VGGNet笔记
1. 简介
VGGNet由牛津大学的视觉几何组(Visual Geometry Group)提出,是ILSVRC-2014中定位任务第一名和分类任务第二名。其突出贡献在于证明使用很小的卷积(3*3),增加网络深度可以有效提升模型的效果,而且VGGNet对其他数据集具有很好的泛化能力。
如今,卷积神经网络已经成为计算机视觉领域的常用工具,所以有很多人尝试改善2012年提出的AlexNet来实现更好的效果。比如,在ILSVRC中-2013中表现最好的ZFNet在第一卷积层使用更小的卷积(receptive window size)和更小的步长(stride)。另一种策略是多尺度地在整张图像上密集训练和测试。VGGNet则强调了卷积神经网络设计中另一个重要方面—深度。
2. 卷积网络配置
为了公平测试深度带来的性能提升,VGGNet所有层的配置都遵循了同样的原则。
2.1 结构
训练时,输入是大小为224*224的RGB图像,*预处理只有在训练集中的每个像素上减去RGB的均值。
图像经过一系列卷积层处理,在卷积层中使用了非常小的感受野(receptive field):3*3,甚至有的地方使用1*1的卷积,这种1*1的卷积可以被看做是对输入通道(input channel)的线性变换。
卷积步长(stride)设置为1个像素,3*3卷积层的填充(padding)设置为1个像素。池化层采用max-pooling,共有5层,在一部分卷积层后,max-pooling的窗口是2*2,步长是2。
一系列卷积层之后跟着全连接层(fully-connected layers)。前两个全连接层均有4096个通道。第三个全连接层有1000个通道,用来分类。所有网络的全连接层配置相同。
所有隐藏层都使用ReLu。VGGNet不使用局部响应标准化(LRN),这种标准化并不能在ILSVRC数据集上提升性能,却导致更多的内存消耗和计算时间。
2.2 配置
表一展示了所有的网络配置,这些网络遵循相同设计原则(in 2.1),只是深度不同。
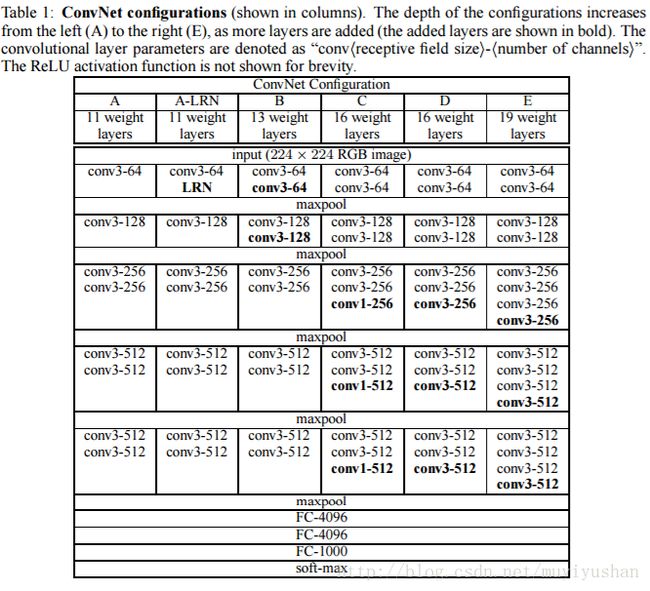
A网络(11层)有8个卷积层和3个全连接层,E网络(19层)有16个卷积层和3个全连接层。卷积层宽度(通道数)从64到512,每经过一次池化操作扩大一倍。
2.3 讨论
与AlexNet和ZFNet不同,VGGNet在网络中使用很小的卷积。AlexNet和ZFNet在第一个卷积层的卷积分别是11*11 with stride 4和7*7 with stride 2。VGGNet则使用3*3的卷积。
两个连续的3*3的卷积相当于5*5的感受野,三个相当于7*7。使用三个3*3卷积而不是一个7*7的卷积的优势有两点:一,包含三个ReLu层而不是一个,使决策函数更有判别性;二,减少了参数。比如输入输出都是C个通道,使用3*3的3个卷积层需要3(3*3*C*C)=27*C*C,使用7*7的1个卷积层需要7*7*C*C=49C*C。这可看为是对7*7卷积施加一种正则化,使它分解为3个3*3的卷积。
1*1卷积层主要是为了增加决策函数的非线性,而不影响卷积层的感受野。虽然1*1的卷积操作是线性的,但是ReLu增加了非线性。
与他人工作对比:Ciresan et al.(2011)也曾用过小的卷积,但是他的网络没有VGGNet深,而且没有在大规模的ILSVRC数据集上测试。Goodfellow使用深的卷积网络(11层)做街道数字识别,表明增加卷及网络深度可以提高性能。GoogLeNet(ILSVRC-2014分类任务冠军)与VGGNet独立发展起来,同样的是也使用了很深的卷积网络(22层)和小的卷积(5*5,3*3,1*1)。
3. 分类框架
3.1 训练
除了从多尺度的训练图像上采样输入图像外,VGGNet的训练过程与AlexNet类似。
优化方法(optimizer)是含有动量的随机梯度下降SGD+momentum(0.9)。
批尺寸(batch size)是256.
