论文笔记Globally and Locally Consistent Image Completion
论文笔记Globally and Locally Consistent Image Completion
图1 Patch-based方法的示例图
Patch-based方法的不足:(1)Depend on low-level features;(2)Unable to generate novel objects;2)基于Context Encoder的图像补全,该方法基于深度学习生成相似的纹理区域,在一定程度上可以补全缺失的区域,而且效果还不错。但是不能够保持局部一致性。

图2 Context Encoder 方法的示例图
Context Encoder方法的不足:(1)Can generate novel objects but fixed low resolution images;(2)Masks region must in the center of image;(3)补全的区域不能保持与周围区域的局部一致性。本文方法主要是基于Context Encoder方法进行相关改进。下表为三种方法的简单比较。

Table 1. Comparison of differentapproaches for completion.
文章内容:本文提出一种新颖的图像补全方法,可以保持图像在局部和全局一致。使用完全卷积神经网络,我们可以通过填充任何形状的缺失区域来完成任意分辨率的图像。为了训练这个图像补全网络,作者使用全局和局部上下文鉴别器进行训练,以区分真实图像和已补全的图像。全局鉴别器查看整个图像,以评估其是否整体一致,而局部鉴别器仅在以补全区域为中心的小区域上看,以确保生成的补丁在局部保持一致性。

图3 该方法填充的效果图
该文章完全以卷积网络作为基础,遵循GAN的思路,设计为两部分(三个网络),一部分用于生成图像,即生成网络,一部分用于鉴别生成图像是否与原图像一致,即全局鉴别器和局部鉴别器。在整个网络中,作者采用ReLU函数,在最后一层采用Sigmoid函数使得输出在0到1区间内。网络结构图如下所示。

图4 网络结构图
生成图像部分,作者采用12层卷积网络对原始图片(去除需要进行填充的部分)进行encoding,得到一张原图16分之一大小的网格。然后再对该网格采用4层卷积网络进行decoding,从而得到复原图像,下表为生成网络各层参数分布情况。输入:RGB图像,二进制掩码(需要填充的区域以1填充)输出:RGB图像
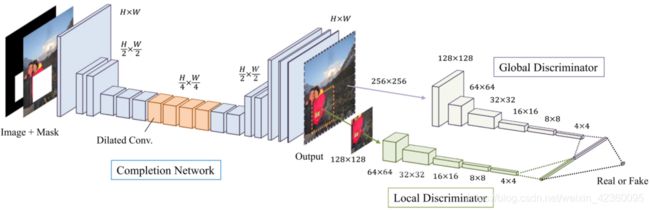
Table 2. Architecture of the image completion network.
鉴别器被分为两个部分,一个全局鉴别器(Global Discriminator)以及一个局部鉴别器(Local Discriminator)。全局鉴别器将完整图像作为输入,识别场景的全局一致性,而局部鉴别器仅在以填充区域为中心的原图像4分之一大小区域上观测,识别局部一致性。通过采用两个不同的鉴别器,使得最终网络不但可以使全局观测一致,并且能够优化其细节,最终产生更好的图片填充效果。全局鉴别网络输入是256X256,RGB三通道图片,局部网络输入是128X128,RGB三通道图片,根据论文当中的设置,全局网络和局部网络都会通过5X5的convolution layer,以及2X2的stride降低分辨率,最终分别得到1024维向量。然后,作者将全局和局部两个鉴别器输出连接成一个2048维向量,通过一个全连接然后用sigmoid函数得到整体图像一致性打分。
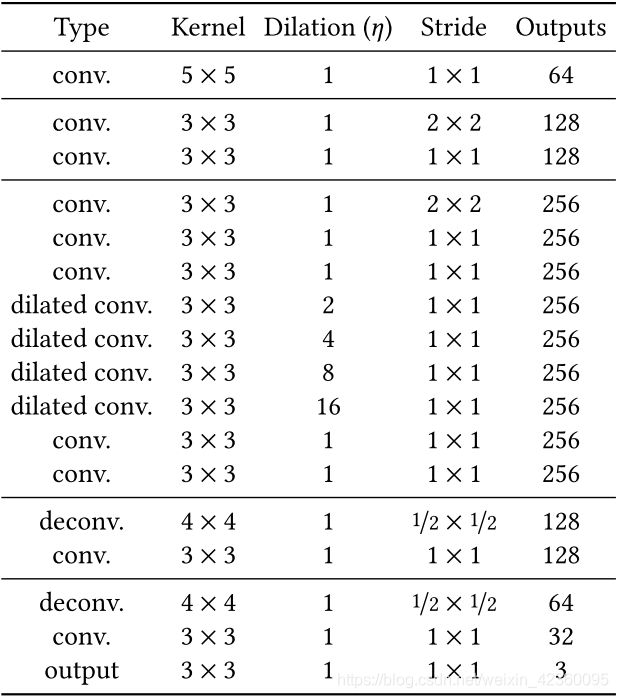
表3 局部鉴别网络结构设置
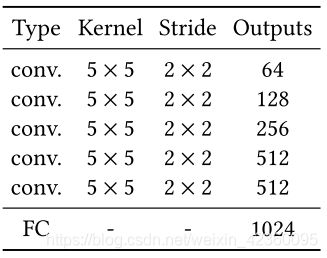
表4 全局鉴别网络结构设置

