最新论文阅读(11)
An Anchor-Free Region Proposal Network for Faster R-CNN based Text Detection Approaches
- 2018年4月
- 无锚区域提议网络(AF-RPN)
- 微软亚洲研究院
对于尺度变化比较大的数据集来说,Faster RCNN 的 RPN 阶段 anchor 的设计就会比较复杂(需要手动设计各种比例尺,高宽比,甚至方位的锚),同时 anchor 只能预测水平的检测框,而不能预测带旋转角度的检测框。
因此本文作者放弃了在 RPN 阶段使用 anchor,在 RPN 阶段直接使用一个点(同样也是用 3 x 3 的滑动窗在 conv4 特征图上滑动得到)回归出 bounding box 的四个角点坐标,backbone 是 FPN 版本的 RPN 网络,在 coco 和 icdar 上都取得了比 FPN 版 Faster RCNN 更好的效果。
Learned Deformation Stability in Convolutional Neural Networks
-
-
-
传统观点认为,CNN 中的池化层导致了对微小平移和变形的稳定性。
DeepMind 的研究者提出了一个反直觉的结果:CNN 的变形稳定性仅在初始化时和池化相关,在训练完成后则无关;并指出,滤波器的平滑度才是决定变形稳定性的关键因素。
本文展示了没有池化的网络在初始化时对变形敏感,但经过训练学习表征的过程之后对变形是稳定的;池化和非池化训练网络的层间变形稳定性模式最终会收敛到相似的结构;无论池化还是非池化网络,都可通过滤波器的平滑性实现和调节变形稳定性。
MobileFaceNets: Efficient CNNs for Accurate Real-time Face Verification on Mobile Devices
- 2018年5月
- MobileFaceNets;比MobileNetV2要好,并且参数也要少
-
在相同的实验条件下,我们的MobileFaceNets比MobileNetV2实现了更高的精度以及超过2倍的实际加速比。参数少于100万,专门为移动和嵌入式设备上的高精度实时人脸验证量身定制。。
我们的单一MobileFaceNet 4.0MB大小的单一MobileFaceNet模型在从头开始经过精炼的MS-Celeb-1M的ArcFace损失培训后,在LFW上的面部验证准确度达到99.55%,在MegaFace Challenge 1上达到92.59%的TAR @ FAR1e-6,这甚至可以与几百MB大小的一些最先进的大型CNN模型相媲美。
我们最快的MobileFaceNets在手机上的实际推断时间为18毫秒。我们在LFW,AgeDB和MegaFace上的实验表明,与最先进的轻量级和移动CNN进行人脸验证相比,我们的MobileFaceNets实现了显着提高的效率。
细节
此处使用了可分离卷积代替平均池化层,即使用一个7*7*512(512表示输入特征图通道数目)的可分离卷积层代替了全局平均池化,这样可以让网络自己不同点的学习权重。
采用Insightface的损失函数进行训练。
一些小细节:通道扩张倍数变小;使用Prelu代替relu;使用batch Normalization。
参考资料:https://blog.csdn.net/Fire_Light_/article/details/80279342
FractalNet: Ultra-Deep Neural Networks without Residuals
- 2017年5月
-
-
路径舍弃的正则化;分形网络;表明残差表示不是极深卷积神经网络成功的基本要素?!
Tips and Tricks for Visual Question Answering: Learnings from the 2017 Challenge
- 2017 VQA Challenge
- VQA
- 阿德莱德大学(阿大)【澳】;澳大利亚国立大学;微软;Stanford
这篇文章没有任何新颖的 idea,完全就是工程上的脏活累活,但是将作者试的所有结构都列举了出来,并做了详细的 ablation study。
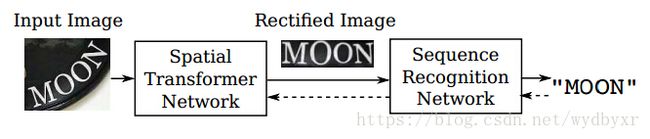
Robust Scene Text Recognition with Automatic Rectification
- 2016年3月
-
-
框架包括 Spatial Transformer Network (STN)和Sequence Recognition Network (SRN) 两个网络结构。其中,STN 通过“Thin-Plate-Spline变换”,能够将透射变换或者弯曲的文本图片对齐到一个正规的、更易读的图片;SRN能够直接将输入的文本图片识别为一个文本序列。
这个系统是一个端到端的文本识别系统,在训练过程中也不需要额外标记字符串的关键点、字符位置等。同时,由于STN和SRN这两个网络的共同作用,该系统在自然场景的文本识别方面取得了state-of-the-art的结果,特别是对于那些有着各种形变的字符图片。
YellowFin and the Art of Momentum Tuning
- 2017年6月
- SGD动量自调节器YellowFin
- 斯坦福大学
超参数调整是深度学习的巨大成本之一。Adagrad,RMSProp和Adam等最先进的优化器通过自适应地调整每个变量的单独学习速率,使事情变得更加简单。然而,我们的实验以及Wilson等人最近的理论表明,手动调整的随机梯度下降(SGD)以相同或更快的速度达到更好的结果。
我们重新回顾简单的动量SGD算法,并显示手动调整单个学习率和动量值使其与Adam竞争。然后我们分析它在学习速率错误指定和目标曲率变化方面的鲁棒性。
基于这些见解,我们设计了YellowFin,这是一个自动调谐器,以SGD为策略和学习率。YellowFin可选择使用一种新型的动量感应元件以及负反馈回路机制来补偿训练中不同步的附加动态。
实验在ResNet和LSTM模型,展示了YellowFin以比Adam更少的迭代收敛。但根据知乎的讨论,收敛确实更快,不过最后结果未必更好,且根据网络的不同甚至可能发生不收敛的情况。
Learning Transferable Architectures for Scalable Image Recognition
- 2018年4月
- NASNet;迁移学习;强化学习;总而言之就是,用神经网络来设计神经网络
- 谷歌
这要从ICLR2017的时候说起,google brain 当时出了一个工作,提出了神经网络的设计可以用神经网络来学习(designing netwotks to learn how to design networks~~),就是本文中引用的NAS(Neural architecture search with reinforcement learning).
其实当时mit也有类似的工作,但是效果没nas好,我觉得主要是gpu没他们多(有钱真的可以为所欲为。
nas 基于强化学习,方法也很暴力,搜索空间也很大,在cnn和rnn上都做了探索,使用了800块gpu,当然只在cifair10上做的啦,而且没有超过densenet的性能。 由于网络结构的搜索空间大,所以设计的网络连接也有些反人类,特别是rnn,手机上码字,不好贴图,有兴趣可以看看 nas 的paper 感受下。直接使用nas的框架来跑imagenet显然是不行的!于是就有了这篇工作了。
个人觉得这篇工作可以看做是在nas的基础上加上几个改进,使得可以在cifar10上设计的网络能够在imagenet上有效。第一个改进其实是一个经验:cnn 可以由同构模块进行堆叠而构成。这样设计一个大型cnn网络就直接简化为设计一个block就行了,也就可以用nas解决了。第二个改进:合理选择搜索空间中的操作,使得block运行时对输入尺寸没有要求(例如卷积,pooling等操作)。这样图像由cifar的32 到imagenet的大尺寸图片就不会有问题了。第三个改进还是经验:block的连接,block内部的一些拓扑结构根据经验可以固定,不用去学。基于以上几条,nas那一套就可以直接用啦。
这篇工作里面的网络也看起来人性化一些,一个原因就是经验性的东西加入了很多。