Globally and Locally Consistent Image Completion 论文及lua 代码解读
一、论文
1、论文思想
上一篇文章提到的Context encode 利用decoder 和encoder 来进行image inpainting,可以修复较大的图像缺失并使得恢复好的图像符合整幅图像的语义,但是修复好的图像存在局部模糊的问题,因此真实图像和利用inpainting 得到的图像肉眼清晰可辨。针对这个问题,SATOSHI IIZUKA 等提出了一个新的想法,即利用global discriminator 和local discriminator 两种判别器保证生成的图像即符合全局语义,又尽量提高局部区域的清晰度和对比度。论文中的网络结构如下:

(1)completion network
completion network 的主体机构与context encoder 相同,先利用卷积降低图片的分辨率然后利用去卷积增大图片的分辨率得到修复结果。为了保证生成区域尽量不模糊,文中降低分辨率的操作是使用strided convolution 的方式进行的,而且只用了两次,将图片的size 变为原来的四分之一。同时在中间层还使用了dilated convolutional layers 来增大感受野,在尽量获取更大范围内的图像信息的同时不损失额外的信息。
By using dilated convolutions at lower resolutions, the model can effectively “see” a larger area of the input image when computing each output pixel than with standard convolutional layers.

Dilated convolution 的操作一张图就能看明白:
想看动图可以参考:如何理解空洞卷积(dilated convolution)?

(2)Context discriminator
Context discriminator 包含global 和local 两种,global discriminator 把修复好的完整图片作为输入,如果图片较大,会将其resize 成256 × 256,通过多次convolution 和全连接层输出一个1024 维的向量,local discriminator 输入为修复的区域,resize 其大小为128 × 128,同样通过多次卷积和全连接输出一个1024 维的向量,把这两个向量连接成2048 维的向量再经过一个全连接层,输出判别结果。
2、具体算法
算法的具体操作流程如下:

其中Mc 为生成图像的Mask,Md 为真实图像的Mask,利用(C(x, Mc), Mc) 和(x, Md) 的交叉熵loss 来进行更新。
交叉熵的介绍见此: 一文搞懂交叉熵在机器学习中的使用,透彻理解交叉熵背后的直觉
3、训练过程
(1)训练
文中训练使用的数据集如下:
① Places2 dataset contains more than 10 million images comprising 400+ unique scene categories.
② Imagenet 数据集有1400多万幅图片,涵盖2万多个类别;其中有超过百万的图片有明确的类别标注和图像中物体位置的标注。
训练过程按上面提到的算法流程进行,其中涉及到两个loss:
In order to stabilize the training, a weighted MSE loss considering the completion region mask is used.
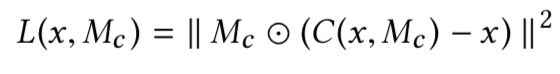
The context discriminator networks also work as a kind of loss, sometimes called the GAN loss.