表5 连接层设置
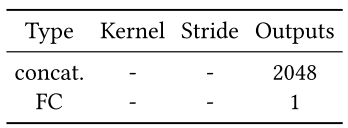
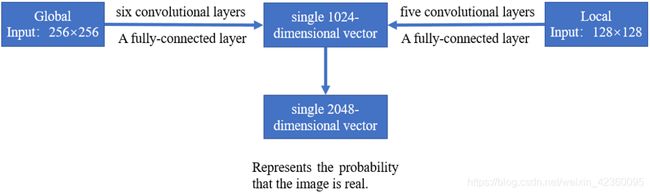
图5 鉴别器的工作示意图
该文章的特点:(1)生成网络模型仅仅降低了两次分辨率,使用大小为原始大小四分之一的卷积,其目的是为了降低最终图像的纹理模糊程度。(2)使用dilated convolutional layer(空洞卷积/扩张卷积),它能够通过相同数量的参数和计算能力感知每个像素周围更大的区域。(Multi-Scale Context Aggregation by Dilated Convolutions)文章中给出了具体的示意,为了能够计算填充图像每一个像素的颜色,该像素需要知道周围图像的内容,采用空洞卷积能够帮助每一个点有效 的“看到”比使用标准卷积更大的输入图像区域,从而填充图中点p2的颜色。
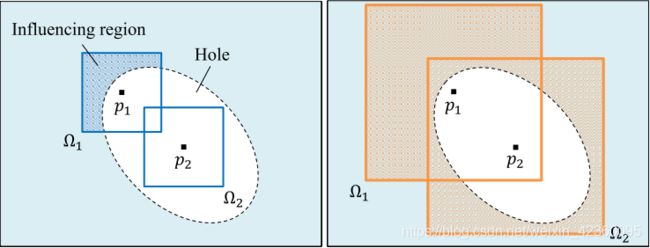
图5 Importance of spatial support
扩张卷积算子可以用下式来表示:
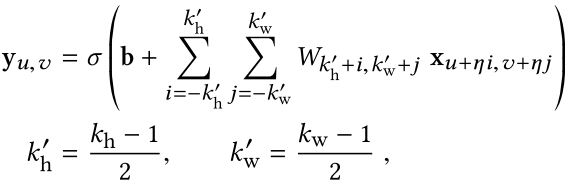
其中,η是扩张因子,当η=1,则表示标准卷积操作,文中的η1>1;Dilated convolutions:307×307pixelsstandard convolutional:99×99 pixels
损失函数:生成网络使用weighted Mean Squared Error (MSE)作为损失函数,计算原图与生成图像像素之间的差异,表达式如下所示:
![]()
公式2 MSE loss
其中,⊙ is the pixelwise multiplication,|| · || is the Euclidean norm.鉴别器网络使用GAN损失函数,其目标是最大化生成图像和原始图像的相似概率(见图5中的2048维向量,它代表的是概率),表达式如下所示:
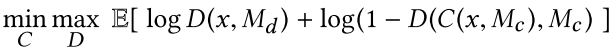
公式3 GAN loss
最后结合两者损失,形成下式:
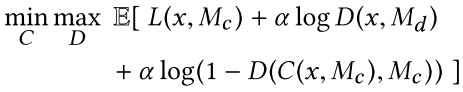
公式4 combining loss
其中α为超参,文中取值0.004.训练步骤:(1)Trained completion network with the MSE loss. (TC= 90, 000 iterations)(2)Fix the completion network and train the discriminators. (TD = 10, 000 iterations)(3) Completion network and content discriminators are trained jointly. (Ttrain = 500, 000 iterations )(4)post-processing,Blending the completed region with the color of the surrounding pixels. (首先使用fast marching method 然后使用泊松分布图像融合)其中第(1)、(2)对于该网络取得成功至关重要。Some tricks:(训练图像可以是任何尺寸)(1)将图像的较短边resize成(256,384)中的一个随机数(等比例resize)。(2)从图像上随机crop一个256*256的图片。(3)在图像上随机挖一个洞,洞的长和宽为(96,128)中的某个随机数(长宽不需一样,且相互独立)。(4)全局discriminator的输入为full 256×256-pixel。(5)局部discriminator的输入128 × 128-pixel patch.实验结果:

图6 Comparisons with existing works
网络中不同部分对补全图像的影响:

图7 Comparison of training with differentdiscriminator configurations
后处理的效果图:

图8 Effect of our simple post-processing
目标移除结果图:

图9 Examples of object removal by our approach.
人脸补全及场景补全结果图:
图10 Faces and Facades
存在的不足:(1)不能补全具有大尺寸洞的图,这主要与空洞卷积所能“看到”的区域大小有关,文中最大可看到307×307pixels。(2)不能生成复杂性的结构性纹理,这个可能与作者的网络设计的网络有关。(3)一定程度上受到训练图像库的限制。失败案例图:
图11 Failure cases

图12 Failure cases for our approach where our model is unable to complete heavily structured objects such as people.

图13 Failure cases for our approach where our model is unable to complete heavily structured objects such as people.
作者:Wonshington
链接:https://www.jianshu.com/p/d1aedac9e0ce
来源:简书