编译原理学习笔记-2:文法和语言
在 上一篇笔记中,我们谈到了为什么需要编译以及编译的大致流程。在继续细讲每一个流程之前,我们先通过本篇笔记对一些概念和术语加以了解。
1. 前置知识:字母表和符号串
1.1 字母表
字母表也即符号集,用 ∑表示,它是一个包含各种符号的有穷非空集合。以汉语为例,汉语字母表就是各种汉字、数字、标点符号的集合;以英语为例,英语字母表就是各种字母、数字、标点符号的集合…那么到了编程,字母表就可能是字母、数字、各种专用符号和保留字了。
1.2 符号串
相关定义:
符号串是对于字母表来说的一个概念,字母表的符号串指的就是由字母表中各个字符组成的一个有穷序列。
注意这里的“有穷”,指的是符号串本身是由有穷个符号组成,但是符号串的个数是无穷多的(组合方式不同)。以字母表 ∑={0,1} 为例,它的符号串就有:0,1,00,01,10,11,000 等等。
符号串的长度指的是符号串符号的个数,以 m = 000 为例,|m|= 3。
空符号串 ε 长度为 0,表示不包含任何符号,类似于编程中的空字符串 ""。所以有 εm = mε= m。
以 m = abc 为例,它的头是 ε,a,ab,abc;它的尾是 ε,c,bc,abc。而它的固有头不考虑末尾符号 c,固有尾不考虑首部符号 a。
连接、方幂
- 符号串的连接:连接就是两个字符串顺序拼接,比如
x = abc,y = def,那么xy = abcdef。 - 符号串的方幂:如果一个符号串由多个重复符号构成,如何方便地表示它呢?比如
y = xxxx...xxxx(n 个 x),那么就可以写成y = x^n,此时 y 就是 x 的方幂。这点和数学是一样的。不过要注意,x^0 ≠ 1 = ε。
1.3 闭包
以字母表 ∑ = {a,b} 为例,任何由它的符号串作为构成元素的集合,都可以称作字母表的符号串集合。比如说 {ab},{abab,ababab} 等。
两个符号串集合的乘积定义为 AB = {xy| x∈A且y∈b},其实就是笛卡尔积。
一般的字符串集合可能并不能囊括一个字母表的所有符号串,但是有一种集合却能包含所有的符号串,这种特殊的集合称为闭包,记作 ∑*。* 其实就是全选的意思(联想 CSS 中的通配选择符就好理解了)。
∑* = {ε,a,b,ab,ab,ba,aba,aab......} = ∑^0 ∪ ∑^1 ∪ ∑^2 ∪......∪ ∑^n
要注意的是,闭包也包含了空符号串。
将闭包中的空符号串去掉,就成为了正闭包,也即 ∑+。显然:∑*= ∑^0 ∪ ∑+,∑+ = ∑∑* = ∑*∑。
2. 文法
2.1 文法在语言体系中的位置
语言包括语法和语义两个方面,但是语法和语义都是比较抽象的东西,所以我们需要借助一些工具来阐述它们。以语法来说,文法就是阐述它的一个工具。
2.2 文法的形式定义
文法是描述语言语法结构的形式规则。它的形式化定义是一个四元组,即 G = { VN , VT , P , S }。下面我们先给出一个自然语言的例子,然后借此来解释四元组的各个成分都是什么。
<句子> → <主语> <谓语>
<主语> → <代词> | <名词>
<谓语> → <动词>
<代词> → 你 | 我 | 他
<名词> → 张三 | 教师 | 大学生
<动词> → 教书 | 学习
(1)VT:
VT 指的是终结符集合。终结符即 terminal symbol,它是文法所定义的语言的最基本符号,这意味着一个终结符不可再细分(注意“终结”这个词)。以上面为例,VT ={ 你,我,他,张三,教师,大学生,教书,学习 }。在编程语言中,终结符其实就是之前提到的 token,比如保留字、运算符、界符等这些最最基本的符号。
终结符一般用小写字母表示。
(2)VN:
