从零基础成为深度学习高手——III
今天开始学习进阶的知识,有兴趣的您请继续阅读和学习:
深度学习之高手进阶
我们在进行深度学习的时候一般会按照这4个步骤进行。
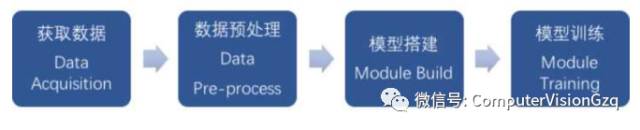
获取数据
很大程度上,数据的多少决定模型所能达到的精度。再好的模型,没有足够数据,也是白瞎。
对于监督学习而言,需要大量标定的数据。
数据的获取是有成本的,尤其是我们需要的数据都是百万、千万量级的,成本非常高。亚马逊有个专门发布标定任务的平台,叫做Amazon Mechanical Turk. 很多大的数据,比如IMAGENET就是在这上面做label的。
Amazon从中抽取20%的费用,也就是说,需求方发布100美元的任务,得多交20美元给Amazon,躺着也挣钱。
由于数据的获取是有成本的,而且成本很高的。
所以我们需要以尽量低的价格去获得更多的数据,所以,在已经获得数据基础上,仅仅通过软件处理去扩展数据,就是非常重要的,常见的数据扩展的方法见下图。

数据预处理-归一化 为了更好的计算数据,避免出现太大或者太小的数据,从而出现计算溢出或者精度失真,一般在开始做数据处理之前,需要进行归一化处理,就是将像素保持在合理的范围内,如[0,1]或者[-1,1]。

模型搭建
除了上面提到的卷积神经网络之外,我们在搭建模型的时候,还需要一些其他层,最常见的是输出控制。
全连接层Fully-connected
全连接层,其字面意思就是将每个输入值和每个输出值都连接起来,全连接层的目的其实就是控制输出数量。
比如我们最终分类是有10类,那我们需要把输出控制为10个,那就需要一个全连接层来链接输出层。

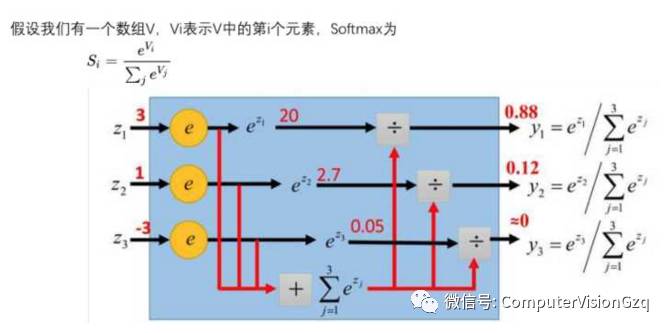
softmax
我们用数值来表征其可能性大小,数值越大,其可能性越大,有的值可能很大,有的值可能很小,是负的。
怎么用概率来表征其可能性呢?总不能加起来一除吧,但是有负数怎么办呢?全连接之后,我们每个类别得到一个值,那怎么转化表征其可能性的概率呢?我们一般通过softmax来转化。
softmax的目的就是把数值转化给每个标签的概率,就是将最终各个值的得分,转化成各个输出值的概率。
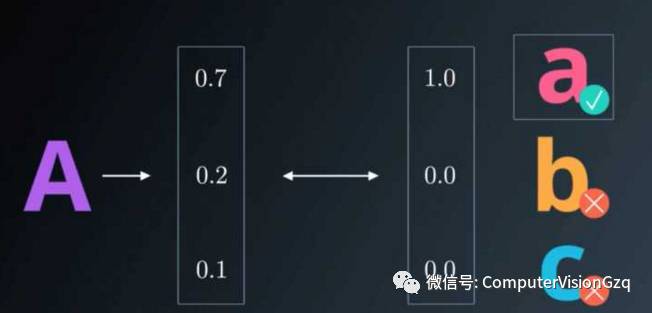
独热编码 One-Hot Encoding
独热编码,又叫做一位有效编码 有多少标签,就转化为多少行的单列矩阵,其本质就是将连续值转化为离散值。
这样可以直接直接将输出值直接输出,得到一个唯一值。 就像一个筛子,只留一个最大值,其他全部筛掉。
我们以LeNet为例串起来看(见下图),输出值经过全连接层,转化为10个标签值,然后经过softmax和one-hot encoding,最终转化为唯一的识别标签值,就是我们想要的结果。

