bff467f8-bnrdz 1/1 Running 0 17m
coredns-66bff467f8-zf4nb 0/1 Running 0 17m
etcd-vm82 1/1 Running 0 17m
kube-apiserver-vm82 1/1 Running 0 17m
kube-controller-manager-vm82 1/1 Running 0 17m
kube-proxy-kvdhj 1/1 Running 0 17m
kube-scheduler-vm82 1/1 Running 0 17m
weave-net-ls6k5 2/2 Running 0 81s
[root@vm82 ~]#
[root@vm82 ~]#
[root@vm82 ~]# kubectl get pods -n kube-system
NAME READY STATUS RESTARTS AGE
coredns-66bff467f8-bnrdz 1/1 Running 0 19m
coredns-66bff467f8-zf4nb 1/1 Running 0 19m
etcd-vm82 1/1 Running 0 19m
kube-apiserver-vm82 1/1 Running 0 19m
kube-controller-manager-vm82 1/1 Running 0 19m
kube-proxy-kvdhj 1/1 Running 0 19m
kube-scheduler-vm82 1/1 Running 0 19m
weave-net-ls6k5 2/2 Running 0 2m51s
发现上面都是 Running了,表示安装成功
3.3安装DashBoard插件
3.3.1 安装
见DashBoard官网说明,k8项目提供了一个官方的dashboard,虽然平时还是命令行用的多,但是有个UI总是好的,我们来看看怎么安装。安装其实也是非常简单,标准的k8声明式安装
#先安装docker镜像,因为国外,你懂的,
#从github DashBoard安装说明知配置文件
kubectl apply -f https://raw.githubusercontent.com/kubernetes/dashboard/v2.0.3/aio/deploy/recommended.yaml又不能访问了,需要hosts绑定 绑定hosts
通过 https://www.ipaddress.com/ 查询到
raw.githubusercontent.com的真实 IP 地址:
[root@vm82 ~]# echo '199.232.68.133 raw.githubusercontent.com' >> /etc/hosts [root@vm82 ~]# tail -1 /etc/hosts 199.232.68.133 raw.githubusercontent.co
[root@vm82 ~]# kubectl apply -f https://raw.githubusercontent.com/kubernetes/dashboard/v2.0.3/aio/deploy/recommended.yaml
namespace/kubernetes-dashboard created
serviceaccount/kubernetes-dashboard created
service/kubernetes-dashboard created
secret/kubernetes-dashboard-certs created
secret/kubernetes-dashboard-csrf created
secret/kubernetes-dashboard-key-holder created
configmap/kubernetes-dashboard-settings created
role.rbac.authorization.k8s.io/kubernetes-dashboard created
clusterrole.rbac.authorization.k8s.io/kubernetes-dashboard created
rolebinding.rbac.authorization.k8s.io/kubernetes-dashboard created
clusterrolebinding.rbac.authorization.k8s.io/kubernetes-dashboard created
deployment.apps/kubernetes-dashboard created
service/dashboard-metrics-scraper created
deployment.apps/dashboard-metrics-scraper created
#过一会查看是否安装成功
[root@vm82 ~]# kubectl get po --all-namespaces|grep dashboard
kubernetes-dashboard dashboard-metrics-scraper-6b4884c9d5-nt4tc 1/1 Running 0 1m32s
kubernetes-dashboard kubernetes-dashboard-7f99b75bf4-d5tx2 1/1 Running 0 1m32s
需要注意的是,由于 Dashboard 是一个 Web Server,很多人经常会在自己的公有云上无意地暴露 Dashboard 的端口,从而造成安全隐患。所以,1.7 版本之后的 Dashboard 项目部署完成后,默认只能通过 Proxy 的方式在本地访问。具体的操作,你可以查看 Dashboard 项目的官方文档