VN 指的是非终结符集合。非终结符即 nonterminal symbol,它是用来表示语法成分的符号,有时候也称为“语法变量”。以上面为例,VN ={ <句子>,<主语>,<谓语>,<代词>,<名词>,<动词> }。在编程语言中,我们可以说表达式或者赋值语句就是一个非终结符,因为它可以继续细分为多个 token。
非终结符的“非终结”,就是说“还没有到尽头”,还可以继续拆分,一般用 <> 括起来。
非终结符一般用大写字母表示。
**PS:**终结符和非终结符统称为文法符号。
(3)P:
P 即 production,指的是产生式集合。终结符和非终结符的转换依靠的就是产生式(或者说生成式,推导规则)。产生式形如 a → β (或者 a : : = β ,这种表示方法即巴科斯范式 ),意思是将 a 定义为 β。a 称为产生式左部,它是终结符集合的一个元素;而 β 称为产生式右部,它是终结符和非终结符并集的一个元素。根据前面的定义,很容易就能知道产生式的左部不能是终结符,因为左部都是可以继续细分的,但是终结符不能再细分了,而右部在一开始可能是非终结符(还没拆完),但在最后一定会变成终结符(拆完了,不能再拆了)。
以上面为例,P = { <句子> → <主语> <谓语>,<主语> → <代词> | <名词>,<谓语> → <动词> }
(4)S:
S 即 start symbol,指的是开始符号(识别符号)。它是最开始的那条产生式的左部,一切的推导都是从它这里开始进行的,可以认为它就是最大的那个成分。所以也注定了 S 必须在 P 中至少作为某一条产生式的左部(不然无从推导)。
以上面为例,S = <句子>。
2.3 更简洁的形式化定义
假如现在有文法 G =({S,A,B},{0,1},P,S),
其中,P = { S → 0A,S → 1B,A → 1B,B → 1 }。
是否有更简便的方法来表示它呢?事实上,这里仅从产生式集合 P 来看,完全可以在不引起歧义的情况下推断出终结符号集,非终结符号集以及开始符号。这意味着我们可以将这三者省略,仅用产生式集合表达文法本身,也即:
G:
S → 0A
S → 1B
A → 1B
B → 1
B → 0
更进一步地,我们发现部分产生式的左部都是一样的,所以可以继续简写为:
G:
S → 0A | 1B
A → 1B
B → 1 | 0
此时,0A 或者 1B 称为 S 的候选式(candidate),1 或者 0 称为 B 的候选式。
2.4 推导
(1)直接推导:
假如文法 G = { VN , VT , P , S } 有一条产生式为 a → β ,γ 和 δ 是 V*= VN ∪ VT 中的任意符号(即是文法中的任意终结符或者非终结符),若有符号串满足:
V = γ a δ ,W = γ β δ
那么就说 V 可以直接推导得到 W,或者说 W 是 V 的直接推导,W 直接规约到 V —— 记作 V ⇒ W。我们看一个例子:
假如现在有文法 G =({S,A,B},{0,1},P,S),其中,P = { S → 0A,S → 1B,A → 1B,B → 1 }。
那么以产生式 S → 0A 为例,我们是可以说 S ⇒ 0A 的,因为 S = εSε,0A = ε0Aε(别忘了,空符号串也是属于 V* 的),以此类推,所有的产生式实际上都是一个直接推导。
(2)推导:
推导指的是从文法的开始符号出发,反复连续地使用产生式,对非终结符施行替换和展开,最终得到一个仅由终结符构成的符号串,推导过程的每一步都是一个直接推导。
还是以上面的文法为例,那么就有 S ⇒ 0A ⇒ 01B ⇒ 011,这个序列就是从 S 到 011 的一个推导,或者说 S 可以推导出 011。
