Druid大数据实时处理的开源分布式系统——Historical Node
最近开始整理有关Druid的技术知识。以下是第二篇关于Historical Node。
Historical 主要完成如下功能:
1. Loading and ServingSegments
2. Loading and ServingSegments From Cache
Historical Node的职责单一,就是负责加载Druid中非实时窗口内且满足加载规则的所有历史数据的Segment。每一个Historical Node只与Zookeeper保持同步,不与其他类型节点或者其他Historical Node进行通信。
Coordinator Nodes会定期(默认为1分钟)去同步元信息库,感知新生成的Segment,将待加载的Segment信息保存在Zookeeper中在线的Historical Nodes的load queue目录下,当Historical Node感知到需要加载新的Segment时,首先会去本地磁盘目录下查找该Segment是否已下载,如果没有,则会从Zookeeper中下载待加载Segment的元信息,此元信息包括Segment存储在何处、如何解压以及如何如理该Segment。Historical Node使用内存文件映射方式将index.zip中的XXXXX.smoosh文件加载到内存中,并在Zookeeper中本节点的served segments目录下声明该Segment已被加载,从而该Segment可以被查询。对于重新上线的Historical Node,在完成启动后,也会扫描本地存储路径,将所有扫描到的Segment加载如内存,使其能够被查询。
Historical Node是对“historical”数据(非实时)进行处理存储和查询的地方。Historical节点响应从Broker节点发来的查询,并将结果返回给broker节点。它们在Zookeeper的管理下提供服务,并使用Zookeeper监视信号加载或删除新数据段。
Historical Node封装了加载和处理由Realtime Node创建的不可变数据块(segment)的功能。在很多业务开发中,大部分导入到Druid集群中的数据都是不可变的,因此,Historical Node通常是Druid集群中的主要工作组件。Historical Node遵循 shared-nothing 的架构,因此节点间没有单点问题。节点间是相互独立的并且提供的服务也是简单的,它们只需要知道如何加载、删除和处理不可变的segment。
Historical Node在Zookeeper中通告它们的在线状态和为哪些数据提供服务。加载和删除segment的指令会通过Zookeeper来进行发布,指令会包含segment保存在deep storage的什么地方和怎么解压、处理这些segment的相关信息。在Historical Node从deep storage下载某一segment之前,它会先检查本地缓存信息中看segment是否已经存在于节点中,如果segment还不存在缓存中,Historical Node会从deep storage中下载segment到本地。这个处理过程如图所示,一旦处理完成,这个segment就会在Zookeeper中进行通告。此时,这个segment就可以被查询了。Historical Node的本地缓存也支持Historical Node的快速更新和重启,在启动的时候,该节点会检查它的缓存,并为任何它找到的数据立刻进行服务的提供。
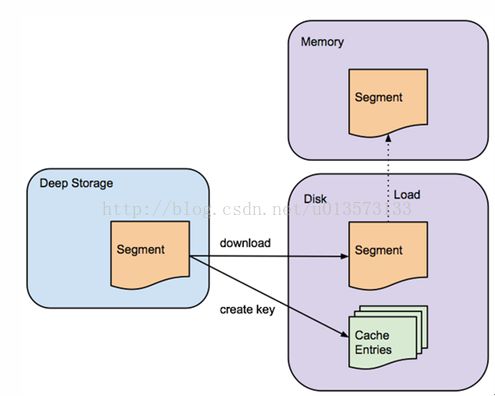
Historical Node从deep storage下载不可变的segment。segment在可以被查询之前必须要先加载到Historical Node内存中
Historical Node可以支持读一致性,因为它们只处理不可变的数据。不可变的数据块同时支持一个简单的并行模型:Historical Node可以以非阻塞的方式并发地去扫描和聚合不可变的数据块。
Historical Node负责加载历史Segment并且提供针对这些历史Segment的查询。
启动方式: io.druid.cli.Mainserverhistorical
加载和Segment和提供对Segments的服务
每一个历史节点保持与Zookeeper的连接,查看一个可配置的关于新的Segment信息的Zookeeper路径。历史节点之间或者历史节点和协调节点之间不直接通信,而是通过Zookeeper管理协调。
协调节点负责将新的Segment分配给历史节点。分配是通过在Zookeeper下与历史节点相关联的加载队列路径下创建一个临时记录,想了解更多关于怎样配置协调节点分配Segment到历史节点,请参考协调节点的配置。
