2019独角兽企业重金招聘Python工程师标准>>> 
—— 原文发布于本人的微信公众号“大数据与人工智能Lab”(BigdataAILab),欢迎关注。

2014年,牛津大学计算机视觉组(Visual Geometry Group)和Google DeepMind公司的研究员一起研发出了新的深度卷积神经网络:VGGNet,并取得了ILSVRC2014比赛分类项目的第二名(第一名是GoogLeNet,也是同年提出的)和定位项目的第一名。
VGGNet探索了卷积神经网络的深度与其性能之间的关系,成功地构筑了16~19层深的卷积神经网络,证明了增加网络的深度能够在一定程度上影响网络最终的性能,使错误率大幅下降,同时拓展性又很强,迁移到其它图片数据上的泛化性也非常好。到目前为止,VGG仍然被用来提取图像特征。
VGGNet可以看成是加深版本的AlexNet,都是由卷积层、全连接层两大部分构成。卷积神经网络技术原理、AlexNet在本博客前面的文章已经有作了详细的介绍,有兴趣的同学可打开链接看看(大话卷积神经网络,大话CNN经典模型:AlexNet)。
一、VGG的特点
先看一下VGG的结构图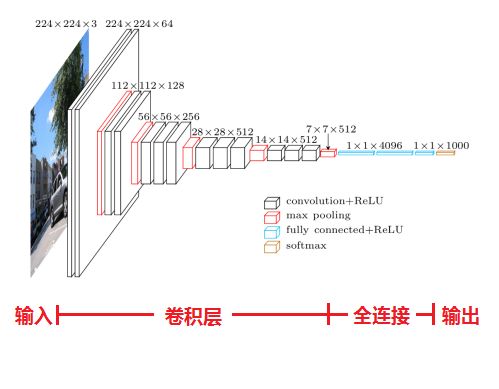
1、结构简洁
VGG由5层卷积层、3层全连接层、softmax输出层构成,层与层之间使用max-pooling(最大化池)分开,所有隐层的激活单元都采用ReLU函数。
2、小卷积核和多卷积子层
VGG使用多个较小卷积核(3x3)的卷积层代替一个卷积核较大的卷积层,一方面可以减少参数,另一方面相当于进行了更多的非线性映射,可以增加网络的拟合/表达能力。
小卷积核是VGG的一个重要特点,虽然VGG是在模仿AlexNet的网络结构,但没有采用AlexNet中比较大的卷积核尺寸(如7x7),而是通过降低卷积核的大小(3x3),增加卷积子层数来达到同样的性能(VGG:从1到4卷积子层,AlexNet:1子层)。
VGG的作者认为两个3x3的卷积堆叠获得的感受野大小,相当一个5x5的卷积;而3个3x3卷积的堆叠获取到的感受野相当于一个7x7的卷积。这样可以增加非线性映射,也能很好地减少参数(例如7x7的参数为49个,而3个3x3的参数为27),如下图所示:
3、小池化核
相比AlexNet的3x3的池化核,VGG全部采用2x2的池化核。
4、通道数多
VGG网络第一层的通道数为64,后面每层都进行了翻倍,最多到512个通道,通道数的增加,使得更多的信息可以被提取出来。
5、层数更深、特征图更宽
由于卷积核专注于扩大通道数、池化专注于缩小宽和高,使得模型架构上更深更宽的同时,控制了计算量的增加规模。
6、全连接转卷积(测试阶段)
这也是VGG的一个特点,在网络测试阶段将训练阶段的三个全连接替换为三个卷积,使得测试得到的全卷积网络因为没有全连接的限制,因而可以接收任意宽或高为的输入,这在测试阶段很重要。
如本节第一个图所示,输入图像是224x224x3,如果后面三个层都是全连接,那么在测试阶段就只能将测试的图像全部都要缩放大小到224x224x3,才能符合后面全连接层的输入数量要求,这样就不便于测试工作的开展。
