JAVA实现trie树(前缀树,字典树)进行敏感词检测/过滤
JAVA实现trie树(前缀树,字典树)进行敏感词检测/过滤
文章目录
- JAVA实现trie树(前缀树,字典树)进行敏感词检测/过滤
- 定义
- 优点:
- 缺点:
- 应用
- 敏感词检测
- 开始构建敏感词Trie树
- 时间复杂度
- 敏感词去重
- 敏感词检测
- 去特殊字符
- 方法
- 结束标识符
- JAVA实现
- 完整代码
- 初始化
- 词库
定义
在计算机科学中,trie树,又称前缀树或字典树,是一种有序树,用于保存关联数组,其中的键通常是字符串。与二叉查找树不同,键不是直接保存在节点中,而是由节点在树中的位置决定。一个节点的所有子孙都有相同的前缀,也就是这个节点对应的字符串,而根节点对应空字符串。一般情况下,不是所有的节点都有对应的值,只有叶子节点和部分内部节点所对应的键才有相关的值。
trie中的键通常是字符串,但也可以是其它的结构。trie的算法可以很容易地修改为处理其它结构的有序序列,比如一串数字或者形状的排列。比如,bitwise trie中的键是一串位元,可以用于表示整数或者内存地址
优点:
-
可以最大限度地减少无谓的字符串比较
-
跟哈希表比较:
1. 最坏情况时间复杂度比hash表好
2. 没有冲突,除非一个key对应多个值(除key外的其他信息)
3. 自带排序功能(类似Radix Sort),中序遍历trie可以得到排序。
缺点:
-
虽然不同单词共享前缀,但其实trie是一个以空间换时间的算法。其每一个字符都可能包含至多字符集大小数目的指针(不包含卫星数据)。
-
每个结点的子树的根节点的组织方式有几种。
- 如果默认包含所有字符集,则查找速度快但浪费空间(特别是靠近树底部叶子)。
- 如果用链接法(如左儿子右兄弟),则节省空间但查找需顺序(部分)遍历链表。
- alphabet reduction*: 减少字符宽度以减少字母集个数。,4>对字符集使用bitmap,再配合链接法。
-
如果数据存储在外部存储器等较慢位置,Trie会较hash速度慢(hash访问O(1)次外存,Trie访问O(树高))。
应用
- 词频统计
- 大量字符串排序。
敏感词检测
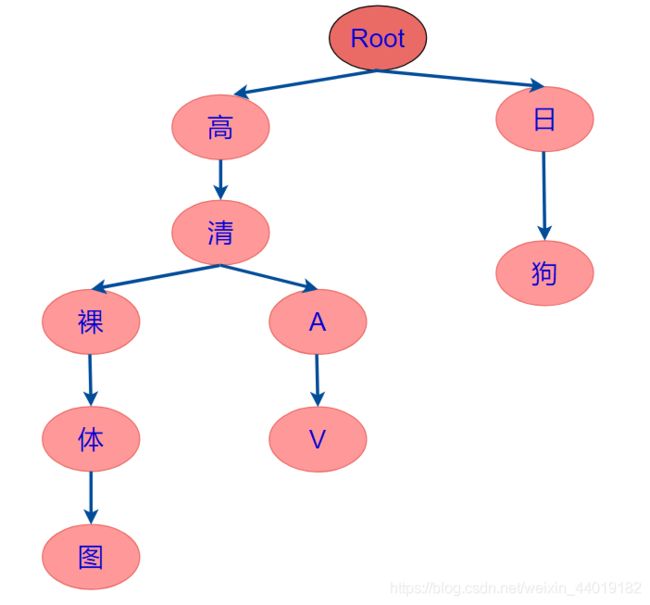
假设我们的敏感词库有下面敏感词:
-
高清AV
-
日狗
-
高清裸体图
开始构建敏感词Trie树
时间复杂度
- 如果敏感词的长度为 m,有 n个敏感词的话,构建 trie 树的时间复杂度是 O(n * m)。
- 但是我们可以使用静态代码块在应用初始化的时候就构建trie 树,而且之后每次查找都可以复用这棵树。所以可以忽略构建 trie 树的时间复杂度,
静态代码块:执行优先级高于非静态的初始化块,它会在类初始化的时候执行一次,执行完成便销毁,它仅能初始化类变量,即static修饰的数据成员。
static{
}
敏感词去重
但是一般我们的敏感词词库都很大,当敏感词数量很多之后我们新添敏感词的时候可能会忘记之前是不是添加了某个敏感词,那就会出现重复的敏感词,为了敏感词树构建的效率,我们要对敏感词去重
怎么去重?很简单,把敏感词读出来之后放进HashSet中,再把敏感词从HashSet中遍历出来插入TRIE树就可以啦
敏感词检测
如果有一段文字是:那些简单就是不肯免费带你吃鸡充不上电剧场版免费吃鸡,带你看免*费 AV
怎么从上面这段文字中检测出这段文字是否包含敏感词呢?
