模型融合之stacking和blending
1.stacking
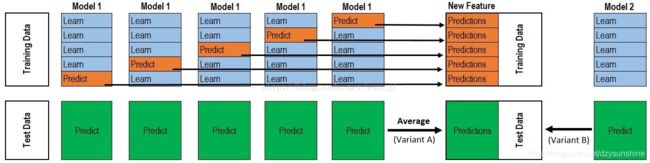
上半部分是用一个基础模型进行5折交叉验证,如:用XGBoost作为基础模型Model1,5折交叉验证就是先拿出四折作为training data,另外一折作为testing data。注意:在stacking中此部分数据会用到整个traing set。如:假设我们整个training set包含10000行数据,testing set包含2500行数据,那么每一次交叉验证其实就是对training set进行划分,在每一次的交叉验证中training data将会是8000行,testing data是2000行。
每一次的交叉验证包含两个过程,1. 基于training data训练模型;2. 基于training data训练生成的模型对testing data进行预测。在整个第一次的交叉验证完成之后我们将会得到关于当前testing data的预测值,这将会是一个一维2000行的数据,记为a1。注意!在这部分操作完成后,我们还要对数据集原来的整个testing set进行预测,这个过程会生成2500个预测值,这部分预测值将会作为下一层模型testing data的一部分,记为b1。因为我们进行的是5折交叉验证,所以以上提及的过程将会进行五次,最终会生成针对testing set数据预测的5列2000行的数据a1,a2,a3,a4,a5,对testing set的预测会是5列2500行数据b1,b2,b3,b4,b5。
在完成对Model1的整个步骤之后,我们可以发现a1,a2,a3,a4,a5其实就是对原来整个training set的预测值,将他们拼凑起来,会形成一个10000行一列的矩阵,记为A1。而对于b1,b2,b3,b4,b5这部分数据,我们将各部分相加取平均值,得到一个2500行一列的矩阵,记为B1。
以上就是stacking中一个模型的完整流程,stacking中同一层通常包含多个模型,假设还有Model2: LR,Model3:RF,Model4: GBDT,Model5:SVM,对于这四个模型,我们可以重复以上的步骤,在整个流程结束之后,我们可以得到新的A2,A3,A4,A5,B2,B3,B4,B5矩阵。
在此之后,我们把A1,A2,A3,A4,A5并列合并得到一个10000行五列的矩阵作为training data,B1,B2,B3,B4,B5并列合并得到一个2500行五列的矩阵作为testing data。让下一层的模型,基于他们进一步训练
2.blending
Blending相较于Stacking来说要简单一些,其流程大致分为以下几步:
将数据划分为训练集和测试集(test_set),其中训练集需要再次划分为训练集(train_set)和验证集(val_set);
创建第一层的多个模型,这些模型可以使同质的也可以是异质的;
使用train_set训练步骤2中的多个模型,然后用训练好的模型预测val_set和test_set得到val_predict, test_predict1;
创建第二层的模型,使用val_predict作为训练集训练第二层的模型;
使用第二层训练好的模型对第二层测试集test_predict1进行预测,该结果为整个测试集的结果。
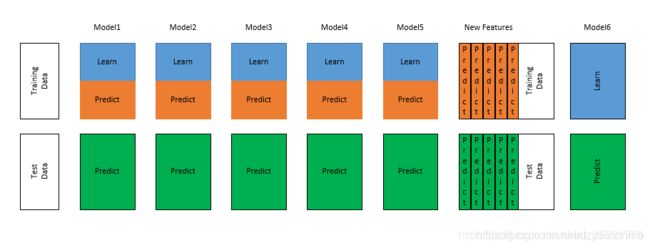
Blending与Stacking大致相同,只是Blending的主要区别在于训练集不是通过K-Fold的CV策略来获得预测值从而生成第二阶段模型的特征,而是建立一个Holdout集,例如10%的训练数据,第二阶段的stacker模型就基于第一阶段模型对这10%训练数据的预测值进行拟合。说白了,就是把Stacking流程中的K-Fold CV 改成 HoldOut CV。
Blending的优点在于:
1.比stacking简单(因为不用进行k次的交叉验证来获得stacker feature)
2.避开了一个信息泄露问题:generlizers和stacker使用了不一样的数据集
3.在团队建模过程中,不需要给队友分享自己的随机种子
而缺点在于:
1.使用了很少的数据
2.blender可能会过拟合(其实大概率是第一点导致的)
3.stacking使用多次的CV会比较稳健
参考:https://blog.csdn.net/wstcjf/article/details/77989963
https://blog.csdn.net/sinat_35821976/article/details/83622594