而“全连接转卷积”,替换过程如下: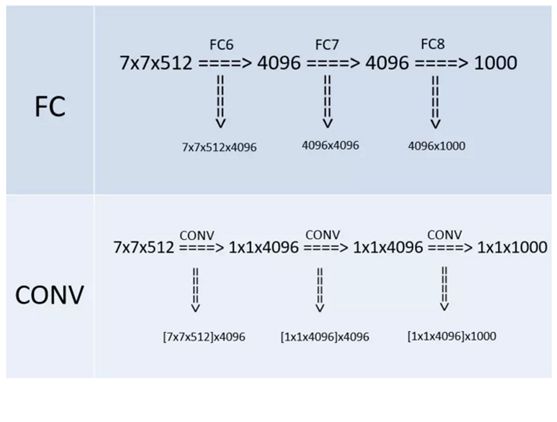
例如7x7x512的层要跟4096个神经元的层做全连接,则替换为对7x7x512的层作通道数为4096、卷积核为1x1的卷积。
这个“全连接转卷积”的思路是VGG作者参考了OverFeat的工作思路,例如下图是OverFeat将全连接换成卷积后,则可以来处理任意分辨率(在整张图)上计算卷积,这就是无需对原图做重新缩放处理的优势。

二、VGG的网络结构
下图是来自论文《Very Deep Convolutional Networks for Large-Scale Image Recognition》(基于甚深层卷积网络的大规模图像识别)的VGG网络结构,正是在这篇论文中提出了VGG,如下图: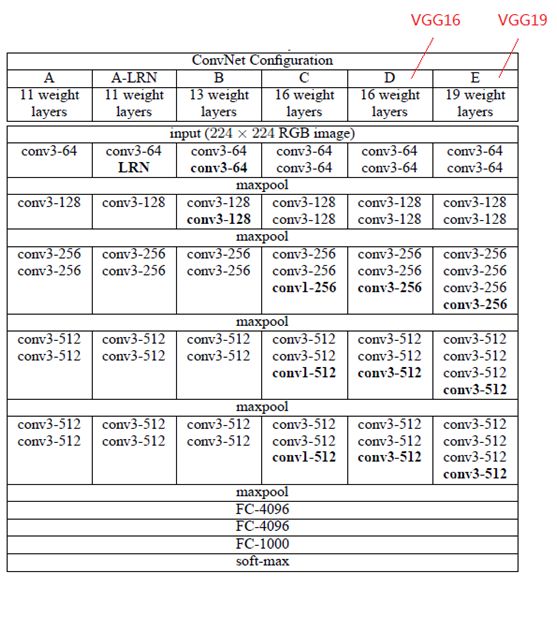
在这篇论文中分别使用了A、A-LRN、B、C、D、E这6种网络结构进行测试,这6种网络结构相似,都是由5层卷积层、3层全连接层组成,其中区别在于每个卷积层的子层数量不同,从A至E依次增加(子层数量从1到4),总的网络深度从11层到19层(添加的层以粗体显示),表格中的卷积层参数表示为“conv⟨感受野大小⟩-通道数⟩”,例如con3-128,表示使用3x3的卷积核,通道数为128。为了简洁起见,在表格中不显示ReLU激活功能。
其中,网络结构D就是著名的VGG16,网络结构E就是著名的VGG19。
以网络结构D(VGG16)为例,介绍其处理过程如下,请对比上面的表格和下方这张图,留意图中的数字变化,有助于理解VGG16的处理过程:
1、输入224x224x3的图片,经64个3x3的卷积核作两次卷积+ReLU,卷积后的尺寸变为224x224x64
2、作max pooling(最大化池化),池化单元尺寸为2x2(效果为图像尺寸减半),池化后的尺寸变为112x112x64
3、经128个3x3的卷积核作两次卷积+ReLU,尺寸变为112x112x128
4、作2x2的max pooling池化,尺寸变为56x56x128
5、经256个3x3的卷积核作三次卷积+ReLU,尺寸变为56x56x256
6、作2x2的max pooling池化,尺寸变为28x28x256
7、经512个3x3的卷积核作三次卷积+ReLU,尺寸变为28x28x512
8、作2x2的max pooling池化,尺寸变为14x14x512
9、经512个3x3的卷积核作三次卷积+ReLU,尺寸变为14x14x512
10、作2x2的max pooling池化,尺寸变为7x7x512
11、与两层1x1x4096,一层1x1x1000进行全连接+ReLU(共三层)
12、通过softmax输出1000个预测结果
以上就是VGG16(网络结构D)各层的处理过程,A、A-LRN、B、C、E其它网络结构的处理过程也是类似,执行过程如下(以VGG16为例):
