实例讲解进驻Google两位大神主推的异构计算与RISC-V
先转过来,后面慢慢研究
转自:《实例讲解进驻Google两位大神主推的异构计算与RISC-V》
摘要:John Hennessy和David Patterson两位计算机体系结构方面的泰山北斗双双进驻Google引起了业界的广泛关注。两位大神同时是新兴指令集RISC-V的发起者,也是异构计算领域的领军践行者。本文将结合一个简单实例讲解两位大神所主推的RISC-V如何进行异构计算,让您通过此具体实例理解异构计算为何能够提高性能和节省功耗。
1 工欲善其事,必先利其器之DSA
熟悉计算机体系结构的读者可能早已熟知“异构计算”的概念,异构计算的直接解释是指不同指令集架构的几种处理器组合在一起进行计算,异构计算的精髓并不在于异构本身,其核心的理念在于使用专业的硬件做专业的事情,典型的例子是CPU+GPU的组合,CPU侧重于通用的控制和计算,而GPU则侧重于专用的图像处理。
异构计算的一种具体表现形式是DSA(Domain Specific Architecture,专用领域架构)。著名的计算机体系结构领域泰斗John Hennessy教授在2017年的演讲一次中提到,目前处理器发展的新希望在于专用领域处理器架构(DSA)。作为异构计算的一种具体表现形式,DSA的核心思想同样是使用专用的硬件做专用的事情,但是与ASIC硬件化的电路不同,DSA是满足一个Domain内的应用,而非一个固定的应用,因此它能够满足灵活性与专用性的折衷。同时它需要更多专用领域的专业知识,从而更好地为Domain Specific设计出更合适的架构。
作为异构计算的一种具体表现形式,DSA有时也被解释为Domain Specific Accelerator,即对主处理器适当地扩展出面向某些特定领域的协处理器加速器,这种“Domain Specific Accelerator”是“Domain Specific Architecture”的一种具体体现,能极大地提高能效比。本文便是结合一个简单实例讲解John Hennessy和David Patterson两位大神所主推的RISC-V如何进行协处理器扩展,以帮助读者理解异构计算为何能够提高效能。
2 RISC-V架构的可扩展性
有关新兴RISC-V指令集的诞生和现状,本文在此不做过多赘述,如果对RISC-V尚无了解的读者可以参见《进入32位时代,谁能成为下一个8051》了解相关信息。
RISC-V架构的显著特性之一便是开放的可扩展性,从而能够非常容易在RISC-V的通用架构基础上实现“Domain Specific Accelerator”,这也是RISC-V架构相比ARM和x86等主流商业架构的最大优点。RISC-V的可扩展性体现在两个方面:
预留的指令编码空间
预定义的Custom指令
2.1 RISC-V的预留指令编码空间
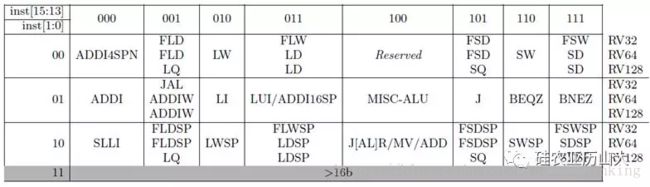
RISC-V架构定义的标准指令集仅使用了少部分的指令编码空间,更多的指令编码空间被预留给用户作为扩展指令使用。由于RISC-V架构支持多种不同的指令长度,不同的指令长度均预留有不同的编码空间。以最常用的32位和16位长度指令为例,如表1和表2所示,指令的低7位为opcode,各种不同的opcode值的组合代表了不同的指令类型,譬如AMO指令和OP-FP(浮点)指令。用户可以从3个方面利用RISC-V预留的编码空间:
每个指令的编码空间,除了用于寄存器操作数的索引之外,还剩余众多位的编码空间,对于这些没有使用的编码空间,用户均可以加以利用。
另外对于某些特定的处理器实现,由于其往往不会实现所有的指令类型,对于没有实现的指令类型的编码空间,用户也可以加以利用。
有一些没有定义的指令类型组,用户也可以加以利用。
表1 RISC-V架构32位指令opcode表(inst[1:0]==11)

表2 RISC-V架构16位指令opcode表
2.2 RISC-V的预定义的Custom指令
为了便于用户对RISC-V进行扩展,RISC-V架构甚至在32位的指令中预定义了4组Custom指令类型,每种Custom均有自己的Opcode。如表1所示,custom-0、custom-1、custom-2和custom-3共4种Custom指令类型。用户可以利用这4种指令类型扩展成为自定义的协处理器指令。本文实例便使用Custom指令扩展协处理器指令。
3 开源蜂鸟E200 RISC-V介绍
蜂鸟E200系列处理器是中国大陆本土研发团队开发并第一个开源RISC-V处理器。蜂鸟是世界上最小的鸟类,其体积虽小却有着极高的速度与敏锐度,可以说是 “能效比”最高的鸟类。E200系列以蜂鸟命名便寓意于此,旨在将其打造成为一款世界上最高能效比的RISC处理器。
蜂鸟E200专为IoT领域量身定做,其具有2级流水线深度,功耗和性能指标均不逊于目前主流商用的ARM Cortex-M系列处理器,且免费开源,能够在IoT领域大有可为。有关蜂鸟E200处理器的具体信息请参见GitHub网址:https://github.com/SI-RISCV/e200_opensource, 在后文中简称为“e200_opensource项目”。
4 蜂鸟E200的协处理器接口EAI
蜂鸟E200处理器核的协处理器机制借鉴了开源RISC-V处理器Rocket Core的协处理器接口RoCC(Rocket Custom Coprocessor),且接口信号定义非常类似.为了将其与原始的RoCC接口进行区分,命名为EAI(Extension Accelerator Interface)。本节将以一个实际案例来详细阐述如何使用EAI接口和Custom指令扩展出蜂鸟E200协处理器。
注意:由于蜂鸟E200处理器核基于Custom指令进行协处理器扩展,因此本文将Custom指令也称之为EAI指令。
4.1 EAI指令的编码
图1 EAI指令编码格式

32位的EAI指令编码格式如图1所示,要点如下:
指令的第0位至第6位区间为Opcode编码段,根据表1中的编码规则使用编码custom-0、custom-1、custom-2和custom-3指令组。
xs1、xs2和xd比特位分别用于控制是否需要读源寄存器rs1、rs2和写目标寄存器rd:
如果xs1位的值为1,则表示该指令需要读取由rs1比特位索引的通用寄存器作为源操作数1;如果xs1位的值为0,则表示该指令不需要源操作数1。
同理,如果xs2位的值为1,则表示该指令需要读取由rs2比特位索引的通用寄存器作为源操作数2;如果xs2位的值为0,则表示该指令不需要源操作数2。
如果xd位的值为1,则表示该指令需要写回结果至由rd比特位指示的目标寄存器;如果xd位的值为0,则表示该指令无需写回结果。
指令的第25位~第31位为funct7区间,可作为额外的编码空间,用于编码更多的指令,因此一种Custom指令组可以使用funct7区间编码出128条指令,则4组Custom指令组共可以编码出512条两读一写(读取两个源寄存器,写回一个目标寄存器)的协处理器指令。如果有的协处理器指令仅读取一个源寄存器,或者无需写回目标寄存器,则可以使用这些无用的比特位(譬如rd比特位)来编码出更多的协处理器指令。
