把Tacotron2拆开来看
要说明白的那些事
- Tacotron2相关的资料
- Tacotron2整体框架
- 细节及代码讲解
- 模型输入
- 编码器Encoder
- 注意力机制Attention介绍
- 解码器Decoder && 注意力
- 损失函数
- 结语
Tacotron2相关的资料
李宏毅的相关讲解视频:帮你了解语音合成的周边以及Tacotron2 与 Tacotron 的区别
论文地址:看再多论文解读的博客也不如看一下原文来得效果好,至少得结合着看。
Pytorch版代码:NVIDIA开源的 Tacotron2 代码,也是本文所参考的代码
看完以上的视频以及论文之后就可以继续往下看本文了!
Tacotron2整体框架
Tacotron2 是Google Brain 在2017年提出来的一个端到端的语音合成框架,其合成出的语音效果MOS非常接近人声,算是目前最好的语音合成框架了。其前身是Tacotron,但其实跟Tacotron在网络结构各方面差别很大,所以即使不了解Tacotron也不会妨碍学习Tacotron2。
总体上,Tacotron2 模型主要由两部分组成:
- 声谱预测网络:整体上是一个Seq2Seq模型,用于根据输入的字符序列预测梅尔频谱的帧序列。有编码器Encoder、注意力机制Attention、解码器Decoder,但是Attention是与Encoder紧密联系在一起的。
- 声码器:一个基于WaveNet的修订版,用声谱预测网络预测得到的 低层次的声学特征-梅尔频率声谱图 来生成时域波形即语音。
下面是论文中给出的Tacotron2 各模块之间的连接图:
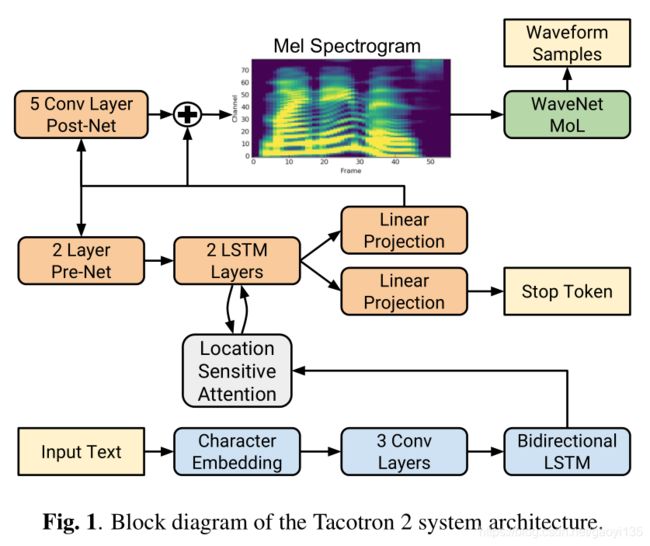
直接看这个图看不明白很正常,因为有太多的实现细节是这个图所没有的,所以没关系,先不要纠结这个图,等看完本文全部内容后再回头来看这个图,可能会好一些。
细节及代码讲解
下面我们以怎么把 “美女给个微信呗” 这句话通过Tacotron2 生成语音输出为例,带着大家去了解模型是怎么一步一步运作的。
以下部分所使用的代码均来自NVIDIA开源的 Tacotron2 代码,但只是抽取出模型讲解相关的部分,且为了简化讲解,让大家把握模型的重点,网络层的定义什么的不会严格按照标准来写,但你能保证看懂就是了,可以理解为模型“伪代码”。
整体模型数据流向图:

模型输入
该模型号称端到端,也就是说你输入字符序列,它就能帮你生成语音,但是也不是说你直接给模型喂中文就行,你需要将上述中文句子预处理生成对应的拼音序列或者是音素序列,这里以拼音序列为例。
“美女给个微信呗” 转化成拼音也就是得到:" mei2nv3gei3ge4wei1xin4bei5 "
转化成拼音后还是不能直接输入到网络模型当中,这中间还有一步就是拼音序列到数字的映射,也就是我们要输入到模型的是一串数字,那这串数字怎么来?如果你的输入只是拼音序列,没有标点符号或者是韵律符号的话,那么很简单,你可以构造这样的一个的一个字典进行映射(其实有标点字符或者韵律符号也一样,直接在字典中加相关符号就行):
字典:[12345abcdefghijklmnopqrstuvwxyz] (其中的12345是拼音音调,后面的字母是拼音的字符)
通过这个字典,你就可以将上述拼音序列映射到字典中获取拼音字符在字典中的索引位置,于是得到:
模型输入inputs:[17, 9, 13, 1, 18, 26, 2, 11, 9, 13, 2, 11, 9, 3, 27, 9, 13, 0, 28, 13, 18, 3, 6, 9, 13, 4]
即输入到模型的字符序列长度为:char_seq_length = 26

