ArnetMiner: Extraction and Mining of Academic Social Networks
ArnetMiner: Extraction and Mining of Academic Social Networks

ABSTRACT
This paper addresses several key issues in the ArnetMiner system, which aims at extracting and mining academic social networks. Specifically, the system focuses on: 1) Extracting researcher profiles automatically from the Web; 2) Integrating the publication data into the network from existing digital libraries; 3) Modeling the entire academic network; and 4) Providing search services for the academic network. So far, 448,470 researcher profiles have been extracted using a unified tagging approach. We integrate publications from online Web databases and propose a probabilistic framework to deal with the name ambiguity problem. Furthermore, we propose a unified modeling approach to simultaneously model topical aspects of papers, authors, and publication venues. Search services such as expertise search and people association search have been provided based on the modeling results. In this paper,we describe the architecture and main features of the system. We also present the empirical evaluation of the proposed methods.
CategoriesandSubjectDescriptors
H.3.3 [Information Search and Retrieval]: Text Mining, Digital Libraries; H.2.8 [DatabaseManagement]: Database Applications
GeneralTerms
Algorithms, Experimentation
Keywords
Social Network, Information Extraction, Name Disambiguation, Topic Modeling, Expertise Search, Association Search
1. INTRODUCTION
Extraction and mining of academic social networks aims at providing comprehensive services in the scientific research field. In an academic social network, people are not only interested in searching for different types of information(such as authors,conferences, and papers), but are also interested in finding semantics-based information (such as structured researcher profiles).
Many issues in academic social networks have been investigated and several systems have been developed (e.g., DBLP, CiteSeer, and Google Scholar). However, the issues were usually studied separately and the methods proposed are not sufficient for mining the entire academic network. Two reasons are as follows: 1) Lack of semantics-based information. The social information obtained from user-entered profiles or by extraction using heuristics is sometimes incomplete or inconsistent; 2) Lack of a unified approach to efficiently model the academic network. Previously, different types of information in the academic network were modeled individually, thus dependencies between them cannot be captured accurately. In this paper, we try to address the two challenges in novel approaches. We have developed an academic search system, called ArnetMiner (http://www.arnetminer.org). Our objective in this system is to answer the following questions: 1) how to automatically extract researcher profiles from the Web? 2) how to integrate the extracted information (e.g., researchers’ profiles and publications) from different sources? 3) how to model different types of information in a unified approach? and 4) how to provide powerful search services based on the constructed network?
(1) We extend the Friend-Of-A-Friend (FOAF) ontology [9] as the profile schema and propose a unified approach based on Conditional Random Fields to extract researcher profiles from the Web.
(2) We integrate the extracted researcher profiles and the crawled publication data from the online digital libraries. We propose a unified probabilistic framework for dealing with the name ambiguity problem in the integration.
(3) We propose three generative probabilistic models for simultaneously modeling topical aspects of papers, authors, and publication venues.
(4) Based on the modeling results, we implement several search services such as expertise search and association search. We conducted empirical evaluations of the proposed methods. Experimental results show that our proposed methods significantly outperform the baseline methods for dealing with the above issues.
Our contributions in this paper include: (1) a proposal of a unified tagging approach to researcher profile extraction, (2) a proposal of a unified probabilistic framework to name disambiguation, and (3) a proposal of three probabilistic topic models to simultaneously model the different types of information. The paper is organized as follows. In Section 2, we review the related work. In Section 3, we give an overview of the system. In Section 4, we present our approach to researcher profiling. In Section 5, we describe the probabilistic framework to name disambiguation. In Section 6, we propose three generative probabilistic models to model the academic network. Section 7 illustrates several search services provided in ArnetMiner based on the modeling
results. We conclude the paper in Section 8.
2. RELATED WORK
2.1 Person Profile Extraction
Several research efforts have been made for extracting person profiles. For example, Yu et al. [32] propose a two-stage extraction method for identifying personal information from resumes. The first stage segments a resume into different types of blocks and the second stage extracts the detailed information such as Address and Email from the identified blocks. However, the method formalizes the profile extraction as several separate steps and conducts extraction in a more or less ad-hoc manner.
A few efforts also have been placed on the extraction of contact information from emails or from the Web. For example, Kristjansson et al. [19] have developed an interactive information extraction system to assist the user to populate a contact database from emails.
In comparison, profile extraction consists of contact information extraction as well as other different subtasks.
2.2 Name Disambiguation