3.3.2 配置
#1 修改node为NodePort模式
[root@vm82 ~]# kubectl patch svc -n kubernetes-dashboard kubernetes-dashboard -p '{"spec":{"type":"NodePort"}}'
service/kubernetes-dashboard patched
#查看服务 svc是service是缩写
[root@vm82 ~]# kubectl get svc -n kubernetes-dashboard
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
dashboard-metrics-scraper ClusterIP 10.97.204.134 8000/TCP 11m
kubernetes-dashboard NodePort 10.108.22.8 443:30107/TCP 11m
发现内部使用的是443即https,外部使用30107端口,用火狐浏览器输入https://192.168.3.82:30107

输入刚刚初始化生成的token,我的这里是lm15t2.xxkc4z99tcfmwb7c
kubeadm join 192.168.128.82:6443 --token lm15t2.xxkc4z99tcfmwb7c \
--discovery-token-ca-cert-hash sha256:d16143d499bc5c16eadaa7641dfe43761ab9411b82d11354b67a30fa0356e9ca 

#2. 创建dashboard管理用户及token
# 创建dashboard管理用户
kubectl create serviceaccount dashboard-admin -n kubernetes-dashboard
# 绑定用户为集群管理用户
kubectl create clusterrolebinding dashboard-cluster-admin --clusterrole=cluster-admin \
--serviceaccount=kubernetes-dashboard:dashboard-admin
[root@vm82 ~]# # 生成tocken
[root@vm82 ~]# kubectl describe secret -n kubernetes-dashboard dashboard-admin-token
Name: dashboard-admin-token-fnwrp
Namespace: kubernetes-dashboard
Labels:
Annotations: kubernetes.io/service-account.name: dashboard-admin
kubernetes.io/service-account.uid: c1cef7dc-a194-4030-b311-fb8e317e9879
Type: kubernetes.io/service-account-token
Data
====
ca.crt: 1025 bytes
namespace: 20 bytes
token: eyJhbGciOiJSUzI1NiIsImtpZCI6Im4xLUJhbFIxQmtmUS1SNnhvTmhaTEJnZW1ub2VTS0NzZzZYNVU2aDUzNjgifQ.eyJpc3MiOiJrdWJlcm5ldGVzL3NlcnZpY2VhY2NvdW50Iiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9uYW1lc3BhY2UiOiJrdWJlcm5ldGVzLWRhc2hib2FyZCIsImt1YmVybmV0ZXMuaW8vc2VydmljZWFjY291bnQvc2VjcmV0Lm5hbWUiOiJkYXNoYm9hcmQtYWRtaW4tdG9rZW4tZm53cnAiLCJrdWJlcm5ldGVzLmlvL3NlcnZpY2VhY2NvdW50L3NlcnZpY2UtYWNjb3VudC5uYW1lIjoiZGFzaGJvYXJkLWFkbWluIiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9zZXJ2aWNlLWFjY291bnQudWlkIjoiYzFjZWY3ZGMtYTE5NC00MDMwLWIzMTEtZmI4ZTMxN2U5ODc5Iiwic3ViIjoic3lzdGVtOnNlcnZpY2VhY2NvdW50Omt1YmVybmV0ZXMtZGFzaGJvYXJkOmRhc2hib2FyZC1hZG1pbiJ9.a9X0pmqveYMOzQgXs0P7HsIb02EDtDCYLNa0sg7z0bLaZbGnM-3sCGo1ZmDlFA5vdRavi1ySJtd4u1883dRKsI5C9Bikvx0lLc2iJcyC4ZU-Ns4TjnQcVkw6agcrpdZMrY9te5ukR5djCH3vbuuDKTrp5KHH9mBQRAHOxVoJEAG5oJ68wu6DZmkyje8xyZuVIFTTKPgr-01itPgzu-1G5E1DymLtIZ2Xbzp8JvZja1kdXQamvXMV07m_TaF98OpQky2mWTeXAV3zYoXyJaDca-l-fTOmqSp9RuQsPJJqeb2_H7yHP4fgZ0I031fr-y3HQhSgKjvP9F3uUb2QzfNm1Q
#3. 登陆web管理页面
退出web,改用上面生成的token到再次登录