从上面的过程可以看出VGG网络结构还是挺简洁的,都是由小卷积核、小池化核、ReLU组合而成。其简化图如下(以VGG16为例):
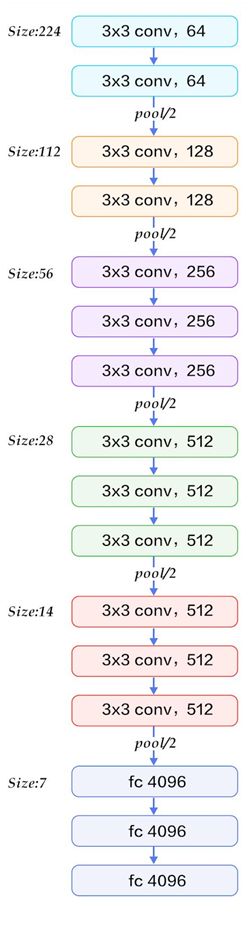
A、A-LRN、B、C、D、E这6种网络结构的深度虽然从11层增加至19层,但参数量变化不大,这是由于基本上都是采用了小卷积核(3x3,只有9个参数),这6种结构的参数数量(百万级)并未发生太大变化,这是因为在网络中,参数主要集中在全连接层。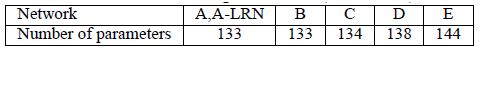
经作者对A、A-LRN、B、C、D、E这6种网络结构进行单尺度的评估,错误率结果如下: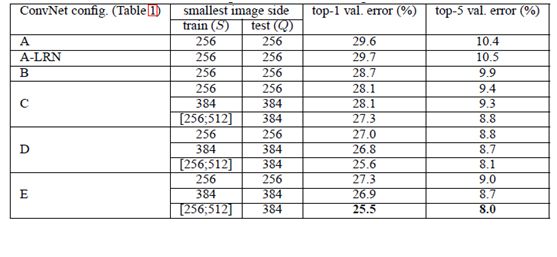
从上表可以看出:
1、LRN层无性能增益(A-LRN)
VGG作者通过网络A-LRN发现,AlexNet曾经用到的LRN层(local response normalization,局部响应归一化)并没有带来性能的提升,因此在其它组的网络中均没再出现LRN层。
2、随着深度增加,分类性能逐渐提高(A、B、C、D、E)
从11层的A到19层的E,网络深度增加对top1和top5的错误率下降很明显。
3、多个小卷积核比单个大卷积核性能好(B)
VGG作者做了实验用B和自己一个不在实验组里的较浅网络比较,较浅网络用conv5x5来代替B的两个conv3x3,结果显示多个小卷积核比单个大卷积核效果要好。
最后进行个小结:
1、通过增加深度能有效地提升性能;
2、最佳模型:VGG16,从头到尾只有3x3卷积与2x2池化,简洁优美;
3、卷积可代替全连接,可适应各种尺寸的图片
墙裂建议
2014年,K. Simonyan等人发表了关于VGGNet的经典论文《Very Deep Convolutional Networks for Large-Scale Image Recognition》(基于甚深层卷积网络的大规模图像识别),在该论文中对VGG的思想、测试情况进行了详细介绍,建议阅读这篇论文加深了解。
扫描以下二维码关注本人公众号“大数据与人工智能Lab”(BigdataAILab),然后回复“论文”关键字可在线阅读这篇经典论文的内容。

推荐相关阅读
- 大话卷积神经网络(CNN)
- 大话循环神经网络(RNN)
- 大话深度残差网络(DRN)
- 大话深度信念网络(DBN)
- 大话CNN经典模型:LeNet
- 大话CNN经典模型:AlexNet
- 浅说“迁移学习”
- 什么是“强化学习”
- AlphaGo算法原理浅析
- 大数据究竟有多少个V
- Apache Hadoop 2.8 完全分布式集群搭建超详细教程
- Apache Hive 2.1.1 安装配置超详细教程
- Apache HBase 1.2.6 完全分布式集群搭建超详细教程
- 离线安装Cloudera Manager 5和CDH5(最新版5.13.0)超详细教程