A number of approaches have been proposed to name disambiguation. For example, Bekkerman and McCallum [6] present two unsupervised methods to distinguish Web pages to different persons with the same name: one is based on the link structure of the Web pages and the other is based on the textural content. However,
the methods cannot incorporate the relationships between data.
Han et al. [15] propose an unsupervised learning approach using K-way spectral clustering. Tan et al. [27] propose a method for name disambiguation based on hierarchical clustering. However, this kind of methods cannot capture the relationships either. Two supervised methods are proposed by Han et al. [14]. For each given name, the methods learn a specific classification model from the training data and use the model to predict whether a new paper is authored by a specific author with the name. However, the methods are user-dependent. It is impractical to train thousands of models for all individuals in a large digital library.
2.3 Topic Modeling
Considerable work has been conducted for investigating topic models or latent semantic structures for text mining. For example, Hofmann [17] proposes the probabilistic latent semantic indexing (pLSI) and applies it to information retrieval (IR). Blei et al. [8] introduce a three-level Bayesian network, called Latent Dirichlet Allocation (LDA). The basic generative process of LDA closely resembles pLSI except that in pLSI, the topic mixture is conditioned on each document while in LDA, the topic mixture is drawn from a conjugate Dirichlet prior that remains the same for all documents.
Some other work has been conducted for modeling both author interests and document contents together. For example, the Author model [21] is aimed at modeling the author interests with a one-toone correspondence between topics and authors. The Author-Topic model [25] [26] integrates the authorship into the topic model and
can find a topic mixture over documents and authors.
Compared with the previous topic modeling work, in this paper, we propose a unified topic model to simultaneously model the topical aspects of different types of information in the academic network.
2.4 Academic Search
For academic search, several research issues have been intensively investigated, for example expert finding and association search. Expert finding is one of the most important issues for mining social networks. For example, both Nie et al. [24] and Balog et al.
[4] propose extended language models to address the expert finding problem. From 2005, Text REtrieval Conference (TREC) has provided a platform with the Enterprise Search Track for researchers to empirically assess their methods for expert finding [13].
Association search aims at finding connections between people. For example, the ReferralWeb [18] system helps people search and explore social networks on the Web. Adamic and Adar [1] have investigated the problem of association search in email networks.
However, existing work mainly focuses on how to find connections between people and ignores how to rank the found associations. In addition, a few systems have been developed for academic search such as, scholar.google.com, libra.msra.cn, citeseer.ist.psu, and Rexa.info. Though much work has been performed, to the best of our knowledge, the issues we focus on in this work (i.e., profile extraction, name disambiguation, and academic network modeling) have not been sufficiently investigated. Our system addresses all these problems holistically.
3. OVERVIEW OF ARNETMINER
Figure 1 shows the architecture of our ArnetMiner system. The system mainly consists of five main components:
- Extraction: it focuses on extracting researcher profiles from the Web automatically. It first collects and identifies one’s homepage from the Web, then uses a unified approach to extract the profile properties from the identified document. It extracts publications from online digital libraries using rules.
- Integration: it integrates the extracted researchers’ profiles and the extracted publications by using the researcher name as the identifier. A probabilistic framework has been proposed to deal with the name ambiguity problem in the integration. The integrated data is stored into a researcher network knowledge base (RNKB).
- Storage and Access: it provides storage and index for the extracted/integrated data in the RNKB. Specifically, for storage it employs MySQL and for index, it employs the inverted file indexing method [3].
- Modeling: it utilizes a generative probabilistic model to simultaneously model different types of information. It estimates a topic distribution for each type of information.
- Search Services: based on the modeling results, it provides several search services: expertise search and association search. It also provides other services, e.g., author interest finding and academic suggestion (such as paper suggestion and citation suggestion).
It is challenging in many ways to implement these components. First, the previous extraction work has been usually conducted on a specific data set. It is not immediately clear whether such methods can be directly adapted to the global Web. Secondly, it is unclear how to deal with the disambiguation problem by making full use of the extracted information. For example, how to use the relationships between publications. Thirdly, there is no existing model that can simultaneously model the different types of information in the academic network. Finally, different strategies for modeling the academic network have different behaviors. It is necessary to study how different they are and which one would be the best for academic search.
Based on these considerations, for profile extraction, name disambiguation, and modeling, we propose new approaches to overcome the drawbacks that exist in the traditional methods. For storage and access, we utilize the classical methods, because these issues have been intensively investigated and the existing methods can result in good performance in our system.