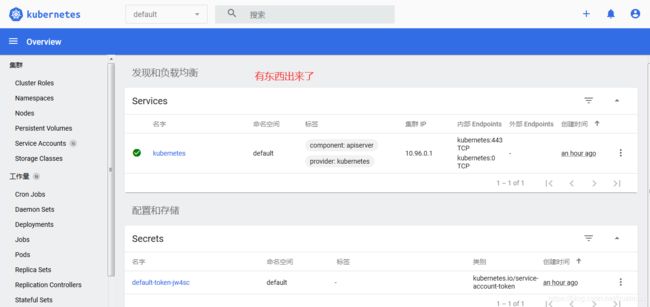
四、创建node节点并加入master中(node)
将一个 Node 节点加入到当前集群中的命令如下:
#将一个 Node 节点加入到当前集群中的命令如下:
kubeadm join --token : --discovery-token-ca-cert-hash sha256:
4.1 kubeadm join 的工作流程
这个流程其实非常简单,kubeadm init 生成 bootstrap token 之后,你就可以在任意一台安装了 kubelet 和 kubeadm 的机器上执行 kubeadm join 了。
任何一台机器想要成为 Kubernetes 集群中的一个节点,就必须在集群的 kube-apiserver 上注册。可是,要想跟 apiserver 打交道,这台机器就必须要获取到相应的证书文件(CA 文件)。可是,为了能够一键安装,我们就不能让用户去 Master 节点上手动拷贝这些文件。
所以,kubeadm 至少需要发起一次“不安全模式”的访问到 kube-apiserver,从而拿到保存在 ConfigMap 中的 cluster-info(它保存了 APIServer 的授权信息)。而 bootstrap token,扮演的就是这个过程中的安全验证的角色。
只要有了 cluster-info 里的 kube-apiserver 的地址、端口、证书,kubelet 就可以以“安全模式”连接到 apiserver 上,这样一个新的节点就部署完成了。
你只要在其他节点上重复这个指令就可以了
4.2 kubeadm安装
上面已经进了kubeadm安装了
还需要安装一些基础组件
#使用脚本自动安装,node节点只需要kubelet、kube-proxy即可
cat>kubeadm_config_images_list.sh<#执行之后,看一下7个镜像是否下载完整了
4.3 加入集群
#复制master中执行kubeadm init生成的kubeadm join命令即可以加入master节点中,
#在node节点执行此命令,我这里是192.168.3.21和192.168.3.22,我先添加3.21试下
kubeadm join 192.168.128.82:6443 --token lm15t2.xxkc4z99tcfmwb7c \
--discovery-token-ca-cert-hash sha256:d16143d499bc5c16eadaa7641dfe43761ab9411b82d11354b67a30fa0356e9ca注:如果kubeadm join有问题,想再次执行上面命令,得先 kubeadm reset ,最好在master上执行删除操作
kubectl delete node vm821
#发现超时
[root@vm821 ~]# kubeadm join 192.168.128.82:6443 --token lm15t2.xxkc4z99tcfmwb7c \
> --discovery-token-ca-cert-hash sha256:d16143d499bc5c16eadaa7641dfe43761ab9411b82d11354b67a30fa0356e9ca
W0712 03:52:36.056333 1614 join.go:346] [preflight] WARNING: JoinControlPane.controlPlane settings will be ignored when control-plane flag is not set.
[preflight] Running pre-flight checks
[WARNING IsDockerSystemdCheck]: detected "cgroupfs" as the Docker cgroup driver. The recommended driver is "systemd". Please follow the guide at https://kubernetes.io/docs/setup/cri/
[WARNING FileExisting-tc]: tc not found in system path
[preflight] Reading configuration from the cluster...
[preflight] FYI: You can look at this config file with 'kubectl -n kube-system get cm kubeadm-config -oyaml'
[kubelet-start] Downloading configuration for the kubelet from the "kubelet-config-1.18" ConfigMap in the kube-system namespace
[kubelet-start] Writing kubelet configuration to file "/var/lib/kubelet/config.yaml"
[kubelet-start] Writing kubelet environment file with flags to file "/var/lib/kubelet/kubeadm-flags.env"
[kubelet-start] Starting the kubelet
[kubelet-start] Waiting for the kubelet to perform the TLS Bootstrap...
[kubelet-check] Initial timeout of 40s passed.
