详解DBSCAN聚类算法
目录
- 1 简介
- 2 算法
- 2.1 定义
- 2.2 算法实现步骤
- 3 伪代码
- 4 实验结果
- 5 优缺点
- 6 小结
- 7 参考文献
1 简介
带噪空间基于密度的聚类方法(Density-Based Spatial Clustering of Applications with Noise,DBSCAN)是一种比较有代表性的基于密度的聚类算法。与划分和层次聚类方法不同,它将簇定义为密度相连的点的最大集合,能够把具有足够高密度的区域划分为簇,并可在带噪声的数据集空间中发现任意形状的类别簇。和K-Means,BIRCH这些一般只适用于凸样本集的聚类相比,DBSCAN既可以适用于凸样本集,也可以适用于非凸样本集。
2 算法
DBSCAN是一种基于密度的聚类算法,这类密度聚类算法一般假定类别可以通过样本分布的紧密程度决定。同一类别的样本,他们之间应该是紧密相连的,算法将这样的关系成为密度相连的。算法通过将密度相连的样本划为一类,这样就得到了一个聚类类别。再将所有样本划为多个密度相连的不同类别,就得到了最终的聚类结果。
2.1 定义
定义1:(点的Eps-邻域)点 p p p的Eps-邻域 表示样本集合 D D D中于点 p p p的距离小于 E p s Eps Eps的所有样本点的集合,用 N E p s ( p ) N_{Eps}(p) NEps(p)表示,定义为
N E p s ( p ) = { q ∈ D ∣ d i s t ( p , q ) ≤ E p s } {{N}_{Eps}}(p)=\left\{ q\in D|dist(p,q)\le Eps \right\} NEps(p)={q∈D∣dist(p,q)≤Eps}
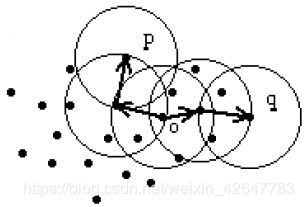
定义2:(核心点)样本点 p p p的Eps-邻域 的样本点个数用 ∣ N E p s ( p ) ∣ \left| {{N}_{Eps}}(p) \right| ∣NEps(p)∣表示,若其样本点数 ∣ N E p s ( p ) ∣ ≥ M i n P t s \left| {{N}_{Eps}}(p) \right|\ge MinPts ∣NEps(p)∣≥MinPts,则称样本点 p p p为核心点。其余的样本点成为边界点。如下图所示,点 p p p为核心点,点 q q q为边界点。

定义3:(直接密度可达)若样本点 p p p与点 q q q满足如下条件:
- p ∈ N E p s ( q ) p\in {{N}_{Eps}}(q) p∈NEps(q)
- ∣ N E p s ( q ) ∣ ≥ M i n P t s \left| {{N}_{Eps}}(q) \right|\ge MinPts ∣NEps(q)∣≥MinPts(核心点条件)
则称点 p p p可由点 q q q直接密度可达,反之不一定成立。如下图所示,因为点 p p p不是核心点,点 q q q是核心点,而点 p p p又在点 q q q的Eps-邻域 内,因此点 p p p可由点 q q q直接密度可达,点 q q q不能由点 p p p直接密度可达。

定义4:(密度可达)若有一串点 p 1 p_{1} p1、 p 2 p_{2} p2、…、 p N p_{N} pN,其中 p 1 ≡ q p_{1}\equiv q p1≡q, p N ≡ p p_{N}\equiv p pN≡p,而 p i + 1 p_{i+1} pi+1可由 p i p_{i} pi直接密度可达( i = 1 , 2 , . . . , N − 1 i=1,2,...,N-1 i=1,2,...,N−1),则称点 p p p可由点 q q q密度可达。
密度可达性是密度直接可达性的扩展,这是一种传递的关系,但不是对称可逆的,只有核心点对之间的密度可达性是对称的。如下图所示,点 p p p可由点 q q q密度可达,而点 q q q不能由点 p p p密度可达。