4. RESEARCHER PROFILE EXTRACTION
4.1 Problem Definition
Profile extraction is the process of extacting the value of each property in a person profile. We define the schema of the researcher profile (as shown in Figure 2) by extending the FOAF ontology [9].
We perform a statistical study on randomly selected 1, 000 researchers from ArnetMiner and find that it is non-trivial to perform profile extraction from the Web. We observed that 85.62% of the researchers are faculty members from universities and 14.38% are from company research centers. For researchers from the same
company, they may share a template-based homepage. However, different companies have different templates. For researchers from universities, the layout and the content of their homepages vary largely. We have also found that 71.88% of the 1, 000 Web pages are researchers’ homepages and the rest are pages introducing the researchers. Characteristics of the two types of pages significantly differ from each other.
We also analyze the content of the Web pages and find that about 40% of the profile properties are presented in tables/lists and the others are presented in natural language text. This suggests a method without using global context information in the page would be ineffective. Statistical study also unveils that (strong) dependencies exist between different profile properties. For example, there are 1, 325 cases (14.54%) in our data of which the extraction needs to use the extraction results of other properties. An ideal method should consider processing all the subtasks holistically.
4.2 A Unified Approach to Profiling
4.2.1 Process
The proposed approach consists of three steps: relevant page identification, preprocessing, and extraction. In relevant page identification, given a researcher name, we first get a list of web pages by a search engine (we use the Google API) and then identify the homepage/introducing page using a binary classifier. We use Sup-port Vector Machines (SVM) [12] as the classification model and define features such as whether the title of the page contains the person name and whether the URL address (partly) contains the person name. The performance of the classifier is 92.39% by F1-
measure. In preprocessing, (a) we separate the text into tokens and (b) we assign possible tags to each token. The tokens form the basic units and the pages form the sequences of units in the tagging problem. In tagging, given a sequence of units, we determine the most likely corresponding sequence of tags by using a trained tagging model. Each tag corresponds to a property defined in Figure 2, e.g., ‘Position’. In this paper, we make use of Conditional Random Fields (CRFs) [20] as the tagging model. Next we describe the steps (a) and (b) in detail.
(a) We identify tokens in the Web page using heuristics. We
define five types of tokens: ‘standard word’, ‘special word’, ‘’ token, term, and punctuation mark. Standard words are unigram words in natural language. Special words include email, URL, date, number, percentage, words containing special terms (e.g. ‘Ph.D.’ and ‘.NET’), special symbols (e.g. ‘===’ and ‘###’). We identify special words by using regular expressions. ‘
’ tokens (used for identifying person photos and email addresses) are ‘
’ tags in the HTML file. Terms are base noun phrases extracted from the Web page by using a tool based on technologies proposed in [30].
(b) We assign tags to each token based on the token type. For example, for a standard word, we assign all possible tags corresponding to all properties. For a special word, we assign tags indicating Position, Affiliation, Email, Address, Phone, Fax, Bsdate, Msdate, and Phddate. For a ‘’ token, we assign two tags: Photo and Email, because an email address is sometimes shown as an image). After each token is assigned with several possible tags, we can perform most of the profiling tasks using the tags (extracting 19 properties defined in Figure 2).
4.2.2 CRF model and Features
We employ Conditional Random Fields (CRF) as the tagging model. CRF is a conditional probability of a sequence of tags given a sequence of observations [20]. For tagging, a trained CRF model is used to find the sequence of tags Y∗having the highest likelihood Y∗ = maxY P(Y |X). The CRF model is built with thelabeled data by means of an iterative algorithm based on Maximum Likelihood Estimation. Three types of features were defined in the CRF model: content features, pattern features, and term features. The features were defined for different kinds of tokens. Table 1 shows the defined features. We incorporate the defined features into the CRF model by defining Boolean-valued feature functions. Finally, 108,409 features were used in our experiments.
4.3 Profile Extraction Performance
For evaluating our profiling method, we randomly chose 1, 000 researcher names in total from our researcher network. We used the method described in Section 4.2.1 to find the researchers’ homepages or introducing pages. If the method cannot find a Web page for a researcher, we removed the researcher name from the data set. We finally obtained 898 Web pages (one for each researcher). Seven human annotators conducted annotation on the Web pages. A spec was created to guide the annotation process. On disagreements in the annotation, we conducted ‘majority voting’. In the
experiments, we conducted evaluations in terms of precision, recall, and F1-measure for each profile property. We defined baselines for profile extraction. We used the rule learning and the classification based approaches as baselines. For the former, we employed the Amilcare tool, which is based on a rule induction algorithm: LP2 [11]. For the latter, we trained a
classifier to identify the value of each property. We employed Support Vector Machines (SVM) [12] as the classification model. Experimental results show that our method results in a performance of 83.37% in terms of average F1-measure; while Amilcare and SVM result in 53.44% and 73.57%, respectively. Our method clearly outperforms the two baseline methods. We have also found that the performance of the unified method decreases (−11.28% by F1) when removing the transition features, which indicates that a unified approach is necessary for researcher profiling.
We investigated the contribution of each feature type in profile
extraction. We employed only content features, content+term features, content+pattern features, and all features to train the models and conducted the profile extraction. Figure 3 shows the average F1-scores of profile extraction with different feature types. The results unveil contributions of individual features in the extraction. We see that solely using one type of features cannot obtain accurate profiling results. Detailed evaluations can be found in [28].
5. NAME DISAMBIGUATION
5.1 Problem Definition
We integrate the publication data from the online database including DBLP bibliography, ACM Digital library, CiteSeer, and others. For integrating the researcher profiles and the publications, we use the researcher name and the publication author name as the identifier. The method inevitably has the ambiguity problem. We give a formal definition of the name disambiguation task in our context. Given a person name a, we denote all publications having the author name a as P = {p1, p2, · · · , pn}. Each publication pi has six attributes: paper title (pi.title), publication venue