Unfortunately, an error has occurred:
timed out waiting for the condition
This error is likely caused by:
- The kubelet is not running
- The kubelet is unhealthy due to a misconfiguration of the node in some way (required cgroups disabled)
If you are on a systemd-powered system, you can try to troubleshoot the error with the following commands:
- 'systemctl status kubelet'
- 'journalctl -xeu kubelet'
error execution phase kubelet-start: timed out waiting for the condition
To see the stack trace of this error execute with --v=5 or higher
##解决方式先查看kubelet进程是否挂掉
systemctl status kubelet
#一旦重置因kubelet没有任何东西会启动不起来,属于正常现象,加入master再启动即可
kubeadm reset
#mster节点上删除相关节点
kubectl delete node vm821因为太卡,所以报上面的错,重置再试几次就好了
#如果不行就试多几次先kubeadm reset,再在master上删除相关节点 kubectl delete node vm821
[root@vm821 ~]# kubeadm join 192.168.128.82:6443 --token lm15t2.xxkc4z99tcfmwb7c \
> --discovery-token-ca-cert-hash sha256:d16143d499bc5c16eadaa7641dfe43761ab9411b82d11354b67a30fa0356e9ca
W0712 04:13:20.860144 6489 join.go:346] [preflight] WARNING: JoinControlPane.controlPlane settings will be ignored when control-plane flag is not set.
[preflight] Running pre-flight checks
[WARNING IsDockerSystemdCheck]: detected "cgroupfs" as the Docker cgroup driver. The recommended driver is "systemd". Please follow the guide at https://kubernetes.io/docs/setup/cri/
[WARNING FileExisting-tc]: tc not found in system path
[preflight] Reading configuration from the cluster...
[preflight] FYI: You can look at this config file with 'kubectl -n kube-system get cm kubeadm-config -oyaml'
[kubelet-start] Downloading configuration for the kubelet from the "kubelet-config-1.18" ConfigMap in the kube-system namespace
[kubelet-start] Writing kubelet configuration to file "/var/lib/kubelet/config.yaml"
[kubelet-start] Writing kubelet environment file with flags to file "/var/lib/kubelet/kubeadm-flags.env"
[kubelet-start] Starting the kubelet
[kubelet-start] Waiting for the kubelet to perform the TLS Bootstrap...
[kubelet-check] Initial timeout of 40s passed.
This node has joined the cluster:
* Certificate signing request was sent to apiserver and a response was received.
* The Kubelet was informed of the new secure connection details.
Run 'kubectl get nodes' on the control-plane to see this node join the cluster.
#在master服务器上执行命令查看节点情况
[root@vm82 ~]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
vm82 Ready master 4h31m v1.18.5
vm821 NotReady 59s v1.18.5 用web登陆管理看一下,我这里是https://192.168.3.82:30107/

[root@vm821 ~]# docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
k8s.gcr.io/kube-proxy v1.18.5 a1daed4e2b60 2 weeks ago 117MB
weaveworks/weave-npc 2.6.5 420d4d5aac6f 4 weeks ago 36.8MB
weaveworks/weave-kube 2.6.5 e9dd2f85e51b 4 weeks ago 123MB
k8s.gcr.io/pause 3.2 80d28bedfe5d 4 months ago 683kB
其中:kube-proxy和pause是手工下载的,而网络插件镜像weaveworks/weave-npc weaveworks/weave-kube是master自动安装的
同理也把第2个node节点vm822加入master中,发现保持vm821的情况下再开vm822不行,如果挂起vm821再开vm822的话kube-controller-manage状态会变成CrashLoopBackOff,所以要保证至少有一个节点是可用的。
和上面一样,也是先手工安装pause和kube-proxy的docker镜像,然后执行kubeadm join命令加入master即可
cat>kubeadm_config_images_list.sh<#在另一个node节点上也执行join操作
kubeadm join 192.168.128.82:6443 --token lm15t2.xxkc4z99tcfmwb7c \
--discovery-token-ca-cert-hash sha256:d16143d499bc5c16eadaa7641dfe43761ab9411b82d11354b67a30fa0356e9ca
#加入之前先在master执行 kubectl get pod -n kube-system 看是否都是running
[root@vm82 ~]# kubectl get pod -n kube-system
NAME READY STATUS RESTARTS AGE
coredns-66bff467f8-bnrdz 1/1 Running 1 7h33m
coredns-66bff467f8-zf4nb 1/1 Running 1 7h33m
etcd-vm82 1/1 Running 1 7h34m
kube-apiserver-vm82 1/1 Running 3 7h34m
kube-controller-manager-vm82 1/1 Running 54 7h34m
kube-proxy-5qn2m 1/1 Running 0 4h5m
kube-proxy-kvdhj 1/1 Running 1 7h33m
kube-scheduler-vm82 1/1 Running 53 7h34m
weave-net-gpmqx 2/2 Running 0 4h5m
weave-net-ls6k5 2/2 Running 3 7h17m
#在master运行,至少要有一个节点正常运行,所以vm821这个节点不能关闭
[root@vm822 ~]# kubeadm join 192.168.128.82:6443 --token lm15t2.xxkc4z99tcfmwb7c \
> --discovery-token-ca-cert-hash sha256:d16143d499bc5c16eadaa7641dfe43761ab9411b82d11354b67a30fa0356e9ca
W0712 07:23:58.850286 1832 join.go:346] [preflight] WARNING: JoinControlPane.controlPlane settings will be ignored when control-plane flag is not set.
