An Anchor-Free Region Proposal Network for Faster R-CNN based Text Detection 论文翻译解读
基于Faster R-CNN的文本检测方法的无锚区域候选网络
摘要
由于IoU和真实文本框之间的匹配标准,基于Faster R-CNN和SSD的锚机制被认为在场景文本检测中不够有效。为了更好地覆盖各种情形的场景文本实例,需要手动设计各种比例尺,纵横比和定向的锚,这使得基于锚的方法复杂且效率低下。在本文中,我们提出了一种新的无锚区域候选网络(Anchor-Free Region Proposal Network,AF-RPN)。该网络通过以Faster R-CNN为基础的RPN(Region Proposal Network, RPN)解决上述问题。 AF-RPN与原始RPN和FPN-RPN (Feature Pyramid Networks -Region Proposal Network)相比,可以摆脱复杂的锚设计,在大规模COCO-Text数据集上实现更高的召回率。由于提供了高质量的候选文本,我们采用基于Faster R-CNN的两阶段文本检测方法实现了ICDAR-2017 MLT,ICDAR-2015和ICDAR-2013文本检测基准测试的(只进行规模和单模(ResNet50)测试)最好结果。
1 引言
最近,由于对许多基于内容的视觉智能应用的需求不断增长,如图像和视频检索、场景理解和目标定位,场景文本检测在计算机视觉和文档分析领域引起了广泛关注[Shahab et al., 2011; Karatzas et al., 2013; Karatzas et al., 2015] 。 然而,由于颜色、字体、方位、语言和比例等文本变化的多样性,极其复杂和类似于文本的背景以及由诸如非均匀照明,低对比度,低分辨率和遮挡的图像捕获引起的一些失真和伪像 ,自然场景图像中的文本检测仍然是一个未解决的问题。
目前,随着深度学习的快速发展,基于最新卷积神经网络(CNN)的目标检测框架如Faster R-CNN [Ren et al., 2015]和SSD [Liu et al., 2016] 已被广泛用于解决文本检测问题。与传统的MSER [Matas et al., 2002] 或SWT [Epshtein et al., 2010] 等基于自底向上的文本检测方法相比,它表现更好。然而,Faster R-CNN和SSD由于其锚(在SSD中被称为默认框)机制被证实对于文本检测不够灵活[He et al., 2017]。 在Faster R-CNN和SSD中锚被用作参考框来预测相应的候选区域或目标,并且每个锚点的标签由它的与真实文本框交叉相交(IoU)重叠来确定[Ren et al., 2015]。如果我们想要检测一个目标,至少应该有一个锚点与这个目标有足够高的IoU重叠。 因此,为了实现高召回率,应该设计具有不同尺度和形状的锚,以覆盖图像中物体尺度和形状的变化。由于场景文本实例在尺度,纵横比,特别是方向上的变化比一般物体的变化更大,所以它需要更复杂的锚设计,即更多的尺度,纵横比和方向[Zhong et al., 2017; Liao et al., 2016; Ma et al., 2017; Liu and Jin, 2017],这使得基于锚的方法变得复杂和低效。 最近,在一些文本检测方法[He et al., 2017; Zhou et al., 2017] 中借用了DenseBox [Huang et al., 2015]的想法来克服这个问题。它使用全卷积神经网络(FCN)[Long et al., 2015] ,通过图片的位置和尺度,直接输出所有相关文本实例的像素级的文本分数和边框。这些方法虽然更灵活一些,但功能受到影响。 例如,他们无法稳健地检测长文本或大文本实例,这在“多语言场景文本检测”场景中经常出现[Nayef et al., 2017],因为检测器可以处理的文本实例的最大的尺度是有限的由所使用的卷积特征映射的接受域(RF)大小决定。