客观评价——交叉验证
讲完输出控制,我们再讲一下评价方法。 我们有一些数据,希望利用现有的数据去训练模型,同时利用这些数据去评价这个模型的好坏,也就是我们需要知道,这个模型的准确率是50%,还是90%,还是99%?
具体怎么去做呢? 最先想到的是,用全部的数据去训练,然后评价的时候,从中抽取一定数量的样本去做验证。这不是很简单嘛?
但是,这样不行。 想像一下,在高考考场上,你打开试卷,看了一眼之后高兴坏了。因为你发现这些试题你之前做练习的时候都做过。 其实是一个道理。如果拿训练过的数据去做验证,那得到的误差率会比实际的误差率要低得多,也就失去了意义。 那怎么办呢?我们需要把训练数据和最终评价的数据(也就是验证数据)要分开。这样才能保证你验证的时候看的是全新的数据,才能保证得到的结果是客观可靠地结果。
所以我们会得到两个误差率,一个是训练集的误差率,一个是验证集的误差率,记住这两个误差率,后面会用到。
拿到数据的第一步,先把所有的数据随机分成两部分:训练集和验证集。一般而言,训练集占总数据的80%左右,验证集占20%左右。

训练的时候,随机从训练集中抽取一个批量的数据,去训练,也就是一次正向传播和一次反向传播。
这一轮做完之后,从验证集里随机抽取一定数量来评价下其误差率。 每做一轮学习,一次正向传播一次反向传播,就随机从验证集里抽取一定数量数据来评价其模型的准确率,一轮之后我们获得训练误差率和验证误差率。
接下来就是重点了,就是模型训练。
模型训练
实际训练模型的时候,我们会碰到两大终极难题,一个是欠拟合,一个是过拟合。
所谓欠拟合,就是训练误差率和验证误差率都很高。 所谓过拟合,就是训练集的误差率很低,但是验证集的误差率很高。

欠拟合和过拟合其实跟模型的复杂程度有很大的关系。
比如这张图里面,本来是抛物线的数据,如果用线性模型去拟合的话,效果很很差。如果用9次方模型去拟合的话,虽然训练集表现非常好,但是测试新数据的时候,你会发现表现很差。
欠拟合的原因其实比较简单,就是模型的深度不够,只需要把模型变得复杂一些就能解决。
过拟合的原因就比较多了,一般来说,简单粗暴的增加训练集的数量就能解决这个问题,但是有时候受限于客观条件,我们没有那么多数据。这时候我们就需要调整一些参数来解决过拟合的问题了。

模型中能调整的参数叫做超参数。
调整这些参数,有时候有道理,有时候又没有道理,更多的是靠的一种感觉。有人说,调整超参数与其说是个科学,其实更像是一项艺术。
常见的调整的超参数有以下几种,下面我们逐项介绍一下。

学习率
上面提到的随机梯度下降中,我们会在梯度的前面加一个系数,我们管它叫做学习率,这个参数直接影响了我们误差下降的快慢。
当我们遇到问题的时候,先尝试调整下学习率,说不定就能解决问题。