[preflight] Running pre-flight checks
[WARNING IsDockerSystemdCheck]: detected "cgroupfs" as the Docker cgroup driver. The recommended driver is "systemd". Please follow the guide at https://kubernetes.io/docs/setup/cri/
[WARNING FileExisting-tc]: tc not found in system path
[preflight] Reading configuration from the cluster...
[preflight] FYI: You can look at this config file with 'kubectl -n kube-system get cm kubeadm-config -oyaml'
[kubelet-start] Downloading configuration for the kubelet from the "kubelet-config-1.18" ConfigMap in the kube-system namespace
[kubelet-start] Writing kubelet configuration to file "/var/lib/kubelet/config.yaml"
[kubelet-start] Writing kubelet environment file with flags to file "/var/lib/kubelet/kubeadm-flags.env"
[kubelet-start] Starting the kubelet
[kubelet-start] Waiting for the kubelet to perform the TLS Bootstrap...
This node has joined the cluster:
* Certificate signing request was sent to apiserver and a response was received.
* The Kubelet was informed of the new secure connection details.
Run 'kubectl get nodes' on the control-plane to see this node join the cluster.
[root@vm822 ~]#
#在master节点上查看一下节点,如下所示
[root@vm82 ceph]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
vm82 Ready master 7h46m v1.18.5
vm821 Ready 3h16m v1.18.5
vm822 Ready 9m41s v1.18.5
从web上也能正常运行

五、 安装容器存储插件Rook(可选 )
因为rook插件是运行非主节点的,至少要有一个node节点情况下安装才行,在这里我主要是使用到它的ceph
5.1 Rook介绍
很多时候我们需要用数据卷(Volume)把外面宿主机上的目录或者文件挂载进容器的 Mount Namespace 中,从而达到容器和宿主机共享这些目录或者文件的目的。容器里的应用,也就可以在这些数据卷中新建和写入文件。
可是,如果你在某一台机器上启动的一个容器,显然无法看到其他机器上的容器在它们的数据卷里写入的文件。这是容器最典型的特征之一:无状态。
而容器的持久化存储,就是用来保存容器存储状态的重要手段:存储插件会在容器里挂载一个基于网络或者其他机制的远程数据卷,使得在容器里创建的文件,实际上是保存在远程存储服务器上,或者以分布式的方式保存在多个节点上,而与当前宿主机没有任何绑定关系。这样,无论你在其他哪个宿主机上启动新的容器,都可以请求挂载指定的持久化存储卷,从而访问到数据卷里保存的内容。这就是“持久化”的含义。
由于 Kubernetes 本身的松耦合设计,绝大多数存储项目,比如 Ceph、GlusterFS、NFS 等,都可以为 Kubernetes 提供持久化存储能力。在这次的部署实战中,我会选择部署一个很重要的 Kubernetes 存储插件项目:Rook。
Rook 项目是一个基于 Ceph 的 Kubernetes 存储插件(它后期也在加入对更多存储实现的支持)。不过,不同于对 Ceph 的简单封装,Rook 在自己的实现中加入了水平扩展、迁移、灾难备份、监控等大量的企业级功能,使得这个项目变成了一个完整的、生产级别可用的容器存储插件。
5.2 为什么我要选择 Rook 项目呢
是因为这个项目很有前途