为了克服上述问题,我们建议将DenseBox的智能“无锚”思想融入到Faster R-CNN 中。 具体而言,我们提出了一种新的无锚区域候选网络(AF-RPN)来替代原有的基于锚点的RPN,以便我们的文本检测器可以同时具有高度的灵活性和高性能。如图1所示,特定卷积特征图中的每个像素可被映射到原始图像中的点(以下称为滑动点)。 对于位于文本核心区域中的每个滑动点(图1(b)中的红色点),AF-RPN直接预测从它到相关文本实例的边框顶点的偏移量(图1(c))。这样,AF-RPN可以直接以无锚方式直接生成高质量的候选,从而摆脱复杂的手工锚设计。 此外,AF-RPN中滑动点的标签定义比原始RPN中基于IoU的锚定标签定义容易得多,我们只需要确定滑动点是否在任何真实文本框的核心区域内。与基于DenseBox的文本检测器相比,基于Faster R-CNN的文本检测器可以更有效地处理长文本或大文本实例。这是因为第二阶段Faster R-CNN中的ROI池化算法可以显着扩大每个提议的池化特征的大小,这不仅可以提高长文本实例的边框回归精度,还可以提高文本/非文本分类的准确率。 此外,与DenseBox不同,我们让AF-RPN以缩放友好的方式从特征金字塔网络(FPN)的多尺度特征地图中提取文本提案[Lin等,2017],以便AF-RPN在文字尺度上更加稳健 。 由于这一点,我们的文本检测器可以实现卓越的文本检测性能,而只需进行单一测。
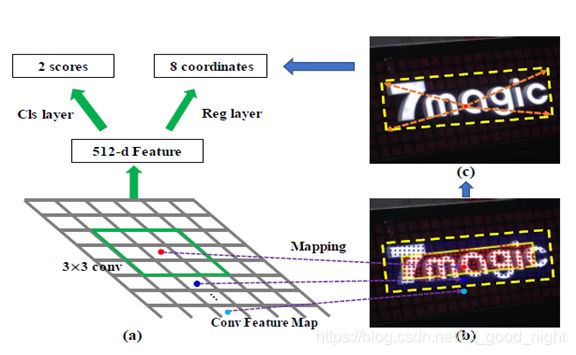
图1
大量的实验表明,作为一种新的区域候选生成方法,AF-RPN可以比原始RPN [Ren et al., 2015]和FPNRPN[Lin et al., 2017]在大型COCO文本[Veit et al., 2016] 数据集上取得更高的召回率。 由于高质量的文本候选,我们基于R-CNN的两阶段快速文本检测方法即AF-RPN + Fast R-CNN在ICDAR-2017 MLT [Nayef et al., 2017], ICDAR-2015[Karatzas et al., 2015] , ICDAR-2013 [Karatzas et al.,2013],上取得了最好的结果。
2 相关工作
现有的文本检测方法大致可以分为两类:自下而上[Neumann and Matas, 2010; Epshtein et al., 2010; Yao et al., 2012; Yin et al., 2014; Yin et al., 2015; Sun et al., 2015]和自上而下的方法[Jaderberg et al., 2014; Zhang et al., 2016; Yao et al., 2016; Jaderberg et al., 2016; Gupta et al., 2016; Ma et al., 2017; Liu and Jin, 2017; Zhou et al., 2017; He et al., 2016]。自下而上的方法通常由三个主要步骤组成,即候选文本连接组件(CC)提取(例如基于MSER [Matas et al., 2002]或SWT [Epshtein et al., 2010] ),文本/ 非文本分类和文本行分组。 这些方法,特别是基于MSER的方法,曾经是深度学习时代之前的主流方法。 然而,最近这些方法在精度和适应性方面落后于基于CNN的自上而下方法,特别是在处理更具挑战性的“附带场景文本”[Karatzas et al., 2015]和“多语言场景文本检测”时[Nayef et al., 2017]的情景。