We define five types of relationships between papers (Table 2). Relationship r1 represents two papers are published at the same venue. Relationship r2 means two papers have a secondary author with the same name, and relationship r3 means one paper cites the other paper. Relationship r4 indicates a constraint-based relationship supplied via user feedback. For instance, the user can specify that two specific papers should be assigned to a same person. We use an example to explain relationship r5. Suppose pi has authors ‘David Mitchell’ and ‘Andrew Mark’, and pj has authors ‘David
Mitchell’ and ‘Fernando Mulford’. We are to disambiguate ‘David Mitchell’. If ‘Andrew Mark’ and ‘Fernando Mulford’ also coauthor a paper, then we say pi and pj have a 2-CoAuthor relationship. In our currently experiments, we empirically set the weights of relationships w1 ∼ w5 as 0.2, 0.7, 0.3, 1.0, 0.7 τ. The publication data with relationships can be modeled as a graph comprising of nodes and edges. Each attribute of a paper is attached to the corresponding node as a feature vector. In the vector, we use words (after stop words filtering and stemming) in the attributes as features and use their numbers of occurrences as the values.



5.2 A Unified Probabilistic Framework
5.2.1 Formalization using HMRF
We propose a probabilistic framework based on Hidden Markov Random Fields (HMRF) [5], which can capture dependencies between observations (with each paper being viewed as an observation). The disambiguation problem is cast as assigning a tag to each paper with each tag representing an actual researcher. Specifically, we define a-posteriori probability as the objective function. We aims at maximizing the objective function. The five types of relationships are incorporated into the objective function. According to HMRF, the conditional distribution of the researcher labels y given the observations x (papers) is

where D(xi, yh) is the distance between paper xi and researcher yh and D(xi, xj )is the distance between papers xi and xj ; rk(xi, xj ) denotes a relationship between xi and xj ; wk is the weight of the relationship; and Z is a normalization factor.

5.2.2 EM framework
Three tasks are executed by the Expectation Maximization method: estimation of parameters in the distance measure, re-assignment of papers to researchers, and update of researcher representatives yh. We define the distance function D(xi, xj ) as follows:
here A is defined as a diagonal matrix, for simplicity. Each element in A denotes the weight of the corresponding feature in x. The EM process can be summarized as follows: in the E-step, given the researcher representatives, each paper is assigned to a researcher by maximizing P(y|x). In the M-step, the researcher representative yh is re-estimated from the assignments, and the distance measure is updated to maximize the objective function again.

