【CIFAR-10】
Preprocess of the data:
1. Normalize, one-hot encoding
Normalize: Min-Max Normalization (y = (x-min) / (max-min)) ,By applying Min-Max normalization, the original image data is going to be transformed in range of 0 to 1 (inclusive).
why normalize?
when you think about the image data, all values originally ranges from 0 to 255. This sounds like when it is passed into sigmoid function, the output is almost always 1, and when it is passed into ReLU function, the output could be very huge. When back-propagation process is performed to optimize the networks, this could lead to an exploding/vanishing gradient problems. In order to avoid the issue, it is better let all the values be around 0 and 1.
2. divide the data to train/val/test sets
def normalize(x):
min_val = np.min(x)
max_val = np.max(x)
x = (x - min_val) / (max_val - min_val)
return x
def one_hot_encode(x):
encoded = np.zeros((len(x), 10))
for idx, val in enumerate(x):
encoded[idx][val] = 1
return encodedUse three convolution layers and two fully connected layers, use the softmax function to get the output. I make the architecture as follows:
def conv_net(x, keep_prob):
w1 = tf.Variable(tf.truncated_normal([5, 5, 3, 64], mean=0, stddev=0.008))
b1 = tf.Variable(tf.constant(0.0, shape=[64]))
conv1 = tf.nn.conv2d(x, filter=w1, strides=[1, 1, 1, 1], padding='SAME', name="conv1")
relu1 = tf.nn.relu((tf.add(conv1, b1)))
pool1 = tf.nn.max_pool(relu1, ksize=[1, 3, 3, 1], strides=[1, 2, 2, 1], padding='SAME', name="pool1")
norm1 = tf.nn.lrn(pool1, 4, bias=1.0, alpha=0.001 / 9.0, beta=0.75)
print("norm1 shape: {}".format(norm1.get_shape().as_list()))
# 第二层卷积
w2 = tf.Variable(tf.truncated_normal([5, 5, 64, 128], mean=0, stddev=0.008))
b2 = tf.Variable(tf.constant(0.0, shape=[128]))
conv2 = tf.nn.conv2d(norm1, w2, strides=[1, 1, 1, 1], padding='SAME', name="conv2")
relu2 = tf.nn.relu((tf.add(conv2, b2)))
pool2 = tf.nn.max_pool(relu2, ksize=[1, 3, 3, 1], strides=[1, 2, 2, 1], padding='SAME', name="pool2")
norm2 = tf.nn.lrn(pool2, 4, bias=1.0, alpha=0.001 / 9.0, beta=0.75)
print("norm2 shape: {}".format(norm2.get_shape().as_list()))
# 第三层卷积
w3 = tf.Variable(tf.truncated_normal([5, 5, 128, 128], mean=0, stddev=0.008))
b3 = tf.Variable(tf.constant(0.0, shape=[128]))
conv3 = tf.nn.conv2d(norm2, w3, strides=[1, 1, 1, 1], padding='SAME', name="conv3")
relu3 = tf.nn.relu((tf.add(conv3, b3)))
pool3 = tf.nn.max_pool(relu3, ksize=[1, 3, 3, 1], strides=[1, 2, 2, 1], padding='SAME', name="pool3")
norm3 = tf.nn.lrn(pool3, 4, bias=1.0, alpha=0.001 / 9.0, beta=0.75)
print("norm3 shape: {}".format(norm3.get_shape().as_list()))
# 全连接层1
shapes = norm3.get_shape().as_list()
x_fc1 = tf.reshape(norm3, shape=[-1, shapes[1] * shapes[2] * shapes[3]])
print("x_fc1 shape: {}".format(x_fc1.get_shape().as_list()))
dim = x_fc1.get_shape()[1].value
w_fc1 = tf.Variable(tf.truncated_normal([dim, 1024], mean=0, stddev=0.008))
b_fc1 = tf.Variable(tf.constant(0.0, shape=[1024]))
relu4 = tf.nn.relu(tf.matmul(x_fc1, w_fc1) + b_fc1)
drop_fc1 = tf.nn.dropout(relu4, keep_prob)
print("relu3 shape: {}".format(relu3.get_shape().as_list()))
# 全连接层2
w_fc2 = tf.Variable(tf.truncated_normal([1024, 512], mean=0, stddev=0.008))
b_fc2 = tf.Variable(tf.constant(0.0, shape=[512]))
relu5 = tf.nn.relu(tf.matmul(drop_fc1, w_fc2) + b_fc2)
drop_fc2 = tf.nn.dropout(relu5, keep_prob)
print("relu4 shape: {}".format(relu4.get_shape().as_list()))
# 最后一层
w_fc3 = tf.Variable(tf.truncated_normal([512, 10], mean=0, stddev=0.008))
b_fc3 = tf.Variable(tf.constant(0.0, shape=[10]))
out = tf.matmul(drop_fc2, w_fc3) + b_fc3
return outloss: cross_entropy
optimizer: AdamOptimizer:
cost = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits=logits, labels=y)) optimizer = tf.train.AdamOptimizer(learning_rate=learning_rate).minimize(cost)cost = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits=logits, labels=y)) 具体的执行流程大概分为两步: 第一步是先对网络最后一层的输出做一个softmax,这一步通常是求取输出属于某一类的概率 第二步是softmax的输出向量[Y1,Y2,Y3...]和样本的实际标签做一个交叉熵 这个函数的返回值并不是一个数,而是一个向量,如果要求交叉熵, 我们要再做一步tf.reduce_sum操作,就是对向量里面所有元素求和, 最后才得到,如果求loss,则要做一步tf.reduce_mean操作, 对向量求均值!