如果你去研究一下 Rook 项目的实现,就会发现它巧妙地依赖了 Kubernetes 提供的编排能力,合理的使用了很多诸如 Operator、CRD 等重要的扩展特性(这些特性我都会在后面的文章中逐一讲解到)。这使得 Rook 项目,成为了目前社区中基于 Kubernetes API 构建的最完善也最成熟的容器存储插件。我相信,这样的发展路线,很快就会得到整个社区的推崇。
备注:
其实,在很多时候,大家说的所谓“云原生”,就是“Kubernetes 原生”的意思。而像 Rook、Istio 这样的项目,正是贯彻这个思路的典范。在后面学到声明式 API 之后,相信你对这些项目的设计思想会有更深刻的体会。
5.3 安装 Rook-ceph
在安装前根据rook ceph说明文档要求
o make sure you have a Kubernetes cluster that is ready for
Rook, you can follow these instructions.In order to configure the Ceph storage cluster, at least one of these local storage options are required:
- Raw devices (no partitions or formatted filesystems)
- Raw partitions (no formatted filesystem)
- PVs available from a storage class in
blockmode
所以我选择第1个,在node上添加一个新硬盘,大小100G
因为这个rook-ceph群集安装东西太多了,所以我把node内存调大些,2.5G或更大2.8G
5.3.1 安装common.yaml 和operator.yaml
我这里以最火和rook-ceph为例子你,打开rook-ceph说明文档,我选择目前最新版本v1.3

- cluster.yaml: Cluster settings for a production cluster running on bare metal
- cluster-on-pvc.yaml: Cluster settings for a production cluster running in a dynamic cloud environment
- cluster-test.yaml: Cluster settings for a test environment such as minikube.
按照上面提示执行,在执行之前需要绑定hosts,github是国外的网站,你懂的,我用站长工具DNS查询查看一下有哪些ips可用
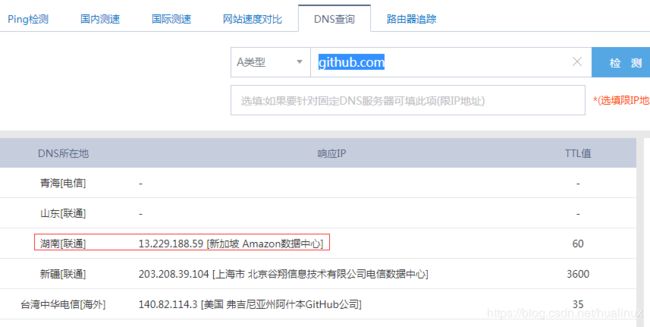
#绑定hosts
echo '13.229.188.59 github.com' >> /etc/hosts
#安装git
yum install git -y
#建立相关目录
mkdir -pv /disk1/tools
cd /disk1/tools/
#git克隆一份下来
git clone --single-branch --branch release-1.3 https://github.com/rook/rook.git
#执行相关的yaml文件,这里我使用aplly
cd rook/cluster/examples/kubernetes/ceph/
kubectl apply -f common.yaml
kubectl apply -f operator.yaml
PS:git慢的话可以直接去rook的github官网下载 zip包了
下载的zip包为rook-release-1.3.zip
#把它上传到/etc/kubernetes/中再解压
yum install unzip -y unzip rook-release-1.3.zip cd rook-release-1.3/cluster/examples/kubernetes/ceph/ #我这里使用apply 代替create,好用些,有兴趣的可以查一下区别 kubectl apply -f common.yaml kubectl apply -f operator.yaml

ps2:
#如果没有node节点,执行 get pod -n rook-ceph 会一直Pending,如下图所示:
[root@vm82 ceph]# kubectl get pod -n rook-ceph NAME READY STATUS RESTARTS AGE rook-ceph-operator-db86d47f5-v9n9j 0/1 Pending 0 12m
5.3.2 查看相关状态
用web登陆图形管理界面,我这是https://192.168.3.82:30107,点看一下命名空间
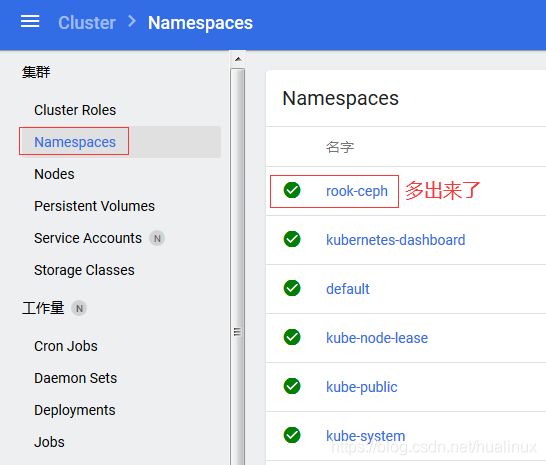