正则化(regularization):采用L2正则化,weight decay是5e-4。dropout在前两个全连接层后,p=0.5。
尽管相比于AlexNet网络更深,参数更多,但是我们推测VGGNet在更少的周期内就能收敛,原因有二:一,更大的深度和更小的卷积带来隐式的正则化;二,一些层的预训练。
参数初始化:对于较浅的A网络,参数进行随机初始化,权重w从N(0,0.01)中采样,偏差bias初始化为0。然后,对于较深的网络,先用A网络的参数初始化前四个卷积层和三个全连接层。但是后来发现,不用预训练的参数而直接随机初始化也可以。
为了获得224*224的输入图像,要在每个sgd迭代中对每张重新缩放(rescale)的图像随机裁剪。为了增强数据集,裁剪的图像还要随机水平翻转和RGB色彩偏移。
对训练图像如何缩放暂时不做阐述!!!。。。。。
3.2 测试
测试阶段步骤:1,对输入图像各向同性地重缩放到一个预定义的最小图像边的尺寸Q; 2. 网络密集地应用在重缩放后的测试图像上。也就是说全连接层转化为卷积层(第一个全连接层转化为7*7的卷积层,后两个全连接层转化为1*1的卷积层) ,然后将转化后的全连接层应用在整张图像上。结果就是一个类别分数图(class score map),其通道数等于类别数量,依赖于图像尺寸,具有不同的空间分辨率。3. 为了获得固定尺寸的类别分数向量(class score vector),对class score map进行空间平均化处理(sum-pooled)。
3.3 实现
基于C++ Caffe,进行一些重要修改,在单系统多GPU上训练。
在装有4个NVIDIA Titan Black GPUs的电脑上,训练一个网络需要2-3周。
4. 分类实验
4.1 单一尺度评估
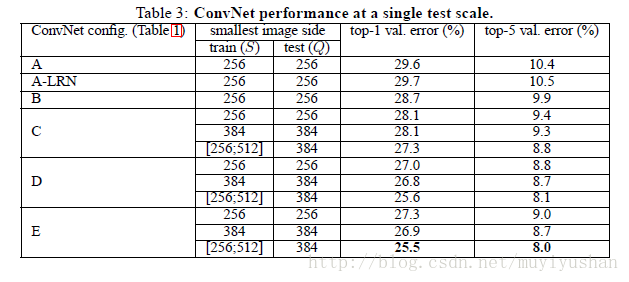
通过分析表3结果,得出如下结论。
- 我们发现使用local response normalization(A-LRN)并不能改善A网络性能。
- 分类误差随着深度增加而降低。
- 在训练时采用图像尺度抖动(scale jittering)可以改善图像分类效果。
4.2多尺度评估
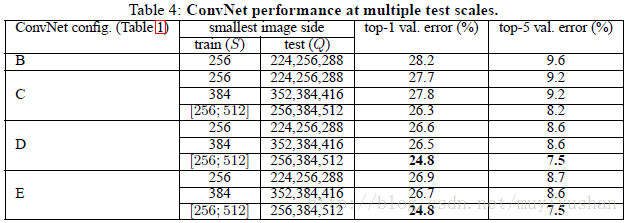
1. 相对于单一尺度评估,多尺度评估提高了分类精度。
2. 在训练时采用图像尺度抖动(scale jittering)可以改善图像分类效果。
4.3 多裁剪评估
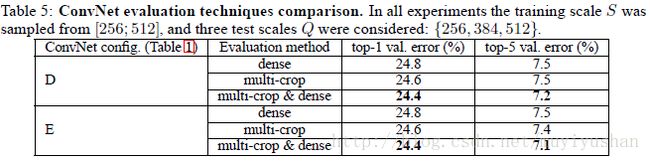
多裁剪(multi-crop)评估比起密集(dense)评估,效果更好。而且两者具有互补作用,结合两种方式,效果更好。
4.4 卷积网络融合
如果结合多个卷积网络的sofamax输出,分类效果会更好。
在ILSVRC-2014中,我们结合7个网络(表6),实现测试误差7.3%。之后,结合最好的两个模型(D&E)并使用密集评估(dense evaluation),测试误差降低到7.0%,而使用密集评估和多裁剪评估相结合,测试误差为6.8%。最好的单一模型验证误差为7.1%。
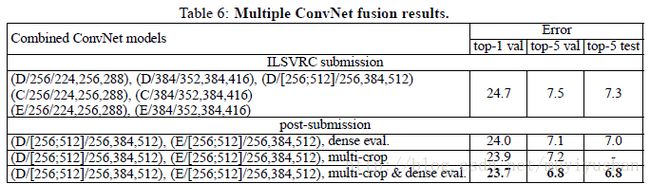
4.5 与其他网络对比
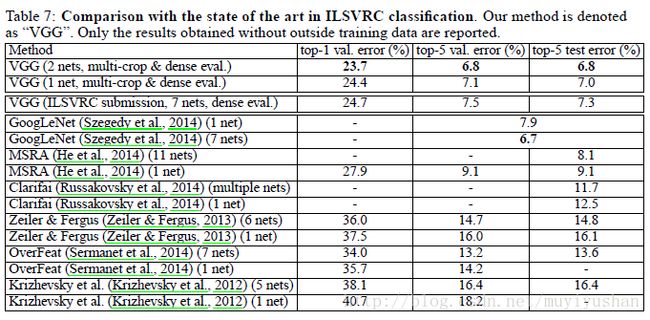
与ILSVRC-2012和ILSVRC-2013最好结果相比,VGGNet优势很大。与GoogLeNet对比,虽然7个网络集成效果不如GoogLeNet,但是单一网络测试误差好一些,而且只用2个网络集成效果与GoogLeNet的7网络集成差不多。
5.总结
我们的结果再次证明网络深度在计算机视觉问题中的重要性。而且,我们的网络在不同的任务和数据集上有很多好的泛化能力。
参考文献:VERY DEEP CONVOLUTIONAL NETWORKS FOR LARGE-SCALE IMAGE RECOGNITION