去特殊字符
有时候用户知道我们有敏感词检测的功能,会用一些特殊符号隔开敏感词,这时候为了更严格地检测,我们要把用户输入的特殊字符去掉特殊字符再检测
方法
- 使用正则匹配出文本中的特殊字符
- 把特殊字符把用‘’空字符串代替
/**
* create by: Antares
* description: 去掉特殊字符
* create time: 2020/6/9 18:22
* return
**/
public static String deleteSpecialWord (String txt) {
String regEx = "[\n`~!@#$%^&*()+=|{}':;,\\[\\].<>/?!¥…()—【】‘;:”“’。,_·、?]";
//可以在中括号内加上任何想要替换的字符,实际上是一个正则表达式
//这里是将特殊字符换为aa字符串,""代表直接去掉
String aa = "";
Pattern p = Pattern.compile (regEx);
Matcher m = p.matcher (txt);//这里把想要替换的字符串传进来
return m.replaceAll (aa).trim ();
}
结束标识符
有时候会出现一种情况是:词库中含有敏感词是另一个敏感词的前缀,比如:abc是敏感词,abcd也是敏感词,检测ABCD很好办,因为可以默认为叶子结点就是结束位置
那么如何能够在检测时检测出abc呢?
- 可以用1表示是结尾,0不是
- 也可以用true ,false
JAVA实现
那么在JAVA中选用什么数据结构来实现Trie树呢
HashMap
- 我们都知道HashMap是一个查找效率在O(logn)的集合,所以用在这再合适不过
完整代码
初始化
import org.springframework.core.io.ClassPathResource;
import java.io.BufferedReader;
import java.io.InputStreamReader;
import java.util.*;
public class SensitiveWordInit {
public static HashMap sensitiveWordMap;
private static String ENCODING = "UTF-8"; //字符编码
static {
initKeyWord ();
}
public SensitiveWordInit () {
super ();
}
public static Map initKeyWord () {
try {
//读取敏感词库
Set<String> keyWordSet = readSensitiveWordFile ();
// System.out.println (keyWordSet.size ());
//将敏感词库加入到HashMap中
addSensitiveWordToHashMap (keyWordSet);
//spring获取application,然后application.setAttribute("sensitiveWordMap",sensitiveWordMap);
} catch (Exception e) {
e.printStackTrace ();
}
return sensitiveWordMap;
}
private static void addSensitiveWordToHashMap (Set<String> keyWordSet) {
sensitiveWordMap = new HashMap (keyWordSet.size ());
String key;
Map nowMap;
Map<String, String> newWorMap;
//迭代keyWordSet
Iterator<String> iterator = keyWordSet.iterator ();
while (iterator.hasNext ()) {
key = iterator.next (); //关键字
nowMap = sensitiveWordMap;
for (int i = 0; i < key.length (); i++) {
//把词拆成一个一个字
char keyChar = key.charAt (i);
// System.out.println (keyChar);
Object wordMap = nowMap.get (keyChar); //获取
if (wordMap != null) { //如果存在该key,直接赋值
nowMap = (Map) wordMap;
} else { //不存在则,则构建一个map,同时将isEnd设置为0,因为他不是最后一个
newWorMap = new HashMap<> ();
newWorMap.put ("isEnd", "0"); //不是最后一个
nowMap.put (keyChar, newWorMap);
nowMap = newWorMap;
}
if (i == key.length () - 1) {
nowMap.put ("isEnd", "1"); //最后一个
}
}
}
// System.out.println (sensitiveWordMap);
}
/**
* 读取敏感词库中的内容,将内容添加到set集合中
*/
@SuppressWarnings ("resource")
private static Set<String> readSensitiveWordFile () throws Exception {
Set<String> set = null;
ClassPathResource resource = new ClassPathResource ("Keywords.txt");
// File file = resource.getFile ();
InputStreamReader read = new InputStreamReader (resource.getInputStream (), ENCODING);
try {
if (resource.getInputStream () != null) { //文件流是否存在
set = new HashSet<> ();
BufferedReader bufferedReader = new BufferedReader (read);
String txt;
while ((txt = bufferedReader.readLine ()) != null) {//读取文件,将文件内容放入到set中
// System.out.println (txt);
set.add (WordFilter.deleteSpecialWord (txt));
}
} else { //不存在抛出异常信息
throw new Exception ("敏感词库文件不存在");
}
} catch (Exception e) {
} finally {
read.close (); //关闭文件流
}
return set;
}
}
import org.springframework.stereotype.Component;
import java.util.HashSet;
import java.util.Iterator;
import java.util.Map;
import java.util.Set;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
@Component
public class SensitiveWordFilter {
public static int minMatchTYpe = 1; //最小匹配规则
public static int maxMatchType = 2; //最大匹配规则
@SuppressWarnings ("rawtypes")
private Map sensitiveWordMap;
/**
* 构造函数,初始化敏感词库
*/
public SensitiveWordFilter () {
sensitiveWordMap = new SensitiveWordInit ().initKeyWord ();
}
/**
* create by: Antares
* description: 去掉特殊字符
* create time: 2020/6/9 18:22
* return
**/
public static String deleteSpecialWord (String txt) {