因此,基于CNN的自上而下方法最近已成为主流。 一些文献[Zhang et al., 2016; Yao et al., 2016]]借用语义分割的思想,并采用FCN [Long et al., 2015]解决文本检测问题。 FCN预测的文本图提取粗糙的文本块,所以需要后处理步骤来提取精确的文本行边框。 有些文献不止使用了FCN预测文本显着性图[Zhou et al., 2017; He et al., 2017],还借用了DenseBox [Huang et al., 2015]的想法,使用一阶段FCN来输出像素方面的文本分数以及通过图像的所有位置和尺度的四边形边界框。虽然这些方法更加灵活,但它们无法有效且高效地处理长或大的文本实例。 目标检测框架也被广泛用于解决文本检测问题。[Jaderberg et al., 2016]把R-CNN [Girshick et al.,2014]用于文本检测。 这种方法的表现受传统区域候选生成方法的限制。 [Gupta et al., 2016]类似于YOLO框架[Redmon, 2016],采用全卷积回归网络进行文本检测。[Zhong et al., 2017] 和 [Liao et al., 2016]采用基于锚的Faster CNN [Ren et al., 2015]和SSD [Liu et al., 2016]框架来解决横向文本检测问题。 为了将更快的R-CNN和SSD扩展到多向文本检测,[Ma et al., 2017; Liu and Jin, 2017] 提出了四边形锚寻找倾斜的文本提案,它可以更好地适应多方面的文本实例。 但是,如上所述,这些基于主页方法对于文本检测不够有效和灵活,导致性能较差。 在本文中,我们提出了一种新型的AF-RPN,以提高R-CNN的灵活性和能力,这使得我们的方法在各种文本检测基准上实现了卓越的性能。
3 无锚区域候选网络
我们提出的AF-RPN网络,它由一个主干网络和三个特定尺度的检测模块组成。 主干网络负责在整个输入图像上计算多尺度卷积特征金字塔。 三个检测模块连接在不同的金字塔等级上分别用于检测小型,中型和大型文本实例。 每个检测模块包含一个具有两个同级输出的小型网络,分别用于文本/非文本分类和四边形边框回归。图2中展示了AF-RPN模型。
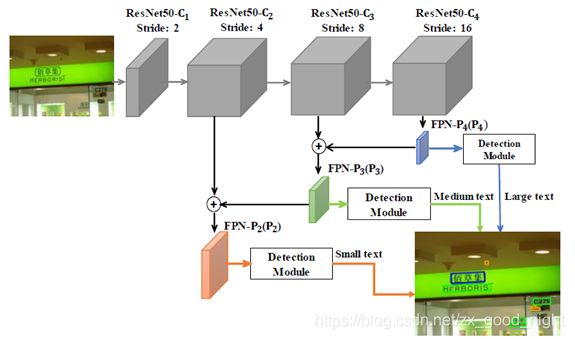
图2
3.1 AF-RPN 网络框架
我们采用FPN [Lin et al., 2017]作为AF-RPN的主干网络。 FPN通过自上而下的路径和横向连接强化了标准卷积网络,从单个分辨率输入图像构建多尺度的特征金字塔。金字塔的每个级别都可以有效地用于检测特定比例尺范围内的目标。基于[Lin et al., 2017],我们在ResNet50 [He et al., 2016]上建立了FPN,并构建了一个三级特征金字塔。它们的滑动步长为4, 8,16。FPN的实施一般遵循[Lin et al., 2017],我们的网络只和其有两个微小的差异。首先,我们不包括金字塔等级,因为它的分辨率不能满足文本检测任务。其次,所有特征金字塔等级都是个通道。
分别连接了三个特定尺度的检测模块。与RPN类似[Ren et al., 2015],每个检测模块可以被认为是一个滑动窗口检测器,它使用一个小型网络在单级金字塔等级的每个滑动窗口上执行文本和非文本分类和边框回归(图1(a))。小网络实现为卷积层,然后是两个卷积层接口,用于预测文本分数和边框坐标。我们提出了一个缩放友好的学习方法来学习三个检测模块,这些模块分别用于检测小型,中型和大型文本实例。这样可以有效缓解每个检测模块的文本及非文本分类和边框回归的学习困难,从而使AF-RPN能够更加鲁棒地处理大文本方差。第3.2节描述了尺度划分的细节,第3.3节详细阐述了AF-RPN的基本定义。

