VGG-Net论文学习
论文题目《VERY DEEP CONVOLUTIONAL NETWORKS FOR LARGE-SCALE IMAGE RECOGNITION》。
官网地址 http://www.robots.ox.ac.uk/~vgg/software/vgg_face/
摘要
本文章重点研究了卷积神经网络的深度对图像分类准确率的影响,作者使用更小的卷积核(3*3),构建了更深的16-19层的分类网络,取得了更好的分类结果。在2014年的ImageNet比赛上取得了定位第一,分类第二的成绩。
网络结构
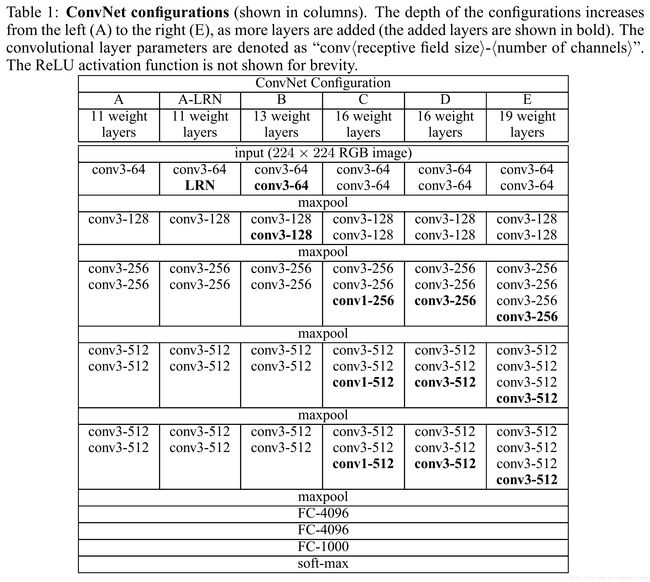

图像预处理:缩放到224224大小,减训练集均值;
网络中使用了11的卷积,对输入通道进行线性变化,然后再通过非线性函数增强非线性表达能力;
卷积层的padding值的目的是保证卷积层输入和输出有相同的空间尺寸;
某些卷积层后使用了池化层;
LRN层没用。
网络中使用了33的卷积核,两个33卷积层的感受野和单个55的卷积层的感受野相同,三个33卷积层的感受野和单个7*7的卷积层的感受野相同。使用更小的卷积核的好处是:
- 增强了网络的非线性表达能力,因为相比于单卷积层使用的单个非线性函数,三个卷积层后共使用了三个非线性函数,因此模型具有更强的非线性表达能力,学习到的决策函数判别力更强;
- 可以减小参数数量,防止过拟合。例如,假设当前卷积层的输入和输出都是C个channel,那么使用77的单层卷积层时的参数数量时 7 ∗ 7 ∗ C 2 = 49 C 2 7*7*C^2=49C^2 7∗7∗C2=49C2,但使用3个33的卷积层时的参数数量是 3 ∗ 3 ∗ 3 ∗ C 2 = 27 C 2 3*3*3*C^2=27C^2 3∗3∗3∗C2=27C2,明显后者的参数数量更少,过拟合的风险更小。
结构C中使用了1 * 1的卷积,虽然这里1 * 1卷积的输入channel数和输出chanel数相同,但依然进行了跨通道的线性变换,但是在1 * 1卷积之后使用的非线性激活函数同样增强了模型的非线性表达能力。
训练和验证细节
训练阶段
损失函数使用softmax loss;
最优化算法使用带冲量的批SGD;batchsize 256,momentum 0.9;
L 2 L_2 L2正则化项,正则化强度 5 ∗ 1 0 − 4 5*10^{-4} 5∗10−4,前两个全连接层使用系数为0.5的dropout;
初始化学习率0.01,验证集准确率停止上升时学习率变为原来的0.1倍;
74个epoch,370K次迭代。
模型A随机初始化参数,从头训练;其他模型和模型A相同的层用模型A的参数进行初始化,其余层随机初始化,在训练过程中使用模型A参数的层使用同样的学习率跟随训练。随机初始化时 W W W按照均值为0、方差0.01进行初始化, b b b初始化为0。
数据增广:图像随机水平翻转和随机的RGB颜色变化。
模型的输出大小为224224,任何大于该尺寸的图像都可以作为输入,可以从大于该尺寸的输入图像上裁剪224224的块送入模型进行训练。
作者进行了两种方法的来构建训练集图像:
- 从固定尺寸的图像上选取224*224的crop,尺寸有两种,一种是S = 384,一种是S = 256;
- 原始训练集图像的尺寸不固定, S ∈ [ 256 , 512 ] S \in [256,512] S∈[256,512],然后再crop 224*224的图像块,这种方法也可以看作是尺度变化进行图像增广的方法。
测试阶段
测试阶段没有进行图像的裁剪处理,而是通过卷积层实现了全连接层的功能,这样就可以对任意大于224*224尺寸的输入图像一次前向计算过程得到分类结果,得到的分类结果为一个3维的score map,该map的通道数为总的类别数,空间尺寸和输入图像的尺寸相关。对该score map进行空间上求平均操作,可以得到其属于各类别的score值。作者对测试集图像也进行了水平翻转,两幅图像得到的score map再求平均得到最终的分类结果。
使用上述方法,不需要对单幅图像进行多次crop和多次前向计算的操作,效率更高。
但作者提到,使用多次crop前向计算的方式,得到的分类准确率更高,这是因为相比于全卷积网络,多次crop是对卷积得到的feature map进行补0操作,而全卷积的方式padding信息来自于图像的领域,增强了整个网络的局部感受野,获取了更多的纹理,所以效果略差(???不理解)。
实验结果
测试图像单尺度验证实验
对于固定S训练出的模型,测试集的尺寸Q=S;
对于可变S训练出的模型,测试集的尺寸 Q = 0.5 ( S m i n + S m a x ) Q=0.5(S_{min}+S_{max}) Q=0.5(Smin+Smax);

