opencv3/C++ 机器学习-随机森林/Random Trees
随机森林简介
随机森林由许多决策树组成:通过随机抽取训练样本构建每棵决策树,从特征属性中随机抽取的特征属性中选取最佳分裂属性。
随机森林/Random Forests的一般方法最早由Ho于1995年提出。Leo Breiman在Random Forests中提出随机森林概念,随后与Adele Cutler系统研究和发展了这一理论并注册了商标(包括RF、 RandomForests,、RandomForest,、Random Forest)。大概出于这个原因OpenCV中使用了Random Trees这个名字。OpenCV文档中给出了Random Forests-Leo Breiman and Adele Cutler地址。
随机森林的构建
数据的随机选取
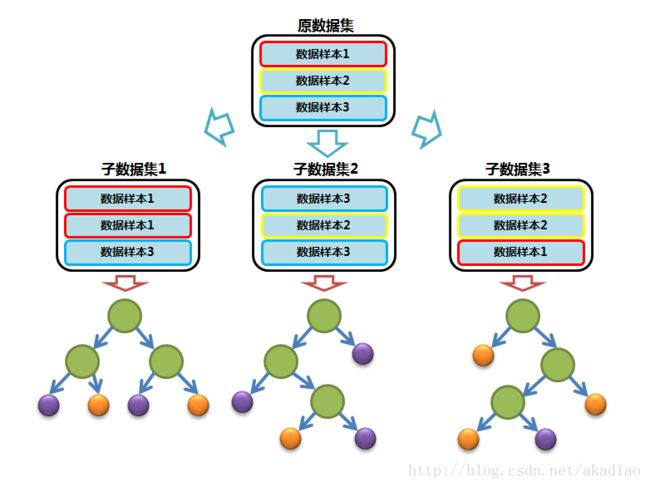
若原始数据集(训练集)大小为N,则从原始数据集中有放回的随机抽取N个训练样本来构建子数据集,然后利用子数据集构建子决策树。由于是有放回地抽取,因此子数据集中的N个样本会有部分重复。
大致过程如图,
待选特征的随机选取
若每个训练样本的特征维度为M,在利用子数据集构建子决策树过程中,子数的每一次分裂过程并非使用所有的特征,而是随机地从M个特征中选取m (m≪M) ( m ≪ M ) 个特征,之后再在随机选取的m个特征中选取最优的特征(利用ID3、C4.5、CART等算法)。
随机选取特征的个数m对于所有节点和所有树都是固定的,OpenCV中默认设置为 number−of−variables−−−−−−−−−−−−−−−−−−−−√ n u m b e r − o f − v a r i a b l e s 。
然后每棵树都尽最大程度的生长,并且没有剪枝过程。
分类问题:随机森林中每棵树进行投票,输出获得大多数投票的类标签。
回归问题:输出随机森林中所有树响应的平均值。
参数m与错误率
特征选择个数m是随机森林中唯一的参数。
m减小时,树的相关性和分类能力会相应降低;m增大时,树的相关性和分类能力会相应增大。
在随机森林中,树的相关性越大,则错误率越大(极端情况:所有的树完全相关,则分类结果也一样,没有bagging的必要);每棵树的分类能力越强,整个随机森林的错误率越低。
因此,需要选择适当的m,以保证每棵树具有较强的分类能力同时树与树间的相关性较低。
带外误差 oob error
袋外(OOB :Out-Of-Bag)误差也称为袋外估计,是一种测量预测误差的方法,适用于随机森林,增强决策树以及其他使用bagging方法抽取子样本的机器学习模型。
在随机森林中,不需要任何准确性估计过程,如交叉验证或自举,或者单独的测试集来获得训练错误的估计。随机森林在生成的过程中就可以对误差建立一个无偏估计。
当通过有放回采样抽取当前树的训练集时,会省略一些样本(所谓的oob(out-of-bag)数据)。 oob数据的大小约为N / 3。
通过使用这个oob数据估计分类错误:
- 使用第i棵树对每个第i棵树的oob数据进行预测。
- 在所有的树都经过训练之后,以多数投票作为该样本的分类结果并将其与实际response相比。
- 用误分类个数与样本总数的比值作为oob-误差(即分类误差估计值)。在回归问题中,oob-误差等于oob数据差的平方误差除以样本总数。
DTrees类
常用函数
static Ptr create();
静态方法使用指定的参数创建空的决策树。virtual void setActiveVarCount(int val);
每个树节点随机选择的特征子集的大小以及用于查找最佳分割的特征的大小。 若为0,则大小将设置为样本总数的平方根。 默认值是0。virtual void setMaxDepth(int val) ;
树的最大可能深度。 训练算法在节点深度小于maxDepth的情况下分割节点。根节点具有零深度。如果符合其他终止标准或修剪树,则实际深度会更小。virtual void setMinSampleCount(int val) ;
节点最小样本数量。若节点中的样本数量小于该值,则不会被分割。默认为10。virtual void setRegressionAccuracy(float val) ;
回归树的终止标准。 若节点中的估计值与该节点中的训练样本的值之间的所有绝对差小于该参数,则该节点不会被进一步分割。 默认值是0.01f。virtual void setUseSurrogates(bool val) ;
若为true,则建立替代分裂点。 这些分裂点可以处理丢失的数据并正确计算变量的重要性。 默认值为false。virtual void setMaxCategories(int val) ;
将分类变量的可能值集中到 K≤maxCategories K ≤ m a x C a t e g o r i e s 个簇中,以找到次优分割。
因为该算法是指数型的,若训练过程中进行分割的离散变量超过了maxCategories,则精确的最佳子集估计可能需要很长时间。 相反情况下,许多决策树引擎通过将所有样本群集到maxCategories个簇中来寻找次优分割,这些聚类将一些类别合并在一起。聚类只适用于多分类问题,且对于分类变量N> max_categories。 在回归和二分类问题中,可以不用聚类。默认值为10。virtual void setCalculateVarImportance(bool val);
如果为true,则在训练阶段计算变量重要性,并可以通过RTrees :: getVarImportance检索。默认值为false。virtual Mat getVarImportance() ;
CalculateVarImportance为true时,在训练阶段计算的变量重要性。 若为false,则返回空矩阵。virtual void setPriors(const cv::Mat &val);