4.2 EAI接口信号
限于篇幅和为了避免陷入过多技术细节,EAI接口的具体信号本文在此不做介绍,感兴趣的读者可以查阅e200_opensource项目doc目录下的Hummingbird_E200_Coprocessor_Extension_Quick_Start_Guide.pdf
4.3 EAI流水线接口
限于篇幅和为了避免陷入过多技术细节,EAI指令在流水线中的执行过程本文在此不做介绍,感兴趣的读者可以查阅e200_opensource项目doc目录下的Hummingbird_E200_Coprocessor_Extension_Quick_Start_Guide.pdf
4.4 EAI存储器接口
支持协处理器访问存储器资源可以扩大协处理器的类型范围,使得协处理器不仅限于运算指令类型。在蜂鸟E200处理器的LSU模块中为EAI协处理器预留了专用的访问接口。因此基于EAI接口的协处理器可以访问主处理器能够寻址的数据存储器资源,包括ITCM、DTCM、系统存储总线、系统设备总线以及快速IO接口等。
限于篇幅和为了避免陷入过多技术细节,EAI指令访问存储器资源的实现机制本文在此不做介绍,感兴趣的读者可以查阅e200_opensource项目doc目录下的Hummingbird_E200_Coprocessor_Extension_Quick_Start_Guide.pdf
4.5 EAI接口时序
限于篇幅和为了避免陷入过多技术细节,EAI接口的若干典型时序本文在此不做介绍,感兴趣的读者可以查阅e200_opensource项目doc目录下的Hummingbird_E200_Coprocessor_Extension_Quick_Start_Guide.pdf
5 蜂鸟E200的协处理器参考示例
本节将通过参考示例,阐述蜂鸟E200处理器如何使用EAI接口定义并实现一个协处理器。注意:本参考示例来源于Rocket-Chip开源项目的一个协处理器教学示例。
5.1 示例协处理器需求
假设有一个N行N列的矩阵按顺序存储在存储器中,矩阵的每个元素都是32位的整数,如图2所示(3行3列的示例矩阵)。需要对该矩阵进行如下操作:
计算逐行的累加和,由于有N行,因此可以得出N个累加的结果,分别是Rowsum1,Rowsum2,Rowsum3,…,Rowsum。
计算逐列的累加和,由于有M列,因此可以得出M个累加的结果,分别是Colsum1,Colsum2,Colsum3,…,Colsum。
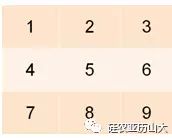
图2 3*3矩阵
如果采用常规的程序进行计算,则需要采用循环方式,按行读取各个元素,然后将各个元素相加得到各行的累加和,然后再采取循环方式,按列读取各个元素,然后将各个元素相加得到各列的累加和,如图3所示。
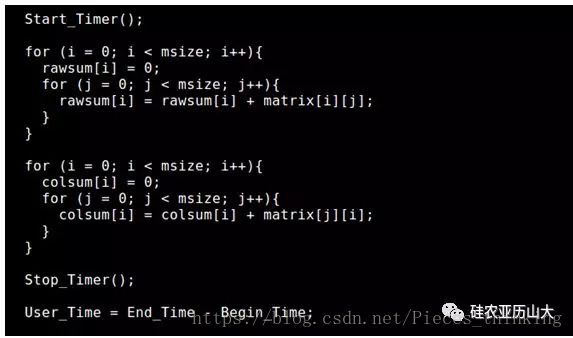
图3 C语言程序计算矩阵行列累加和
这种程序转换成为汇编代码需要消耗较多的指令条数,如图4所示,理论上它需要完整的从存储器中读取矩阵元素两次,第一次用于计算行累加和,第二次用于计算列累加和,因此需要总共NN2次存储器读操作,此外程序还需要指令参与循环控制,累加计算等。假设N=3,则总计需要几十个指令周期才能完成。