The assignment of a paper is performed while keeping assignments of the other papers fixed. The assignment process is repeated after all papers are assigned. This process runs until no paper changes its assignment between two successive iterations. In the M-step, each researcher representative is updated by the

5.3 Name Disambiguation Performance
To evaluate our method, we created a data set that consists of 14 real person names (six are from the author’s lab and the others are from [31]). Statistics of this data set are shown in Table 3. Five human annotators conducted disambiguation for the names. A spec was created to guide the annotation process. The labeling work was carried out based on authors’ affiliations, emails, and publications on their homepages.
We defined a baseline based on the method from [27] except that [27] also utilizes a search engine to help the disambiguation. The method is based on hierarchical clustering. We also compared our approach with the DISTINCT method [31]. In all experiments, we
suppose that the number of persons k is provided empirically. Table 4 shows the results. We see that our method significantly outperforms the baseline method for name disambiguation (+10.75% in terms of the average F1-score). The baseline method suffers from two disadvantages: 1) it cannot take advantage of relationships between papers and 2) it relies on a fixed distance measure. Figure 4 shows the comparison results of our method and DISTINCT [31]. We used the person names evaluated in both [31] and our experiments for comparison. We see that for some names, our approach significantly outperforms DISTINCT (e.g., ‘Michael Wagner’); while for other names our approach underperforms DISTINCT (e.g. ‘Bin Yu’). We further investigated the contribution of each relationship type.
We first removed all relationships and then added them to our approach one by one: CoPubvenue, Citation, CoAuthor, and τ -CoAuthor. At each step, we evaluated the performance of our approach (cf. Figure 5). We see that without using the relationships the disambiguation performance drops sharply (−44.72% by F1) and by adding the relationships, improvements can be obtained at each step. This confirms us that a framework by integrating relationships for name disambiguation is worthwhile and each defined relationship in our method is helpful. We can also see that the CoAuthor relationship is the major contributor (+24.38% by F1).
6. MODELING ACADEMIC NETWORK
Modeling the academic network is critical to any searching or suggesting tasks. Traditionally, information is usually represented based on the ‘bag of words’ (BOW) assumption. The method tends to be overly specific in terms of matching words.

Recently, probabilistic topic models such as probabilistic Latent Semantic Indexing (pLSI) [17], Latent Dirichlet Allocation (LDA) [8], and Author-Topic model [25] [26] have been proposed as well as successfully applied to multiple text mining tasks such as information retrieval [29], collaborative filtering [8] [16], and paper reviewer finding [22]. However, these models are not sufficient to
model the whole academic network, as they cannot model topical aspects of all types of information in the academic network. We propose a unified topic model for simultaneously modeling the topical distribution of papers, authors, and conferences. For simplicity, we use conference to denote conference, journal, and book hereafter. The learned topic distribution can be used to further estimate the inter-dependencies between different types of information, e.g., the closeness between a conference and an author.

6.1 Our Proposed Topic Models
The proposed model is called Author-Conference-Topic (ACT) model. Three different strategies are employed to implement the topic model (as shown in Figure 6). In the first model (ACT1, Figure 6 (a)), each author is associated with a multinomial distribution over topics and each word in a paper and the conference stamp is generated from a sampled topic. In the second model (ACT2, Figure 6 (b)), each author conference pair is associated with a multinomial distribution over topics and
each word is then generated from a sampled topic.
In the third model (ACT3, Figure 6 ©), each author is associated with a topic distribution and the conference stamp is generated after topics have been sampled for all word tokens in a paper. The different implementations reduces the process of writing a scientific paper to different series of probabilistic steps. They have different behaviors in the academic applications. In the remainder
of this section, we will describe the three models in more detail.
6.2 ACT Model 1
In the first model (Figure 6(a)), the conference information is viewed as a stamp associated with each word in a paper. Intuition behind the first model is: coauthors of a paper determine topics written in this paper and each topic then generates the words and determines a proportion of the publication venue. The generative process can be summarized as follows:

posterior probability is calculated by the following:

6.3 ACT Model 2
In the second model (cf. Figure 6(b)), each topic is chosen from a multinomial topic distribution specific to an author-conference pair, instead of an author as that in ACT1. The model is derived from the observation: when writing a paper, coauthors usually first choose a publication venue and then write the paper based on themes of the publication venue and interests of the authors. The corresponding generative process is:

6.4 ACT Model 3
In the third model (cf. Figure 6©), the conference stamp is
taken as a numerical value. Each conference stamp of a paper is chosen after topics have been sampled for all word tokens in the paper. Intuitively, this corresponds to a natural way of publishing the scientific paper: authors first write a paper and then determine where to publish the paper based on the topics discussed in the paper. The corresponding generative process is:


In this model, the conference comes from a normal linear model. The covariates τ in this model are the frequencies of the topics in the document. The regression coefficients on these frequencies constitute η. The difference of parameterization from ACT1 is that the conference stamp is sampled from a normal linear distribution after topics were sampled for all word tokens in a paper.

7. ACADEMIC SEARCH SERVICES
7.1 Applying ACT Models to Expertise Search
In expertise search, the objective is to find the expertise authors, expertise papers, and expertise conferences for a given query.
7.1.1 Process
Based on the proposed models, we can calculate the likelihood of a paper generating a word using ACT1 as the example as following:

The likelihood of an author model and a conference model generating a word can be similarly defined. However, the learned topics by the LDA-style model is usually general and not specific to a given query. Therefore, only using ACT itself is too coarse for academic search [29]. Our preliminary experiments also show that employing only ACT or LDA models to information retrieval hurts the retrieval performance. In general, we would like to have a balance between generality and specificity. Therefore, we derive a combination of the ACT model and the word-based language model:

7.1.2 Expertise Search Performance
We collected a list of the most frequent queries from the log of ArnetMiner for evaluation. We conducted experiments on a subset of the data (including 14, 134 persons, 10, 716 papers, and 1, 434 conferences) from ArnetMiner. For evaluation, we used the method of pooled relevance judgments [10] together with human judgments. Specifically, for each query, we first pooled the top 30 results from three similar systems (Libra, Rexa, and ArnetMiner). Then, two faculty members and five graduate students from CS provided human judgments. Four-grade scores (3, 2, 1, and 0) were assigned respectively representing definite expertise, expertise, marginal expertise, and no expertise. Finally, the judgment scores were averaged to obtain the final score. In all experiments, we conducted evaluation in terms of P@5, P@10, P@20, R-pre, and mean average precision (MAP) [10] [13]. We used language model (LM), LDA [8], and the Author-Topic (AT) model [25] [26] as the baseline methods. For language model, we used Equation (17) to calculate the relevance between a query term and a document and similar equations for an author/conference
(an author is represented by his/her published papers and a conference is represented by papers published on it). For LDA, we used a similar equation to Equation (16) to calculate the relevance of a term and a document. For the AT model, we used similar equations to Equation (16) to calculate the relevance of a query term with a paper or an author. For the LDA and AT models, we performed model estimation with the same setting as that for the ACT models. We empirically set the number of topics as T = 80 for all models.

Table 5 shows five topics discovered by ACT1.
Table 6 shows the experimental results of retrieving papers, authors, and conferences using our proposed methods and the baseline methods. We see that our proposed three methods outperform the baseline methods. LDA only models documents and thus can support only paper search; while AT supports paper search and author search. Both models underperform our proposed unified models. Our models benefit from the ability of modeling all kinds of information holistically, thus can capture the dependencies between the different types of information. We can also see that ACT1 achieves the best performance in all evaluation measures. For comparison purposes, we also evaluate the results of two similar systems: Libra.msra.cn and Rexa.info. The average MAP obtained by Libra and Rexa on our data set are 48.3% and 45.0%. We see that our methods clearly outperform the two systems.
7.2 Applying ACT Models to Association Search
Association Search: Given a social network G = (V, E) and an association query (ai, aj ) (source person, target person), association search is to find and rank possible associations {αk(ai, aj )} from ai to aj . Each association is denoted as a referral chain of persons. There are two subtasks in association search: finding possible as sociations between two persons and ranking the associations. Given a large social network, to find all associations is an NP-hard problem. We instead focus on finding the ‘shortest’ associations. Hence, the problem becomes how to estimate the score of an association and one key issue is how to calculate the distance between persons. We use KL divergence to define the distance as:
We use the accumulated distance between persons on an association path as the score of the association. We call the association with the smallest score as the shortest association and our problem can be formalized as that of finding the near-shortest associations. Our approach consists of two stages:

7.3 Other Applications
Our model can support many other applications, e.g., author interest finding and academic suggestion.
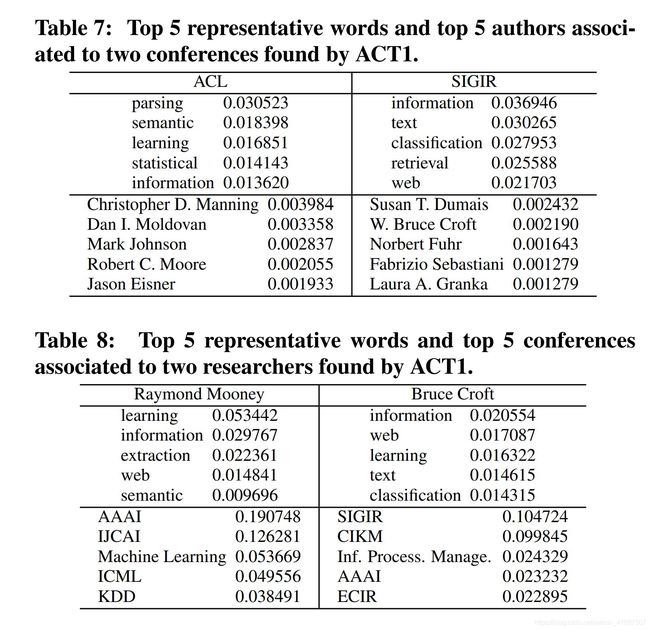
For example, Table 7 shows top 5 words and top 5 authors associated to two conferences found by ACT1. Table 8 shows top 5 words and top 5 conferences associated to two researchers found by ACT1. The results can be directly used to characterize the conference themes and researcher interests. They can be also used for prediction/suggestion tasks. For example, one can use the model to find the best matching reviewer for a paper submitted to a specific conference. Previously, such work is fulfilled by only keyword matching or topic-based retrieval such as [22], but not considering the conference. One can also use the model to suggest a venue to submit a paper based on its content and authors’ interests. Or one can use it to suggest popular topics when authors prepare a paper for a conference.
8. CONCLUSION
In this paper, we describe the architecture and the main features of the ArnetMiner system. Specifically, we propose a unified tagging approach to researcher profiling. About a half million researcher profiles have been extracted into the system. The system has also integrated more than one million papers. We propose a probabilistic framework to deal with the name ambiguity problem in the integration. We further propose a unified topic model to simultaneously model the different types of information in the academic network. The modeling results have been applied to expertise search and association search. We conduct experiments for evaluating each of the proposed approaches. Experimental results indicate that the proposed methods can achieve a high performance.
There are many potential future directions of this work. It would be interesting to further investigate new extraction models for improving the accuracy of profile extraction. It would be also interesting to investigate how to determine the actual person number k for name disambiguation. Currently, the number is supplied manually, which is not practical for all author names. In addition, extending the topic model with link information (e.g., citation information) or time information is a promising direction.
9. ACKNOWLEDGMENTS
The work is supported by the National Natural Science Foundation of China (90604025, 60703059), Chinese National Key Foundation Research and Development Plan (2007CB310803), and Chinese Young Faculty Research Funding (20070003093). It is also supported by IBM Innovation funding.
10. REFERENCES
[1] L. A. Adamic and E. Adar. How to search a social network. Social Networks, 27:187–203, 2005.
[2] C. Andrieu, N. de Freitas, A. Doucet, and M. I. Jordan. An introduction to mcmc for machine learning. Machine Learning, 50:5–43, 2003.
[3] R. Baeza-Yates and B. Ribeiro-Neto. Modern Information Retrieval.
ACM Press, 1999.
[4] K. Balog, L. Azzopardi, and M. de Rijke. Formal models for expert
finding in enterprise corpora. In Proc. of SIGIR’06, pages 43–55,
2006.
[5] S. Basu, M. Bilenko, and R. J. Mooney. A probabilistic framework
for semi-supervised clustering. In Proc. of KDD’04, pages 59–68,
2004.
[6] R. Bekkerman and A. McCallum. Disambiguating web appearances
of people in a social network. In Proc. of WWW’05, pages 463–470,
2005.
[7] D. M. Blei and J. D. McAuliffe. Supervised topic models. In Proc. of