模型A和模型A-LRN的对比说明LRN层没有起到正面的作用;
随着模型深度的加大,分类的准确率越来越好;
C的准确率好于B,劣于D,一方面说明了1 * 1的卷积增强了非线性操作,对分类有正面效果;另一方面也说明了更大的卷积核获取了更多的纹理特征,有助于正确分类;
当网络层数达到19层之后,分类错误率达到了饱和状态,但是更大的数据集下可以使用更深的网络;
另外对网络B,使用一个5 * 5的卷积替代一对3 * 3卷积,错误率会上升,说明了使用更深的小卷积核的网络效果要优于使用更大卷积核的浅层网络;
训练过程中进行尺度的变化,对分类准确率有正面的提升,多尺度的训练图像有助于网络学习图像多尺度的统计信息。
测试图像多尺度验证实验
训练集固定S的模型,测试集选取三个尺度{S-32,S,S+32};
训练集变化的模型, S ∈ [ S m i n , S m a x ] S \in [S_{min},S_{max}] S∈[Smin,Smax],测试集的尺寸 Q = { S m i n , 0.5 ( S m i n + S m a x ) , S m a x } Q=\{S_{min},0.5(S_{min}+S_{max}),S_{max}\} Q={Smin,0.5(Smin+Smax),Smax}。

测试集进行多尺度的变换,对准确率有提升;
网络模型深度越大,准确率越高;
对训练集进行尺度变换,准确率有提升。
多组crop vs 全卷积

多组crop的准确率更高;
多组crop和全卷积联合用准确率最高,这是因为两者对边界的处理方式不同,起到了互补的作用。
多模型结果融合
对多个模型得到的softmax score进行求平均操作,增强了分类的准确率;

对比其他算法
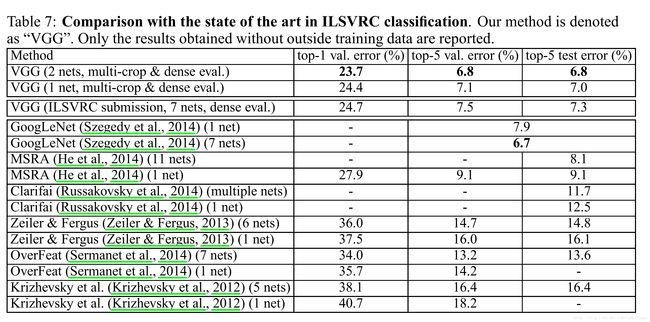
ILSVRC-2014分类第二,略次于GoogleNet。
总结
论文验证了CNN深度的影响,对后续计算机视觉领域内CNN的发展起到了指导性的作用。
附录
ILSVRC-2014,定位第一,使用16层的模型D,模型的输出是四个值,分别为bounding box中心点坐标及框的宽高,将损失函数由softmax loss换成计算出的bounding box与ground-truth之间的欧氏距离。
同时还给出了实验结果证明了文章中的做法也可以很好的适用于其他的数据集。