序列可以简写为 S +⇒ 011,表示经过一步或者多步推导,而 S *⇒ 011 表示经过 0 步或者多步推导。所以,S *⇒ 011 要么是 S = 011,要么是 S +⇒ 011。
(3)最左/最右推导:
推导的过程并不是唯一的。对于任何一步 α ⇒ β,如果都是对 α 中的最左非终结符进行替换,那么就说最左推导,反之就是最右推导。
假如给定文法G:E → E + E | E * E | (E) | i,由该文法最终可以推导得到句子 (i * i + i)。如果采用最右推导,那么过程就是:
E ⇒ (E) ⇒ (E + E) ⇒ (E + i) ⇒ (E * E + i) ⇒ (E * i + i) ⇒ (i * i + i)。
在每一步中,我们都尽可能地替换 α 中的最左非终结符。
2.5 句型、句子、语言
- 句型:如果 S *⇒ a,开始符号 S 可以推导得到某个符号串,那么这个符号串 a 就称为句型。以上面文法为例,0A ,01B,011 … 都是句型。
- 句子:在推导之初,句型可能既包含终结符也包含非终结符,但最终肯定只剩下终结符构成的符号串,此时这个符号串就称为句子。以上面文法为例,011 就是句子。
- 语言:文法产生的句子的全体就构成了语言,记作 L(G)。以上面文法为例,L(G) = { 011,11 }。
3. 语法分析树与文法的二义性
我们可以借助语法分析树(这里的语法分析树是具体语法树,即 parse tree,不是抽象语法树)这个结构来描述句型的推导。比如给定文法 G:
G = ( {S,A},{a,b},P,S ),其中 P ={ S → aAS,A → SbA,A → SS,S → a,A → ba }
可以这样推导出句子 aabbaa:S ⇒ aAS ⇒ aSbAS ⇒ aabAS ⇒ aabbaS ⇒ aabbaa
那么如何用分析树表达这个句子呢?如图所示:
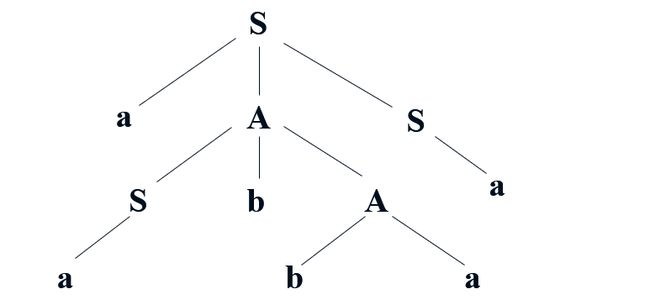
用根节点代表开始符号,随着推导的进行,当某个非终结符被它的候选式所替换时,这个非终结符的相应结点就会产生下一代子结点,以此类推。
有时候,对于某个句子,由于它的推导过程不唯一,所以会导致它的分析树也不唯一。之前的例子中,我们给定了文法 G:E → E + E | E * E | (E) | i,由这个文法推导出句子 (i * i + i),实际上有两种方式:
- E ⇒ (E) ⇒ ( E + E ) ⇒ ( E + i ) ⇒ ( E * E + i ) ⇒ ( E * i + i ) ⇒ ( i * i + i )
- E ⇒ (E) ⇒ (E * E ) ⇒ ( i * E ) ⇒ ( i * E + E) ⇒ ( i * i + E) ⇒ ( i * i + i )
对应地有两种分析树:
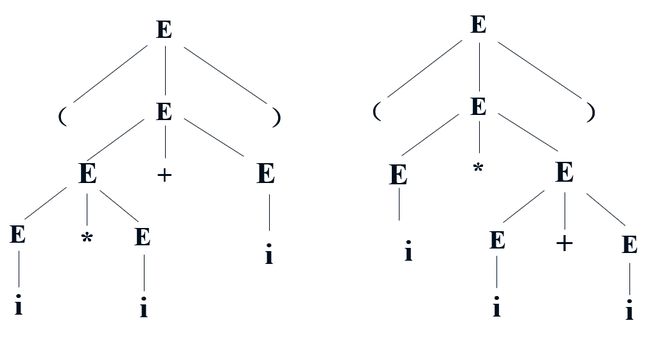
由于这个文法存在着某个句子对应着两棵不同的分析树,所以这个文法是**二义(歧义)**的。
显然,程序语言不能出现歧义。消除歧义的方法之一是改写语法,但这种改写非常困难;另一种方法就是引入 优先级 ,利用符号的优先级来选择需要的推导方式。
作为描述程序语言的上下文无关文法,我们对它还有一些限制:
- 文法中不包含形如 P → P 的产生式
- 每个非终结符一定可以被用到,或者本身被 S 推导得到,或者本身推导得到其它终结符串。
4. 文法类型
乔姆斯基把文法划分为四种类型(从 0 型到 1型),这四种类型层层增强,越到后面限制越大。
(1) 0 型文法
0 型文法也叫短语文法。设 G = { VN , VT , P , S },如果它的每个产生式 α→β 都满足:
α∈(VN∪VT)* 且至少含有一个非终结符,而 β∈(VN∪VT)*