定义5(密度相连)若有点 o o o,使得点 p p p和点 q q q都由 o o o密度可达,那么称点 p p p和点 q q q是密度相连的。
密度相连性是一种对称可逆的关系。如下图所示,点 p p p和点 q q q是密度相连的。
定义6:(簇)设样本集为 D D D,那么参数为 E p s Eps Eps和 M i n P t s MinPts MinPts的簇C是 D D D的非空子集,它满足以下条件:
- ∀ p , q \forall p,q ∀p,q,如果 p ∈ C p\in C p∈C,而且点 q q q由点 p p p密度可达,那么点 q q q也属于簇C(极大性);
- ∀ p , q ∈ C \forall p,q\in C ∀p,q∈C: p p p和点 q q q是密度相连的(连接性)。
定义7:(噪声点)设 C 1 , C 2 , . . . , C k {{C}_{1}},{{C}_{2}},...,{{C}_{k}} C1,C2,...,Ck是样本集 D D D的所有的簇,那么噪声点就是数据集 D D D中,不属于以上所有簇的样本点。即
noise = { p ∈ D ∣ ∀ i : p ∉ C i } , i = 1 , 2 , . . . , k \text{noise}=\{p\in D|\forall i:p\notin {{C}_{i}}\},i=1,2,...,k noise={p∈D∣∀i:p∈/Ci},i=1,2,...,k
引理1:设点 p p p是样本集 D D D中的样本点,而且 ∣ N E p s ( p ) ∣ ≥ M i n P t s \left| {{N}_{Eps}}(p) \right|\ge MinPts ∣NEps(p)∣≥MinPts,即点 p p p是核心点,那么集合 O = { o ∣ o ∈ D , 且 o 由 p 密 度 可 达 } O=\{o|o\in D,且o由p密度可达\} O={o∣o∈D,且o由p密度可达}是一个簇。
簇 C C C中的每一个点有 C C C种的任意一个核心点密度可达的,所以簇 C C C刚好包含了所有由它的核心点密度可达的点。
引理2:设 C C C是一个簇, p p p是簇 C C C中的任意一点且 ∣ N E p s ( p ) ∣ ≥ M i n P t s \left| {{N}_{Eps}}(p) \right|\ge MinPts ∣NEps(p)∣≥MinPts,那么 C C C等价于集合 O O O,其中
O = { o ∣ o ∈ D , 且 o 由 p 密 度 可 达 } O=\{o|o\in D,且o由p密度可达\} O={o∣o∈D,且o由p密度可达}
2.2 算法实现步骤
输入:样本集 D = { x 1 , x 2 , . . . , x m } D=\{x_{1},x_{2},...,x_{m}\} D={x1,x2,...,xm},邻域参数( E p s Eps Eps, M i n P t s MinPts MinPts)
输出:簇的划分 C = { C 1 , C 2 , . . . , C k } C=\{C_{1},C_{2},...,C_{k}\} C={C1,C2,...,Ck}
1) 初始化核心点集 Ω = ∅ \Omega =\varnothing Ω=∅ ,初始化聚类簇的序号 k = 0 k=0 k=0 ,初始化未访问的样本点集 Γ = D \Gamma =D Γ=D ,簇的划分 C = ∅ C=\varnothing C=∅
2) 对于 j = 1 , 2 , . . . , m j=1,2,...,m j=1,2,...,m,按照下列步骤找出所有的核心点:
- 通过距离度量的方式,找到样本点 x j x_{j} xj的Eps-邻域 N E p s ( x j ) N_{Eps}(x_{j}) NEps(xj)
- 如果Eps-邻域 的点数 ∣ N E p s ( p ) ∣ ≥ M i n P t s \left| {{N}_{Eps}}(p) \right|\ge MinPts ∣NEps(p)∣≥MinPts,则将 x j x_{j} xj加入到核心点集 Ω \Omega Ω中: Ω = Ω ∪ { x j } \Omega =\Omega \cup \{{{x}_{j}}\} Ω=Ω∪{xj}
3) 如果核心点集 Ω = ∅ \Omega =\varnothing Ω=∅ ,则算法结束,否则转入步骤4)
4)在核心点集 Ω \Omega Ω中,随机选择一个核心点 o o o,初始化当前簇的核心点队列 Ω c u r = o \Omega _{cur}={o} Ωcur=o,更新类别序号 k = k + 1 k=k+1 k=k+1,初始化当前簇样本集合 C k = { o } C_{k}=\{o\} Ck={o},更新未访问样本集合 Γ = Γ − { o } \Gamma = \Gamma - \{o\} Γ=Γ−{o}
5)如果当前簇的核心点队列 Ω c u r = ∅ \Omega _{cur}=\varnothing Ωcur=∅,则当前聚类簇 C k C_{k} Ck生成完毕,更新簇的划分 C = { C 1 , C 2 , . . . , C k } C=\{C_{1},C_{2},...,C_{k}\} C={C1,C2,...,Ck},更新核心点集 Ω = Ω − C k \Omega =\Omega - C_{k} Ω=Ω−Ck,转入步骤3)
6)在当前簇的核心点队列 Ω c u r \Omega _{cur} Ωcur中随机取出一个核心点 o ′ o^{'} o′,通过邻域距离阈值 E p s Eps Eps划出所有Eps-邻域 N E p s ( o ′ ) N_{Eps}(o^{'}) NEps(o′),令 Δ = N E p s ( o ′ ) ∩ Γ \Delta ={{N}_{Eps}}({{o}^{'}})\cap \Gamma Δ=NEps(o′)∩Γ,更新当前簇的样本集合 C k = C k ∪ Δ C_{k}=C_{k}\cup \Delta Ck=Ck∪Δ,更新未访问样本集合 Γ = Γ − Δ \Gamma = \Gamma - \Delta Γ=Γ−Δ,更新核心点队列 Ω c u r = Ω c u r ∪ ( Δ ∩ Ω ) − o ′ \Omega _{cur}=\Omega _{cur}\cup(\Delta\cap\Omega)-o^{'} Ωcur=Ωcur∪(Δ∩Ω)−o′,转入步骤5)
最终程序执行完成后将输出簇的划分结果 C = { C 1 , C 2 , . . . , C k } C=\{C_{1},C_{2},...,C_{k}\} C={C1,C2,...,Ck}。
3 伪代码
根据以上算法,写出如下伪代码的形式:

其中ExpandCluster函数的伪代码形式如下:

4 实验结果
利用 SEQUOIA 2000 的部分测试样本,测试DBSCAN算法以及CLARANS算法的聚类效果,并做对比。
以下是CLARANS算法的聚类结果:

以下是DBSCAN的聚类结果:

由实验结果可以看出,DBSCAN对任意形状的样本集都具有较好的更符合人类直观的聚类效果,并在聚类的同时可以找出噪声点并排除噪声点。
下表展示了DBSCAN算法与CLARANS算法的聚类效率的对比(单位 秒):
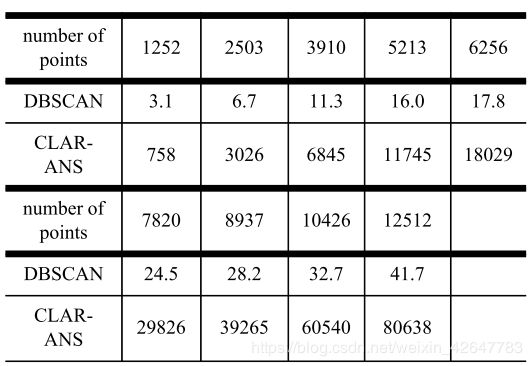
由表可以看出,DBSCAN的聚类效率更高,比CLARANS能快出1到2个数量级。
5 优缺点
DBSCAN具有以下优点:
- 可以对任意形状的稠密数据集进行聚类;
- 可以在聚类的同时发现异常点,对数据集中的异常点不敏感;
- 相对于K-Means等聚类方法,DBSCAN对结果没有偏倚,其初始值的设置几乎不会影响聚类结果
DBSCAN也有它的缺点:
- 如果样本集的密度不均匀、聚类间距差相差很大时,聚类质量较差,这时用DBSCAN聚类一般不适合;
- 如果样本集较大时,聚类收敛时间较长,此时可以对搜索最近邻时建立的KD树或者球树进行规模限制来改进;
- 调参相对于传统的K-Means之类的聚类算法较为复杂,主要需要对距离阈值 E p s Eps Eps和邻域样本数阈值 M i n P t s MinPts MinPts联合调参,不同的参数组合对最后的聚类效果有较大影响。
6 小结
和传统的K-Means算法相比,DBSCAN最大的不同就是不需要输入类别数 k k k,当然它最大的优势是可以发现任意形状的聚类簇,也就是说它可以用于非凸数据集的聚类,而不只是像K-Means等算法仅仅局限于凸样本集的聚类。同时它在聚类的同时还可以找出异常点,这点和BIRCH算法类似。当数据集不是稠密的类型,就不适合采用DBSCAN算法。
7 参考文献
[1] Ester, Martin & Kriegel, Hans-Peter & Sander, Joerg & Xu, Xiaowei. (1996). A Density-Based Algorithm for Discovering Clusters in Large Spatial Databases with Noise. KDD. 96. 226-231.
[2] DBSCAN密度聚类算法
[3] 聚类分析常用算法原理:KMeans,DBSCAN, 层次聚类
原创性声明:本文属于作者原创性文章,小弟码字辛苦,转载还请注明出处。谢谢~
如果有哪些地方表述的不够得体和清晰,有存在的任何问题,欢迎评论和指正,谢谢各路大佬。
有需要相关技术支持的可咨询QQ:297461921