(2)Post processing
Although our network model can plausibly fill missing regions, sometimes the generated area has subtle color inconsistencies with the surrounding regions. To avoid this, we perform simple post-processing by blending the completed region with the color of the surrounding pixels. In particular, we employ the fast marching method [Telea 2004], followed by Poisson image blending [Pérez et al. 2003].
4、优势和缺点
优势:复原能力强,且可以生成眼睛、鼻子等细节结构,但是需要在相关数据集上进行fine-training
缺点:如果mask 中抹掉的是大块的结构状物体,复原效果比较差,接近object removal 的效果了
二、代码
1、github
https://github.com/satoshiiizuka/siggraph2017_inpainting
2、代码解读
inpaint.lud 代码及注释
--[[
Copyright (C) <2017>
This work is licensed under the Creative Commons
Attribution-NonCommercial-ShareAlike 4.0 International License. To view a copy
of this license, visit http://creativecommons.org/licenses/by-nc-sa/4.0/ or
send a letter to Creative Commons, PO Box 1866, Mountain View, CA 94042, USA.
Satoshi Iizuka, Waseda University
[email protected], http://hi.cs.waseda.ac.jp/~iizuka/index_eng.html
Edgar Simo-Serra, Waseda University
[email protected], http://hi.cs.waseda.ac.jp/~esimo/
--]]
require 'nn'
require 'nngraph'
require 'image'
require 'utils'
torch.setdefaulttensortype( 'torch.FloatTensor' )
-- commandline options
cmd = torch.CmdLine()
cmd:addTime()
cmd:text()
-- 输入参数及默认值
cmd:option( '--input', 'none', 'Input image' )
cmd:option( '--mask', 'none', 'Mask image')
cmd:option( '--maxdim', 500, 'Long edge dimension of an input image')
cmd:option( '--gpu', false, 'Use GPU' )
cmd:option( '--nopostproc', false, 'Disable post-processing' )
-- 解析参数并输出
local opt = cmd:parse(arg or {})
print(opt)
assert( opt.input ~= 'none' )
print( 'Loding model...' )
-- load Completion Network
-- torch.load 的参数是什么形式?
local data = torch.load( 'completionnet_places2.t7' )
local model = data.model
local datamean = data.mean
model:evaluate()
-- 使用gpu
if opt.gpu then
require 'cunn'
model:cuda()
end
-- load data
local I = image.load( opt.input )
local M = torch.Tensor()
-- 加载mask 图并保证其与待处理图片size 相同
if opt.mask~='none' then
M = load_image_gray( opt.mask )
assert( I:size(2) == M:size(2) and I:size(3) == M:size(3) )
else
-- generate random holes
-- size 2 3 分别对应行、列 => 图像的高、宽
M = torch.Tensor( 1, I:size(2), I:size(3) ):fill(0)
-- 产生2-4 之间的随机数
local nHoles = torch.random( 2, 4 )
for i=1,nHoles do
local mask_w = torch.random( 32, 128 )
local mask_h = torch.random( 32, 128 )
-- 选择mask 左上角的点并进行空白填充
local px = torch.random(1, I:size(3)-mask_w-1)
local py = torch.random(1, I:size(2)-mask_h-1)
local R = {{},{py,py+mask_h},{px,px+mask_w}}
M[R]:fill(1)
end
end
-- resize img 宽高最大值为500
local hwmax = math.max( I:size(2), I:size(3) )
if hwmax > opt.maxdim then
I = image.scale( I, string.format('*%d/%d',opt.maxdim,hwmax) )
M = image.scale( M, string.format('*%d/%d',opt.maxdim,hwmax) )
end
-- Set up input
-- 宽高调整为4 的倍数
I = image.scale( I, torch.round(I:size(3)/4)*4, torch.round(I:size(2)/4)*4 )
-- print(I:size())
M = image.scale( M, torch.round(M:size(3)/4)*4, torch.round(M:size(2)/4)*4 ):ge(0.2):float()
local Ip = I:clone()
-- datamean 0.4560 0.4472 0.4155
for j=1,3 do I[j]:add( -datamean[j] ) end
-- 三通道覆盖原图像
I:maskedFill( torch.repeatTensor(M:byte(),3,1,1), 0 )
-- inpaint target holes
print('Inpainting...')
-- channel 拼接
local input = torch.cat(I, M, 1)
-- size 1 c h w
input = input:reshape( 1, input:size(1), input:size(2), input:size(3) )
if opt.gpu then input = input:cuda() end
local res = model:forward( input ):float()[1]
-- image.save('res.png', res)
-- image.save('ipcmul.png', Ip:cmul(torch.repeatTensor((1-M),3,1,1)))
-- image.save('rescmul.png', res:cmul(torch.repeatTensor(M,3,1,1)))
-- ipcmul 表示除了mask 遮盖以外的图片部分,rescmul 表示生成的遮盖部分图片
local out = Ip:cmul(torch.repeatTensor((1-M),3,1,1)) + res:cmul(torch.repeatTensor(M,3,1,1))
-- perform post-processing
if not opt.nopostproc then
print('Performing post-processing...')
local cv = require 'cv'
require 'cv.photo'
local pflag = false
local minx = 1e5
local maxx = 1
local miny = 1e5
local maxy = 1
for y=1,M:size(3) do
for x=1,M:size(2) do
if M[1][x][y] == 1 then
minx = math.min(minx,x)
maxx = math.max(maxx,x)
miny = math.min(miny,y)
maxy = math.max(maxy,y)
end
end
end
local p_i = {torch.floor(miny+(maxy-miny)/2)-1,torch.floor(minx+(maxx-minx)/2)-1}
local src_i = tensor2cvimg( out )
local mask_i = M:clone():permute(2,3,1):mul(255):byte()
local dst_i = cv.inpaint{src_i, mask_i, dst=nil, inpaintRadius=1, flags=cv.INPAINT_TELEA}
local out_i = dst_i:clone()
cv.seamlessClone{ src=src_i, dst=dst_i, mask=mask_i, p=p_i, blend=out_i, flags=cv.NORMAL_CLONE }
out = out_i
out = cvimg2tensor( out )
end
-- save output
for j=1,3 do I[j]:add( datamean[j] ) end
image.save('input.png', I)
image.save('out.png', out)
print('Done.')