图3
3.2 缩放友好型学习
在训练阶段,我们根据相应金字塔等级上特征空间的大小为三个检测模块分配文本实例。当一个金字塔等级的文本实例的特征短边小于3像素(px)时,相应检测模块的性能显着降低。(如图3中所示)原始图像中由黄色边框所围的文本实例G的高度(短边)为16px。当原始图像以0.75,0.50和0.25的比例下采样时,G的高度减小到12,8,4 px(图3(a)),并且上G特征的高度减少到3,2,1px(图3(b))。然后,我们使用附加在上的AF-RPN检测模块来检测[4px,24px]范围内的缩放(短边)文本实例,以检测这4个图像上的文本实例。从图3(c)中,我们发现,即使我们的训练集包含大量这些小文本实例,当输入图像中的高度小于12px时,也无法有效的检测。这是由G的短边少于3像素的不足特征引起。基于这种观察,在将文本实例分配给金字塔等级时,我们确保其金字塔等级上的特征的短边不小于3像素。由于的步幅为4,8,16 px,分配给它们的文本实例的短边分别应该不小于12,24,48px。 因此,我们根据短边长度,即小文本(4px-24px),中等文本(24px-48px)和大文本(> 48px),将文本实例分类为三组。
3.3 标签生成
文本检测任务中的文本实例通常使用四边形或轴对称边框在单词级别进行标记。 为了更好的实现,对于四边形边框,我们使用它们的最小封闭框(定向矩形)作为新的真实文本框(图1(b)中的黄色虚线)。 当真实文本框不够紧致时,文本框会包含一些背景信息。为了减少背景噪声对文本/非文本分类的影响,根据[Zhou et al., 2017; He et al., 2017],我们分别通过缩放因子0.5和0.8缩小每个真实矩形文本框的短边和长边,以创建相应的核心文本区域(图1(b)中的黄色实线),只有核心区域内的滑点被视为正面的。滑动点位于核心区域的外侧,但在真实矩形内部被标记为“不关注”标签,并且在训练期间被忽略(图1(b))。 所有真实文本直线外的滑动点被视为负面的。对于每个正滑动点,我们直接预测其边框的坐标。令表示一个正滑动点,它位于一个真实文本矩形G中。表示G的顶点。从到G顶点的坐标偏移可以表示为。其中,(图1(c))。的取值范围非常大,需要对其归一化:,。如果在中,norm被设置为相应比例范围的上限。如果在中,norm被设置的比例。
4 带有AF-RPN的Faster R-CNN
在候选区域生成后,分别选择AF-RPN中各个检测模块的Top-得分检测结果构建候选集。然后,我们使用标准NMS算法(IoU = 0.7)删除中的冗余候选,并为Fast R-CNN选择Top-得分提案。在训练和测试阶段,,分别设置为2000和300。接下来,我们采用第3.2节中的相同尺度划分标准将文本候选分类为分别分配给金字塔等级的小,中和大文本候选组。与AF-RPN类似,三个不共享参数的Fast R-CNN检测器分别分配给金字塔等级。每个Fast R-CNN探测器设计遵循Light Head R-CNN的想法[Li et al., 2017]。具体来说,我们在特定的金字塔等级上应用了两个可分离的控制层(即和卷积)来创建大尺寸的(490个通道)特征图,我们从中采用PS ROI池化[Dai et al., 2015]为每个候选提取个特征,然后在最终的文本/非文本分类和边框回归图层之前将合并的特征提供到一个具有2048个单位的完全连接图层。
5 训练
5.1 损失函数
基于AF-RPN的多任务损失函数
每个比例特定的检测模块有两个同级输出层,即文本/非文本分类层和四边形边框反演层。每个检测模块的多任务损失函数表示如下:
(1)