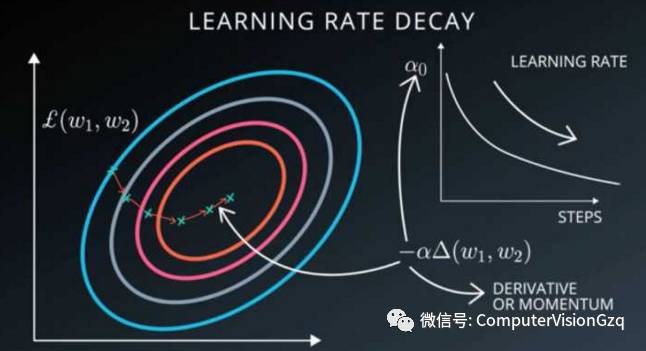
选择一个合适的学习率可能是困难的。学习率太小会导致收敛的速度很慢,学习率太大会妨碍收敛,导致损失函数在最小值附近波动甚至偏离最小值。下面这张图比较好的说明了学习率高低对模型误差下降的影响。

冲量Momentum
冲量的概念其实就是在梯度下降的时候,把上次的梯度乘以一个系数pho,加上本次计算的梯度,然后乘以学习率,作为本次下降用的梯度。pho一般选取0.9或者0.99。其本质就是加上了之前梯度下降的惯性在里面,所以叫做冲量。
有时候会采用冲量(momentum)能够有效的提高训练速度,并且也能够更好的消除SGD的噪音(相当于加了平均值),但是有个问题,就是容易冲过头了,不过总体来说,表现还是很不错的,一般用的也比较多。

下面这两张图也能看出来,SGD+冲量能够有效的加快优化速度,还能够避免随机的噪音。

轮数epochs
前面提到,一次正向传播,一次反向传播就是一轮,也就是一个epoch。
一般来说,轮数越多,其误差会越好,但是当学习的越多的时候,他会把一些不太关键的特征作为一些重要的判别标准,从而出现了过拟合。如果发现这种情况(下图),我们需要尽早停止学习。

参数初始化(weights initialization)
对于模型的所有参数,我们均随机进行初始化,但是初始化的时候我们一般会让其均值为0,公差为sigma,sigma一般选择比较大,这样其分散效果比较好,训练效果也比较好。

但是有时候仅仅调整超参数并不能解决过拟合的问题,这时候我们需要在模型上做一些文章,在模型上做一些处理,来避免过拟合。
Dropout
最常见的方法就是dropout. drop的逻辑非常简单粗暴,就是在dropout过程中,有一半的参数不参与运算。
比如说公司里,每天随机有一般人不来上班,为了正常运转,每个岗位都需要有好几个人来备份,这样公司就不会过于依赖某一个人,其实是一个道理。 dropout的本质是冗余。为了避免过拟合,我们需要额外增加很多冗余,使得其输出结果不依赖于某一个或几个特征。

Pooling池化
除此之外,池化也是比较常用到的。
Pooling主要的作用为降维,降维的同时能够保留主要特征,能够防止过拟合。 Pooling主要有两种:
一种是最大化Pooling,还有一中是平均池化。
最大池化就是把区域的最大值传递到下一层(见下图),平均池化就是把区域内的平均值传递到下一层。

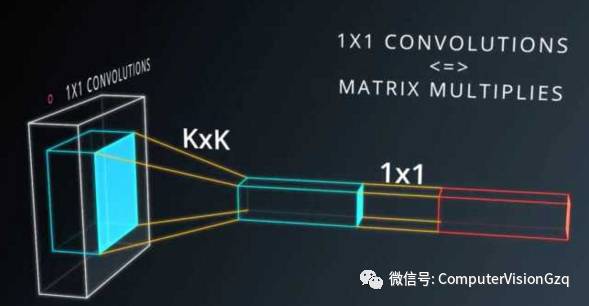
一般在Pooling之后会加上一个1x1的卷积层,这样能够以非常低的成本(运算量),带来更多的参数,更深的深度,而且验证下来效果也非常好。
接下来我们可以分析下Lenet的数据,看的出来是卷积—>池化—>卷积—>池化—>平化(Flatten,将深度转化为维度)—>全连接—>全连接—>全连接。