String regEx = "[\n`~!@#$%^&*()+=|{}':;,\\[\\].<>/?!¥…()—【】‘;:”“’。,_·、?]";
//可以在中括号内加上任何想要替换的字符,实际上是一个正则表达式
//这里是将特殊字符换为aa字符串,""代表直接去掉
String aa = "";
Pattern p = Pattern.compile (regEx);
Matcher m = p.matcher (txt);//这里把想要替换的字符串传进来
return m.replaceAll (aa).trim ();
}
public static void main (String[] args) {
String string = "Song(songId=null, songName=好怀念觉得静静地记, mood=testmood, createTime=null, singer=testsinger, isOpen=null, callTimes=null, user=WeChatUser callTimes=null, user=WeChatUser(userId=20, openId=null, nickName=null, avatarUrl=null, userSex=null, userArea=null, userPhone=null, dayOrder=null), calls=null)\n";
System.out.println ("待检测语句字数:" + string.length ());
long beginTime = System.currentTimeMillis ();
SensitiveWordFilter filter = new SensitiveWordFilter ();
System.out.println ("敏感词的数量:" + filter.sensitiveWordMap.size ());
Set<String> set = filter.getSensitiveWord (string, 1);
long endTime = System.currentTimeMillis ();
System.out.println ("语句中包含敏感词的个数为:" + set.size () + "。包含:" + set);
System.out.println ("总共消耗时间为:" + (endTime - beginTime));
}
/**
* 判断文字是否包含敏感字符
*
* @param txt
* 文字
* @param matchType
* 匹配规则 1:最小匹配规则,2:最大匹配规则
*
* @return 若包含返回true,否则返回false
*/
public boolean isContainSensitiveWord (String txt, int matchType) {
txt = deleteSpecialWord (txt);
boolean flag = false;
for (int i = 0; i < txt.length (); i++) {
int matchFlag = this.CheckSensitiveWord (txt, i, matchType); //判断是否包含敏感字符
if (matchFlag > 0) { //大于0存在,返回true
flag = true;
}
}
return flag;
}
/**
* 获取文字中的敏感词
*
* @param txt
* 文字
* @param matchType
* 匹配规则 1:最小匹配规则,2:最大匹配规则
*/
public Set<String> getSensitiveWord (String txt, int matchType) {
txt = deleteSpecialWord (txt);
Set<String> sensitiveWordList = new HashSet<String> ();
for (int i = 0; i < txt.length (); i++) {
int length = CheckSensitiveWord (txt.toLowerCase (), i, matchType); //判断是否包含敏感字符
if (length > 0) { //存在,加入list中
sensitiveWordList.add (txt.toLowerCase ().substring (i, i + length));
i = i + length - 1; //减1的原因,是因为for会自增
}
}
return sensitiveWordList;
}
/**
* 替换敏感字字符
*
* @param replaceChar
* 替换字符,默认*
*/
public String replaceSensitiveWord (String txt, int matchType, String replaceChar) {
String resultTxt = txt;
Set<String> set = getSensitiveWord (txt, matchType); //获取所有的敏感词
Iterator<String> iterator = set.iterator ();
String word = null;
String replaceString = null;
while (iterator.hasNext ()) {
word = iterator.next ();
replaceString = getReplaceChars (replaceChar, word.length ());
resultTxt = resultTxt.replaceAll (word, replaceString);
}
return resultTxt;
}
/**
* 获取替换字符串
*/
private String getReplaceChars (String replaceChar, int length) {
String resultReplace = replaceChar;
for (int i = 1; i < length; i++) {
resultReplace += replaceChar;
}
return resultReplace;
}
/**
* 检查文字中是否包含敏感字符,检查规则如下:
*/
@SuppressWarnings ({"rawtypes"})
public int CheckSensitiveWord (String txt, int beginIndex, int matchType) {
boolean flag = false; //敏感词结束标识位:用于敏感词只有1位的情况
int matchFlag = 0; //匹配标识数默认为0
char word;
Map nowMap = sensitiveWordMap;
for (int i = beginIndex; i < txt.length (); i++) {
word = txt.toLowerCase ().charAt (i);
// System.out.println (word);
nowMap = (Map) nowMap.get (word); //获取指定key
if (nowMap != null) { //存在,则判断是否为最后一个
matchFlag++; //找到相应key,匹配标识+1
if ("1".equals (nowMap.get ("isEnd"))) { //如果为最后一个匹配规则,结束循环,返回匹配标识数
flag = true; //结束标志位为true
if (SensitiveWordFilter.minMatchTYpe == matchType) { //最小规则,直接返回,最大规则还需继续查找
break;
}
}
} else { //不存在,直接返回
break;
}
}
if (matchFlag < 2 || ! flag) { //长度必须大于等于1,为词
matchFlag = 0;
}
return matchFlag;
}
}
词库
链接:https://pan.baidu.com/s/15v_TPMo0r6IqV6xRdic1Hw
提取码:hi5h
参考文章:https://blog.csdn.net/chenssy/article/details/26961957?depth_1-utm_source=distribute.pc_relevant.none-task-blog-BlogCommendFromBaidu-1&utm_source=distribute.pc_relevant.none-task-blog-BlogCommendFromBaidu-1