我这里用命令看一下
kubectl get pod -n rook-ceph
kubectl get pod -n rook-ceph -o wide#查看详细描述
kubectl describe pods -n rook-ceph
[root@vm82 ceph]# kubectl get pod -n rook-ceph
NAME READY STATUS RESTARTS AGE
rook-ceph-operator-5ff5c45d49-xppkj 0/1 ContainerCreating 0 5m25s
[root@vm82 ceph]# 查看一下命名空间的pod,状态表示 容器在创建中
[root@vm82 ceph]# kubectl get pod -n rook-ceph -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
rook-ceph-operator-5ff5c45d49-xppkj 0/1 ContainerCreating 0 5m27s vm821
[root@vm82 ceph]# kubectl describe pods -n rook-ceph
Name: rook-ceph-operator-5ff5c45d49-xppkj
Namespace: rook-ceph
Priority: 0
Node: vm821/192.168.3.21
Start Time: Mon, 13 Jul 2020 00:42:17 +0800
Labels: app=rook-ceph-operator
pod-template-hash=5ff5c45d49
Annotations:
Status: Pending
IP:
IPs:
Controlled By: ReplicaSet/rook-ceph-operator-5ff5c45d49
Containers:
rook-ceph-operator:
Container ID:
Image: rook/ceph:v1.3.7
Image ID:
Port:
Host Port:
Args:
ceph
operator
State: Waiting
Reason: ContainerCreating
Ready: False
Restart Count: 0
Environment:
ROOK_CURRENT_NAMESPACE_ONLY: false
ROOK_ALLOW_MULTIPLE_FILESYSTEMS: false
ROOK_LOG_LEVEL: INFO
ROOK_CEPH_STATUS_CHECK_INTERVAL: 60s
ROOK_MON_HEALTHCHECK_INTERVAL: 45s
ROOK_MON_OUT_TIMEOUT: 600s
ROOK_DISCOVER_DEVICES_INTERVAL: 60m
ROOK_HOSTPATH_REQUIRES_PRIVILEGED: false
ROOK_ENABLE_SELINUX_RELABELING: true
ROOK_ENABLE_FSGROUP: true
ROOK_DISABLE_DEVICE_HOTPLUG: false
DISCOVER_DAEMON_UDEV_BLACKLIST: (?i)dm-[0-9]+,(?i)rbd[0-9]+,(?i)nbd[0-9]+
ROOK_ENABLE_FLEX_DRIVER: false
ROOK_ENABLE_DISCOVERY_DAEMON: true
ROOK_UNREACHABLE_NODE_TOLERATION_SECONDS: 5
NODE_NAME: (v1:spec.nodeName)
POD_NAME: rook-ceph-operator-5ff5c45d49-xppkj (v1:metadata.name)
POD_NAMESPACE: rook-ceph (v1:metadata.namespace)
Mounts:
/etc/ceph from default-config-dir (rw)
/var/lib/rook from rook-config (rw)
/var/run/secrets/kubernetes.io/serviceaccount from rook-ceph-system-token-4282p (ro)
Conditions:
Type Status
Initialized True
Ready False
ContainersReady False
PodScheduled True
Volumes:
rook-config:
Type: EmptyDir (a temporary directory that shares a pod's lifetime)
Medium:
SizeLimit:
default-config-dir:
Type: EmptyDir (a temporary directory that shares a pod's lifetime)
Medium:
SizeLimit:
rook-ceph-system-token-4282p:
Type: Secret (a volume populated by a Secret)
SecretName: rook-ceph-system-token-4282p
Optional: false
QoS Class: BestEffort
Node-Selectors:
Tolerations: node.kubernetes.io/not-ready:NoExecute for 300s
node.kubernetes.io/unreachable:NoExecute for 300s
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled default-scheduler Successfully assigned rook-ceph/rook-ceph-operator-5ff5c45d49-xppkj to vm821
Normal Pulling 5m34s kubelet, vm821 Pulling image "rook/ceph:v1.3.7"
[root@vm82 ceph]# 上面的 Pulling image 表示正在下载镜像
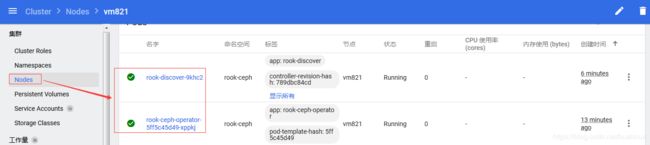
上面表示容器在创建中,这个镜像有点大883M,所以要点时间下载 ,过一会儿再执行,发现正常在了
[root@vm82 ceph]# kubectl get pod -n rook-ceph -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
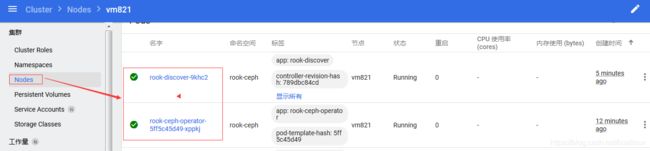
rook-ceph-operator-5ff5c45d49-xppkj 1/1 Running 0 11m 10.44.0.1 vm821
rook-discover-9khc2 1/1 Running 0 4m14s 10.44.0.2 vm821
再看一下web的,也正常了
5.3.3 创建群集
在上面的目录中继续创建群集
[root@vm82 ceph]# kubectl apply -f cluster.yaml
cephcluster.ceph.rook.io/rook-ceph created
[root@vm82 ceph]# cd ~会开始安装一堆东西,在web中看到节点又在安装东西了,慢慢等吧

用命令查看
[root@vm82 ~]# kubectl get pod -n rook-ceph -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
rook-ceph-csi-detect-version-wh9bf 0/1 PodInitializing 0 3m27s 10.44.0.3 vm821
rook-ceph-detect-version-7l8vj 0/1 PodInitializing 0 3m19s 10.44.0.4 vm821
rook-ceph-operator-5ff5c45d49-xppkj 1/1 Running 0 21m 10.44.0.1 vm821
rook-discover-9khc2 1/1 Running 0 14m 10.44.0.2 vm821
过一会,按F5刷新页面,发现web界面有变化了

看来又是国地址,导致,只能手工下载镜像了,去hub.docker.com搜索一下 quay.io/cephcsi/cephcsi
docker pull quay.mirrors.ustc.edu.cn/cephcsi/cephcsi:v2.1.2
PS:使用中科大镜像
如果我们拉取的quay.io镜像是以下形式:
docker pull quay.io/xxx/yyy:zzz
那么使用中科大镜像,应该是这样拉取:
docker pull quay.mirrors.ustc.edu.cn/xxx/yyy:zzz
ps2:也可以尝试下面的
### quay.io 地址替换
将 quay.io 替换为 quay-mirror.qiniu.com
### gcr.io 地址替换
将 gcr.io 替换为 registry.aliyuncs.com
经过2个多小时的等待, 安装了一堆东西,东西太多,内存太少,期间master挂了,我就不再演示了,因上面有一个报错,还需要重新执行一下
kubectl apply -f cluster.yaml其实如果实验的话,我们安装网络插件和DashBoard仪表板插件就行了,当你机子多,内存够可以弄一下这个存储插件。