那么这种文法就称为 0 型文法。其中,VN∪VT 代表的是终结符合集和非终结符号集的并集,注意这同样是一个字母集,所以外面加上星号,就成为我们开篇所说的字母集的闭包。也就是说,产生式的左部或者右部,必须是由终结符和非终结符构成的符号串。
(2) 1 型文法
在 0 型文法的基础上加以限制,规定对于每一个 α→β,都必须满足 |α| <= |β|。也就是说,产生式左部符号串长度必须小于等于右部符号串长度。这里要注意一个特例就是:
α → ε,虽然左部长度一定大于右部长度,但它仍然符合 1 型文法。
1 型文法也叫上下文有关文法。
(3) 2 型文法
在 1 型文法的基础上加以限制,规定对于每一个 α→β,都必须满足 α 是一个非终结符。也就是说,产生式左部必须得是一个非终结符。
2 型文法也叫上下文无关文法。
(4) 3 型文法
在 3 型文法的基础上加以限制,规定对于每一个 α→β,要么必须满足 A→ α | αB(右线性),要么必须满足 A→ α | Bα(左线性)。这里的 AB 代表非终极符号。
3 型文法也叫正规文法。
5. 文法和上下文
上下文实际上是在替换非终结符的时候给予的一个限制条件。也就是说,如果文法是上下文有关的,那么进行替换的时候需要考虑上下文,反之则不必。比方说,γ a δ → γ β δ 是 1 型文法的一个产生式,γ 和 δ 都不为空,则非终结符 a 只有在 γ 和 δ 这样的一个上下文环境里才能被替换成 β。
下面我们用更加通俗的例子来解释这两种文法:
定义上下文无关文法 G :
Grammar → X Y Z
X → 我 | 学校
Y → 去 | 没有
Z → 公园 | 人
那么以 Grammar 作为开始符号,就会产生各种句子,其中既有像“我去公园”,“学校没有人”这种句意通顺的,也不乏“我没有人”,“学校去公园”这种狗屁不通的。为什么会产生不符合语义的句子?这是因为我们没有给定上下文的约束,也就是说,因为有了 Y → 去 | 没有 这条产生式,所以只要遇到 Y,推导出“去”或者“没有”就都是合理的,而全然不需要关注“去“的上文是什么,”去“的下文是什么。
但是如果定义上下文有关文法 G‘:
Grammar → X Y Z
X → 我 | 学校
我 Y → 我去
学校 Y → 学校没有
去 C → 去公园
没有 C → 没有人
那么就完全不一样了。这时候非终结符的替换是受到上下文限制的 ——
Y 只有在上文是”我“ 的时候才能被替换成”去“,只有在上文是”学校“ 的时候才能被替换成”没有“,因此不会产生诸如”学校去“或者”我没有“这样的句子;同理,C 只有在上文是”去“ 的时候才能被替换成”公园“,只有在上文是”没有“ 的时候才能被替换成”人“,因此不会产生诸如”没有公园“或者”去人“这样的句子。这样就保证了产生的句子是符合语义的。
最后我们再来总结本篇笔记所讲的内容。在文章开始,我们先给出了一些相关术语的概念和形式,这是为了更好地在后面形式化地表示文法;接着,我们引入了文法的概念,包括它的形式化定义,它的推导;然后,我们引入了语法树的概念,用以描述推导的过程;最后,我们解释了文法的几种类型(0 ~ 3),并通过例子补充了文法在有/无上下文约束的情况下分别会推导出什么句型。
候才能被替换成”公园“,只有在上文是”没有“ 的时候才能被替换成”人“,因此不会产生诸如”没有公园“或者”去人“这样的句子。这样就保证了产生的句子是符合语义的。
最后我们再来总结本篇笔记所讲的内容。在文章开始,我们先给出了一些相关术语的概念和形式,这是为了更好地在后面形式化地表示文法;接着,我们引入了文法的概念,包括它的形式化定义,它的推导;然后,我们引入了语法树的概念,用以描述推导的过程;最后,我们解释了文法的几种类型(0 ~ 3),并通过例子补充了文法在有/无上下文约束的情况下分别会推导出什么句型。