其中其中是分别针对每个滑动点的预测和真实标签。是用于分类的Softmax损失函数。表示从到G的预测和真实8维归一化坐标偏移,是用于回归的smooth损失函数。两个损失平衡参数,并设置。
基于Fast R-CNN的多任务损失函数
Fast R-CNN的损失函数与式(1)相同,只有两个参数取值不同。这里我们设置。与AF-RPN相比,回归任务的坐标偏移归一化存在一些差异。设为候选输入,分别为其轴对齐边框的中心坐标,高度和宽度。用正则化从到G的顶点的坐标偏移:,。其中。Fast R-CNN的损失函数是三个独立Fast R-CNN检测器的损失之和。
5.2 训练详情
在AF-RPN的每次训练迭代中,我们为每个检测模块采样mini-batch128个正向和128个负向滑动点。同样,对于Fast R-CNN,我们针对每个Fast R-CNN检测器对64个正片和64个负片文本提案进行mini-batch采样。如果候选文本框与任何真实文本框的IoU重叠高于0.5,则它是正面标签,并且如果其所有地面真实边界框的IoU重叠小于0.3,则为负面标签。为了提高效率,IoU在候选和真实文本框之间重叠,使用它们的轴对齐的矩形边框来计算。每个地面真值边框仅分配给AF-RPN的一个检测模块或一个Fast R-CNN检测器,并被其他两个检测模块忽略。此外,我们将采用OHEM作为[Dai et al., 2015]在Fast R-CNN训练阶段有效抑制hard文本背景示例。
6 实验
- 数据集和实施详情
我们评估了几种标准基准测试任务的方法,包括ICDAR-2017 MLT [Nayef et al., 2017],ICDAR-2015 [Karatzas et al., 2015]用于多向文本检测;ICDAR-2013 [Karatzas et al., 2013] 用于横向文本检测,以及COCO-Text [Veit et al., 2016] 候选质量评估。
为了与其他方法相比较,我们使用在线官方评估工具评估我们在ICDAR-2017 MLT,ICDAR-2015和ICDAR-2013测试集中的性能,其中分别包含9500,500和233幅图像。我们使用召回率作为评估指标来比较不同区域候选方法在COCO-Text验证集(10000张图像)上的表现。
FPN主干网中Resnet50相关层的权重通过使用预先训练好的用于ImageNet分类的Resnet50模型来初始化[[He et al., 2016]。 FPN,AF-RPN和Fast R-CNN的其他新层的权重通过使用具有0均值和0.01标准差的高斯分布的随机权重来初始化。在训练阶段,我们训练AF-RPN模型直到第一次收敛。然后,我们使用这个训练好的AF-RPN模型来初始化Faster R-CNN模型,然后使用近似的end-to-end训练算法对其进行微调。所有模型均采用标准SGD算法进行优化,动量为0.9,重量衰减为0.0005。训练迭代的次数和学习速率的调整策略取决于不同数据集的大小。具体而言,对于ICDAR-2017 MLT,我们使用培训和验证数据,即总共9,000幅图像进行培训。 AF-RPN和更快的R-CNN模型都经过200K次迭代的训练,初始学习率为0.001,然后在90K和180K迭代时除以10。由于ICDAR-2015和ICDAR-2013的训练集太小,我们直接使用经过ICDAR-2017 MLT训练的模型作为预训练模型,然后在ICDAR-2015和ICDAR-2013训练集上进行微调, 2013年。这两个数据集的所有模型都经过40K次迭代的训练,初始学习率为0.0005,在20K迭代时除以5。对于COCO文本,我们在其训练集上训练模型并在验证集上报告实验结果。所有模型都经过250K迭代训练,初始学习率为0.001,然后在100K和200K迭代时除以10。我们的实验是在Caffe框架上进行的[Jia et al., 2014]。