dropout probablity: 0.7
learning rate: 0.001
batch_size: 128
calculate accuracy:
tf.argmax(input, axis=None, name=None, dimension=None) 此函数是对矩阵按行或列计算最大值 参数 input:输入Tensor axis:0表示按列,1表示按行 name:名称 dimension:和axis功能一样,默认axis取值优先。新加的字段 返回:Tensor 一般是行或列的最大值下标向量correct_pred = tf.equal(tf.argmax(logits, 1), tf.argmax(y, 1)) accuracy = tf.reduce_mean(tf.cast(correct_pred, tf.float32), name='accuracy')
一些问题:
关于深度学习常用的激活函数:
- Rectified Linear Unit(ReLU) - 用于隐层神经元输出
- Sigmoid - 用于隐层神经元输出
- Softmax - 用于多分类神经网络输出
- Linear - 用于回归神经网络输出(或二分类问题)
ReLU函数计算如下:

优点:收敛速度快,相比于sigmoid可以解决梯度消失的问题
缺点:训练时候很“脆弱”,很容易“die” (学习率如果设置地过大或者梯度过大,会使得当前得到的W为负值,然后y=Wx+b,导致得到的y是负值,也就是会使得激活函数的输入为负值,那么ReLu的输出为0,也就是该神经元有可能不会被任何数据激活。当然, 权值也不会被更新)
Sigmoid函数计算如下:
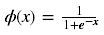
Softmax函数计算如下:

Softmax激活函数只用于多于一个输出的神经元,它保证所以的输出神经元之和为1.0,所以一般输出的是小于1的概率值,可以很直观地比较各输出值。
几种optimizer的原理以及区别?
AdamOptimizer
此函数是Adam优化算法:是一个寻找全局最优点的优化算法,引入了二次方梯度校正。
相比于基础SGD算法,1.不容易陷于局部优点。2.速度更快
卷积层过后输出的大小?
在卷积层,假设输入为WxW, 滤波器为FxF,zero-padding的数目为P,strides为S,则输出的大小为(W-F+2P)/S + 1
当strides为1时一般设zero-padding为P=(F-1)/2,来保证输入和输出大小一样
为什么在卷积层设strides=1?
Smaller strides work better in practice. Additionally, stride 1 allows us to leave all spatial down-sampling to the POOL layers, with the CONV layers only transforming the input volume depth-wise.
为什么使用padding?
In addition to the benefit of keeping the spatial sizes constant after CONV, doing this actually improves performance. If the CONV layers were to not zero-pad the inputs and only perform valid convolutions, then the size of the volumes would reduce by a small amount after each CONV, and the information at the borders would be “washed away” too quickly.
Pooling 层过后输出的大小:
(W-F)/S + 1 (F是Pooling滤波器的大小,S是步长)
一般pooling层用的比较多的是 2x2 with strides=2,and 3x3 with strides=2(overlaping pooling), 一般不会大于3x3
为什么使用pooling?
1. 减少参数和计算量
2. 微小位移不变性
3.防止过拟合
一般的CNN遵循以下结构:
INPUT -> [[CONV -> RELU]*N -> POOL?]*M -> [FC -> RELU]*K -> FC
In practice: use whatever works best on ImageNet.
Instead of rolling your own architecture for a problem, you should look at whatever architecture currently works best on ImageNet, download a pretrained model and finetune it on your data. You should rarely ever have to train a ConvNet from scratch or design one from scratch.