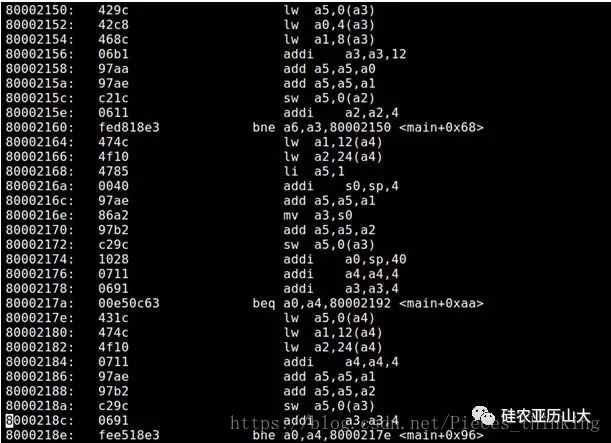
图4 C语言编译所得汇编程序
5.2 示例协处理器指令
为了提高性能和能效比,可以将此矩阵操作定义成为协处理器指令进行加速。如表3所示,定义了3条指令,分别是SETUP、ROWSUM和COLSUM。
表3 示例协处理器指令

5.3 示例协处理器实现
限于篇幅和为了避免陷入过多技术细节,示例协处理器的硬件实现细节本文不做描述,感兴趣的读者可以查阅e200_opensource项目doc目录下的Hummingbird_E200_Coprocessor_Extension_Quick_Start_Guide.pdf
示例协处理器实现方案的处理过程如表4所示。
表4 示例协处理器实现方案

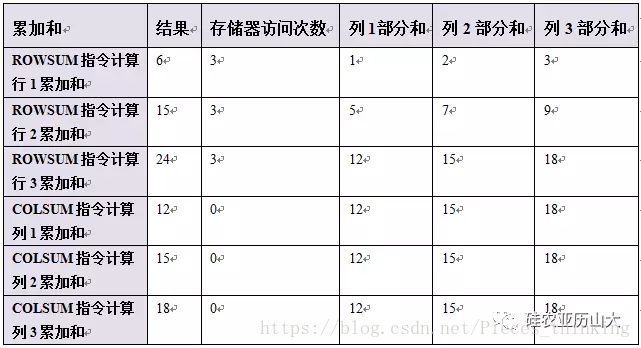
以图2中的矩阵实例为例,使用协处理器后整个计算过程的数值如表5所示。
表5 示例协处理器计算过程的数值
5.4 示例协处理器性能
以图2中的矩阵实例为例子,理论分析示例协处理器的性能如下:
SETUP指令可以在一个周期内完成。
假设矩阵存储在DTCM区间内,可以通过一个周期从DTCM中读回一个矩阵元素,则计算第一行的累加和需要3个时钟周期访问3个存储器地址,采用流水线的方式连续读取和运算(读取一个元素后的累加计算和下一次读取操作重叠),则总共需要4个周期完成第一行的ROWSUM指令。
从第二行开始,不仅需要计算该行的累加和,还需要累加计算得到row_buf中每一列的部分累加和,因此需要额外的3个周期,则总共需要7个周期完成第二行和第三行的ROWSUM指令。
每一个COLSUM指令可以直接从row_buf中取出计算结果,可以在一个周期内完成。
综上,完成全部操作需要7条指令,1+4+7+7+1+1+1=22个时钟周期完成。
与普通的C语言程序实现相比的性能对比如表6所示,在性能和能效比方面就能带来3~5倍的提升。
表6 使用示例协处理器与不使用之性能对比

5.5 示例协处理器代码
对于示例协处理器的代码包括两部分内容:
示例协处理器的Verilog RTL实现代码。
使用协处理器指令的C/C++软件程序代码。
本文在此不予详述其代码,有兴趣的读者可以自行尝试实现或者通过公众号(硅农亚历山大)联系笔者。
6 结语
本文介绍了如何利用RISC-V的可扩展性,并以蜂鸟E200的协处理器接口为例详细阐述如何定制一款协处理器。希望通过此具体实例,能够帮助读者更加深入的理解异构计算的一种具体体现形式——DSA(Domain Specific Architecture,专用领域架构),如何节省功耗提高性能,并且进一步理解RISC-V可扩展性的巨大优势。
注意:限于篇幅和为了避免陷入过多技术细节,很多具体技术细节本文在此未做介绍,感兴趣的读者可以查阅e200_opensource项目doc目录下的Hummingbird_E200_Coprocessor_Extension_Quick_Start_Guide.pdf了解完整版本。
注意:
本文由公众号“硅农亚历山大”原创,转载请注明出处。
本文的完整版也将作为独立一章(第16章)出版于国内第一本系统介绍CPU与RISC-V设计的中文书籍《手把手教你设计CPU:RISC-V处理器》(预计将于2018年3~4月上市)。
更多信息
感兴趣的读者可以通过下面二维码关注公众号“硅农亚历山大”,了解Verilog、 IC设计、CPU、RISC-V和人工智能AI相关的更多设计技巧和经验分享,注意:由于干货太多,请自备茶水。