- 候选质量评估
在COCO-Text 上比较了AF-RPN 、RPN 、FPN-RPN 三种网络在区域候选生成任务上面的性能。
实验分别在0.5和0.75的单个IoU阈值下计算召回率和,同时还计算了多个IoU阈值在0.50和0.95之间的平均召回率,间隔为0.05,使用给定的固定数量(#)文本候选。 实验报告每个图像50,100和300个候选的结果(300个提案用于测试阶段的Fast R-CNN)。实验结果如表1所示。
AF-RPN在所有评估指标中(召回率)都优于RPN和FPN-RPN。当评估的提案数量从300个减少到50个时,改进更加显着,这证明了AF-RPN的有效性。
此外,AF-RPN可以直接输出倾向于文本实例的文本候选。对于四边形提案质量评估,AF-RPN分别在ICDAR-2015的、、中分别达到88.9%,92.2%和95.4%。
表1

3.文本检测性能评估
ICDAR-2017 MLT
表2

AF-RPN通过将F-measure从0.65提高到0.70显着地超过top-1的比赛结果。考虑到ICDAR-2017 MLT是一个非常具有挑战性的并且是第一个大规模多语言文本检测数据集,AF-RPN所取得的卓越性能可以明显证明其优势。
ICDAR-2015
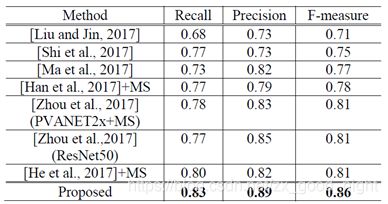
对于具有挑战性的ICDAR-2015任务,AF-RPN分别在召回率,精度和F-measure方面分别达到0.83,0.89和0.86的最佳结果,优于其他最近公布的基于CNN的方法。
表3
ICDAR-2013
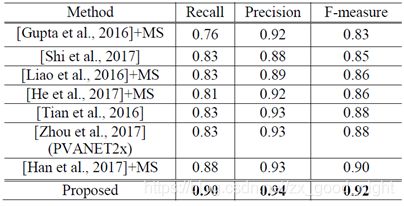
AF-RPN达到0.92 F-measure的最佳结果。 就运行时间而言,当使用单个M40 GPU时,该方法对于每个512×1024图像平均需要大约0.50秒的时间。
表4
定性结果
上述三个数据集所取得的卓越性能表明了AF-RPN方法的有效性和稳健性。 该方法的文本检测器可以在各种具有挑战性的情况下检测场景文本区域,例如低分辨率,不均匀照明,大纵横比以及不同方向。 但是,AF-RPN仍然有一些限制。 首先,AF-RPN不能处理曲线文本实例。 其次,AF-RPN仍然无法处理极小的文本实例,这些实例在调整大小的图像中短边小于8像素。
与现有方法相比
在[Liu and Jin,2017]和[Ma et al., 2017]的工作中,介绍了一阶段SSD和两阶段快速R-CNN框架的定向锚策略。 这些基于锚的方法的性能明显低于我们的无锚方法,即在ICDAR-2015的F-measure中0.71和0.78对0.86。 另外,虽然基于DenseBox的文本检测方法[Zhou et al., 2017; He et al., 2017] 也使用了“无锚”概念,它们的能力仅限于大或长文本。我们基于Faster R-CNN的两阶段方法, 即AF-RPN + Fast R-CNN,可以有效地克服这个限制,从而将ICDAR-2015中的F-measure从0.81提高到0.86。
7 结论和讨论
在本文中,我们提出AF-RPN作为Faster R-CNN框架的无锚和缩放友好区域候选网络。 在大型COCO-Text数据集上的与RPN,FPNRPN相比,证明了AF-RPN的优越性能。 由于高质量的文本提案,我们基于Faster R-CNN的文本检测器在AF-RPN + Fast R-CNN在ICDAR-2017 MLT,ICDAR-2015和ICDAR-2013上基于单一和单一模式测试实现了最新的结果。未来的方向是探索AF-RPN在其他检测任务中的有效性,如通用物体检测,人脸识别和行人检测等。