NIPS’07, 2007.
[8] D. M. Blei, A. Y. Ng, and M. I. Jordan. Latent dirichlet allocation.
Journal of Machine Learning Research, 3:993–1022, 2003.
[9] D. Brickley and L. Miller. Foaf vocabulary specification. In
Namespace Document, http://xmlns.com/foaf/0.1/, September 2004.
[10] C. Buckley and E. M. Voorhees. Retrieval evaluation with incomplete
information. In Proc. of SIGIR’04, pages 25–32, 2004.
[11] F. Ciravegna. An adaptive algorithm for information extraction from
web-related texts. In Proc. of IJCAI’01 Workshop, August 2001.
[12] C. Cortes and V. Vapnikn. Support-vector networks. Machine
Learning, 20:273–297, 1995.
[13] N. Craswell, A. P. de Vries, and I. Soboroff. Overview of the
trec-2005 enterprise track. In TREC’05, pages 199–205, 2005.
[14] H. Han, L. Giles, H. Zha, C. Li, and K. Tsioutsiouliklis. Two
supervised learning approaches for name disambiguation in author
citations. In Proc. of JCDL’04, pages 296–305, 2004.
[15] H. Han, H. Zha, and C. L. Giles. Name disambiguation in author
citations using a k-way spectral clustering method. In Proc. of
JCDL’05, pages 334–343, 2005.
[16] T. Hofmann. Collaborative filerting via gaussian probabilistic latent
semantic analysis. In Proc.of SIGIR’03, pages 259–266, 1999.
[17] T. Hofmann. Probabilistic latent semantic indexing. In Proc.of
SIGIR’99, pages 50–57, 1999.
[18] H. Kautz, B. Selman, and M. Shah. Referral web: Combining social
networks and collaborative filtering. Communications of the ACM,
40(3):63–65, 1997.
[19] T. Kristjansson, A. Culotta, P. Viola, and A. McCallum. Interactive
information extraction with constrained conditional random fields. In
Proc. of AAAI’04, 2004.
[20] J. Lafferty, A. McCallum, and F. Pereira. Conditional random fields:
Probabilistic models for segmenting and labeling sequence data. In
Proc. of ICML’01, 2001.
[21] A. McCallum. Multi-label text classification with a mixture model
trained by em. In Proc. of AAAI’99 Workshop, 1999.
[22] D. Mimno and A. McCallum. Expertise modeling for matching
papers with reviewers. In Proc. of KDD’07, pages 500–509, 2007.
[23] T. Minka. Estimating a dirichlet distribution. In Technique Report,
http://research.microsoft.com/ minka/papers/dirichlet/, 2003.
[24] Z. Nie, Y. Ma, S. Shi, J.-R. Wen, and W.-Y. Ma. Web object retrieval.
In Proc. of WWW’07, pages 81–90, 2007.
[25] M. Rosen-Zvi, T. Griffiths, M. Steyvers, and P. Smyth. The
author-topic model for authors and documents. In Proc. of UAI’04,
2004.
[26] M. Steyvers, P. Smyth, and T. Griffiths. Probabilistic author-topic
models for information discovery. In Proc. of SIGKDD’04, 2004.
[27] Y. F. Tan, M.-Y. Kan, and D. Lee. Search engine driven author
disambiguation. In Proc. of JCDL’06, pages 314–315, 2006.
[28] J. Tang, D. Zhang, and L. Yao. Social network extraction of academic
researchers. In Proc. of ICDM’07, pages 292–301, 2007.
[29] X. Wei and W. B. Croft. Lda-based document models for ad-hoc
retrieval. In Proc. of SIGIR’06, pages 178–185, 2006.
[30] E. Xun, C. Huang, and M. Zhou. A unified statistical model for the
identification of english basenp. In Proc. of ACL’00, 2000.
[31] X. Yin, J. Han, and P. Yu. Object distinction: Distinguishing objects
with identical names. In Proc. of ICDE’2007, pages 1242–1246,
2007.
[32] K. Yu, G. Guan, and M. Zhou. Resume information extraction with
cascaded hybrid model. In Proc. of ACL’05, pages 499–506, 2005.