下面这个模型也比较简单,经过多层卷积、池化之后,平化,然后经过softmax转化。

截止到目前,我们又了解了训练模型所需要的技巧,如获取数据、预处理数据、模型搭建和模型调试,重点了解了如何防止过拟合。
恭喜你,现在你已经完全了解了深度学习的全部思想,成功晋级成深度学习高手了~ 接下来我们看下深度学习的发展趋势。
深度学习发展趋势
目前深度学习在图像识别领域取得了很多突破,比如可以对一张图片多次筛选获取多个类别,并标注在图片上。

还可以进行图像分割。
在做图像分割标注的时候,难度很大,需要把每个类别的范围用像素级的精度画出来。这对标注者的素质要求很高。

还可以根据图像识别的结果直接生成语句。

Google翻译可以直接将图片上的字母翻译过来,显示在图片上,很厉害。

最近媒体上很多新闻,说人工智能可以作诗,写文章,画画等等,这也都是比较简单的。

但是当前图像识别领域还存在一些问题,最大的就是其抗干扰能力比较差。
下图中左侧的图片为原始图片,模型可以轻易识别,但是人工加上一些干扰之后,对于肉眼识别不会造成干扰,但是会引起模型的严重误判。

这种情况可能会在某些很重要的商业应用中带来一些风险,比如在自动驾驶的物体识别时,如果有人故意对摄像头造成干扰,就会引起误判,从而可能会引起严重后果。
深度学习在人脸检测应用使用也较多,尤其是现在的安防领域:
简单的人脸检测识别:
class="video_iframe" data-vidtype="2" allowfullscreen="" frameborder="0" data-ratio="1.7647058823529411" data-w="480" data-src="http://v.qq.com/iframe/player.html?vid=p1318af7zbn&width=670&height=376.875&auto=0" style="display: block; width: 670px !important; height: 376.875px !important;" width="670" height="376.875" data-vh="376.875" data-vw="670" src="http://v.qq.com/iframe/player.html?vid=p1318af7zbn&width=670&height=376.875&auto=0"/>
深度学习在自动驾驶领域有比较多的应用,下面是我做自动驾驶项目中的视频。
车辆识别:
class="video_iframe" data-vidtype="2" allowfullscreen="" frameborder="0" data-ratio="1.7647058823529411" data-w="480" data-src="http://v.qq.com/iframe/player.html?vid=j13295eyuae&width=670&height=376.875&auto=0" style="display: block; width: 670px !important; height: 376.875px !important;" width="670" height="376.875" data-vh="376.875" data-vw="670" src="http://v.qq.com/iframe/player.html?vid=j13295eyuae&width=670&height=376.875&auto=0"/>
下图为加特纳技术曲线,就是根据技术发展周期理论来分析新技术的发展周期曲线(从1995年开始每年均有报告),以便帮助人们判断某种新技术是否采用。其把技术成熟经过5个阶段:
萌芽期,人们对新技术产品和概念开始感知,并且表现出兴趣;
过热期,人们一拥而上,纷纷采用这种新技术,讨论这种新技术;
低谷期,又称幻想破灭期。过度的预期,严峻的现实,往往会把人们心理的一把火浇灭;
复苏期,又称恢复期。人们开始反思问题,并从实际出发考虑技术的价值。相比之前冷静不少;
成熟期,又称高原期。该技术已经成为一种平常。
最后分享一下学习资料:
Stanford CS231n课程:http://cs231n.stanford.edu/
MIT自动驾驶课程:https://selfdrivingcars.mit.edu/
Deep Learning书籍: http://deeplearningbook.org
Foundational papers: http://deeplearning.net/reading-list
快速上手 http://www.fast.ai/
图解机器学习 http://www.r2d3.us/visual-intro-to-machine-learning-part-1/
最后的最后,附上一个段子图,下排中间一脸虎视眈眈、苦大仇深、表情凝重的哥们,就是我们念叨的机器学习大神——Yann Lecun,目前是Facebook AI试验室的负责人。

最后,大家都看到这里了,请求大家关注下我们的公众号“计算机视觉战队”!
想获取本次分享的完整报告吗? 关注公众号“计算机视觉战队”后,后台回复“人工智能”即可获得报告下载链接。