先验类概率数组,按类标签值排序。默认值为空Mat。可用于将决策树偏好调整为某个类别。例如,如果检测一些罕见的异常情况,原训练过程可能包含比异常情况更多的正常情况,因此仅通过将每种情况视为正常就可以实现非常好的分类性能。为避免这种情况,可以指定先验值,人为地增大异常概率(0.5或甚至更大),因此错误分类的异常的权重变得更大,并且树被适当地调整。也可以将此参数视为预测类别的权重,这些预测类别决定了错误分类的相对权重。也就是说,若第一类别的权重为1,第二类别的权重为10,则预测第二类别的每个错误相当于预测第一类别时出现10个错误。virtual void setTermCriteria(const TermCriteria &val);
指定训练算法的终止标准。 默认值是TermCriteria(TermCriteria :: MAX_ITERS + TermCriteria :: EPS,50,0.1)TermCriteria(int type, int maxCount, double epsilon);
type:终止条件的类型,即TermCriteria :: Type之一
maxCount:要计算的最大迭代次数或元素数。
epsilon:期望的精度或迭代停止时的参数变化。
Random Trees示例
使用Random Trees模型创建分类器,对OpenCV自带的数据letter-recognition.data进行处理。
letter-recognition.data内容:
示例:
#include "opencv2/core/core.hpp"
#include "opencv2/ml/ml.hpp"
#include 1, data.rows, CV_8U );
int nvars = data.cols;
Mat var_type( nvars + 1, 1, CV_8U );
var_type.setTo(Scalar::all(VAR_ORDERED));
var_type.at(nvars) = VAR_CATEGORICAL;
//训练数据
Ptr tdata = TrainData::create(data, ROW_SAMPLE, responses, noArray(), sample_idx, noArray(), var_type);
// 创建分类器
Ptr model;
model = RTrees::create();
//树的最大可能深度
model->setMaxDepth(10);
//节点最小样本数量
model->setMinSampleCount(10);
//回归树的终止标准
model->setRegressionAccuracy(0);
//是否建立替代分裂点
model->setUseSurrogates(false);
//最大聚类簇数
model->setMaxCategories(15);
//先验类概率数组
model->setPriors(Mat());
//计算的变量重要性
model->setCalculateVarImportance(true);
//树节点随机选择的特征子集的大小
model->setActiveVarCount(4);
//终止标准
model->setTermCriteria(TermCriteria(TermCriteria::MAX_ITER + (0.01f > 0 ? TermCriteria::EPS : 0), 100, 0.01f));
//训练模型
model->train(tdata);
//保存训练完成的模型
//model->save("filename_to_save.xml");
double train_hr = 0, test_hr = 0;
// 计算训练和测试数据的预测误差
for( int i = 0; i < nsamples_all; i++ )
{
Mat sample = data.row(i);
float r = model->predict( sample );
//判断预测是否正确(绝对值小于最小值FLT_EPSILON)
r = std::abs(r - responses.at<int>(i)) <= FLT_EPSILON ? 1.f : 0.f;
//计数
if( i < ntrain_samples )
train_hr += r;
else
test_hr += r;
}
//训练数据的预测误差
test_hr /= nsamples_all - ntrain_samples;
//测试数据的预测误差
train_hr = ntrain_samples > 0 ? train_hr/ntrain_samples : 1.;
printf( "Recognition rate: train = %.1f%%, test = %.1f%%\n", train_hr*100., test_hr*100. );
//随机森林中的树个数
cout << "Number of trees: " << model->getRoots().size() << endl;
// 变量重要性
Mat var_importance = model->getVarImportance();
if( !var_importance.empty() )
{
double rt_imp_sum = sum( var_importance )[0];
printf("var#\timportance (in %%):\n");
int i, n = (int)var_importance.total();
for( i = 0; i < n; i++ )
printf( "%-2d\t%-4.1f\n", i, 100.f*var_importance.at<float>(i)/rt_imp_sum);
}
return 0;
}

相关链接:
OpenCV3.1.0 : Machine Learning Overview
Wikipedia : Random forest
Wikipedia : Out-of-bag error