当一个Historical Node发现在Zookeeper中与它关联的加载队列目录下有一个新的加载记录时,它首先检查本地磁盘目录(缓存)中关于新的Segment的信息。如果缓存中没有关于新的Segment的信息,历史节点将下载新的Segment的元数据信息并告知Zookeeper。元数据包含新的Segment在“Deep Storage”中的存储位置,怎样去解压缩和处理新的Segment的信息。对于更多关于Segment的元数据信息和Druid Segments请参考Segment的介绍。一旦一个Historical Node处理完成一个Segment,该Segment在Zoookeeper与该节点关联的服务Segments路径中公布可以提供服务。此刻,这个Segment可以用于查询。
一、从在缓存中加载和服务Segments
回想一下,当一个Historical Node注意到它的loadqueue中一个新的Segment记录时,这个Historical Node首先检查本地磁盘的缓存目录,查看新的Segment在之前是否下载过,如果本地缓存目录中已经存在该Segment的记录,Historical Node将直接从本地磁盘读取Segment并且加载到内存中。
当Historical Node第一次启动时,Segment的缓存就会被利用。在启动时,Historical Node将从本地缓存目录中查找所有能被发现的Segments,直接加载到Historical Node内存中并提供服务。这个特性使得只要历史节点在线就能很快提供查询服务。
二、查询Segments
一个历史数据可以配置为日志和报告的指标,为每一个查询服务。
三、Tiers
Historical Node可以分组到不同的tier中,哪些节点会被分到一个tier中是可配置的。可以为不同的tier配置不同的性能和容错参数。Tier的目的是可以根据segment的重要程度来分配高或低的优先级来进行数据的分布。例如,可以使用一批很多个核的CPU和大容量内存的节点来组成一个“热点数据”的tier,这个“热点数据”集群可以配置来用于下载更多经常被查询的数据。一个类似的"冷数据"集群可以使用一些性能要差一些的硬件来创建,“冷数据”集群可以只包含一些不是经常访问的segment。
Druid访问控制策略采用数据分层(tier),有以下两种用途:
将不同的Historical Node划分为不同的group,从而控制集群内不同权限(priority)用户在查询时访问不同group。
通过划分tier,让Historical Node加载不同时间范围的数据。例如tier_1加载2016年Q1数据,tier_2加载2016年Q2数据,tier_3加载2016年Q3数据等;那么根据用户不同的查询需求,将请求发往对应tier的Historical Node,不仅可以控制用户访问请求,同时也可以减少响应请求的Historical Node数量,从而加速查询。
四、可用性
Historical Node依赖于Zookeeper来管理segment的加载和卸载。如果Zookeeper变得不可用的时候,Historical Node就不再可以为新的数据提供服务和卸载过期的数据,因为是通过HTTP来为查询提供服务的,对于那些查询它当前已经在提供服务的数据,Historical Node仍然可以进行响应。这意味着Zookeeper运行故障时不会影响那些已经存在于Historical Node的数据的可用性。
五、可用性
Historical Node在druid的角色是Historical,对外提供查询已经生成的segments数据。
ØCostBalancerStrategy
基于各种metric计算segments具体被哪个historical节点加载。
负载很均匀,新加入的节点后,能够把现有节点缓慢的调节到负载均衡的状态。
※计算很耗时,在一次tracking线上数据测试中,总segments数量达到37万,每小时生成2万左右segment的情况下,导致segments一直在waiting handOff,两天都没有handOff完成。
Ø RandomBalancerStrategy
采用Java的Random,计算segments具体被哪个historical节点加载。
计算效率较高,现有节点能够基本均匀(差异百分比不会超过2%)负载到各个historical节点上。
※缺点是现有节点负载较高时,新加入节点后不能自动重分配。
六、 Historical Node的负载均衡Best Practice
采用 RandomBalancerStrategy
采用随机的策略能够保证同一时点加入的机器负载是均衡的。修改策略是需要修改代码,重新编译的,截图如下:
不同业务线的Datasource加载到不同的Tier中
(1)每个historical节点只能属于一个tier
(2)负载均衡算法是在Tier内historical节点的负载均衡
这样能保证不同业务线之间的负载均衡不互相影响
同一业务线的通过临时Tier调整负载均衡
操作过程是,加入新的historical节点后,先把datasource所属的tier设置为临时的tier,然后等加载到临时tier完成时,再切换回原来的tier,这样逐步能使整个业务线的负载达到均衡。
同一业务线的datasource分配不同的tier
把同一业务线的datasource分类,然后按照分类加载到各自的tier中。