编码器Encoder
在Tacotron2中,编码器将输入序列 X = [ x 1 , x 2 , … , x T x ] X=[x_1,x_2,…,x_{Tx}] X=[x1,x2,…,xTx] 映射成序列 H = [ h 1 , h 2 , … , h T x ] H=[h_1,h_2,…,h_{T_x}] H=[h1,h2,…,hTx] ,其中序列H被称作“编码器隐状态”(encoder hidden states)。注意:编码器的输入输出序列都拥有相同的长度, h i h_i hi之于相邻分量 h j h_j hj 拥有的信息等价于 x i x_i xi 之于 x j x_j xj 所拥有的信息。
编码器模块包含一个字符嵌入层(Character Embedding),一个3层卷积,一个双向LSTM层。

# 简单起见,我们这里的输入是一句话,但是在实际训练当中是很多句组成一个batch size 喂给模型的,因此我输入的规格为:[B, 26] (我们这里的 B=1, 26=char_seq_length)
inputs = [17, 9, 13, 1, 18, 26, 2, 11, 9, 13, 2, 11, 9, 3, 27, 9, 13, 0, 28, 13, 18, 3, 6, 9, 13, 4]
# 输入Inputs在进入到网络层之前是需要转成tensor类型的,这里就忽略了。
# 编码器把输入字符编码成512维的字符向量
# 其中self.embedding定义如下:
self.embedding = torch.nn.Embedding(31, 512) # 31是上面构造的字典的长度,512是你设定的字符向量的长度
embedded_inputs = self.embedding(inputs).transpose(1,2) # 得到embedded_inputs的规格为 [B, 512, 26]
# 接着要穿过三层的一维卷积,每层卷积包含512个5x1的卷积核,即每个卷积核横跨5个字符,卷积层会对输入的字符序列进行大跨度上下文建模(类似于N-grams),这里使用卷积层获取上下文主要是由于实践中RNN很难捕获长时依赖;卷积层后接批归一化(batch normalization),使用ReLu进行激活;
from torch.nn imort functional as F
x = embedded_inputs
conv = torch.nn.Conv1d(in_channels=512, out_channels=512, kernel_size=5, stride=1, padding=2, dilation=1, bias=True) # 一维卷积之后需要接batch normalization即 torch.nn.BatchNorm1d(512), 512是卷积输出的字符向量维度长度
for conv in self.convolutions: # self.convolutions是一个包含三个以上conv一维卷积层的模型列表nn.ModuleList
x = F.dropout(F.relu(conv(x)), 0.5, self.training) # self.training在train模式下为True,eval模式下为False
x = x.transpose(1, 2)
# 最后一个卷积层的输出被传送到一个双向的LSTM层用以生成编码特征,这个LSTM包含512个单元(每个方向256个单元)。
self.lstm = nn.LSTM(512, int(512/2), 1, batch_first=True, bidirecitonal=True) # 即输入为512维,每层LSTM的输出是int(512/2)=256维,bidirectional=True即使用双层LSTM,因此两层LSTM输出接在一起变得得到512维的输出
encoder_outputs, _ = self.lstm(x) # Encoder最终输出的规格为 [B, 26, 512]
注意力机制Attention介绍
具体的注意力机制计算可以参考这篇博客。
Tacotron2中使用了基于位置敏感的注意力机制(Attention-Based Models for Speech Recognition),是对之前注意力机制的扩展(Neural machine translation by jointly learning to align and translate),扩展的地方在于其使用了累加注意力权重,可以使得注意力权重网络了解它已经学习到的注意力信息,使得模型能在序列中持续进行并且避免重复未预料的语音。因此Tacotron2的注意力机制能够同时考虑内容和输入元素的位置。
公式为:
e i , j = s c o r e ( s i , c α i − 1 , h j ) = v a T t a n h ( W s i + V h j + U f i , j + b ) e_{i, j} =score(s_i, c\alpha_{i-1}, h_j)=v_a^Ttanh(Ws_i+Vh_j+Uf_{i,j}+b) ei,j=score(si,cαi−1,hj)=vaTtanh(Wsi+Vhj+Ufi,j+b)
其中, s i s_i si为当前当前解码器隐状态(其实在实现的时候使用的是attention cell的隐状态,往下看就明白了), h j h_j hj为当前编码器的隐状态(实现上时将编码器的输出输入到一维卷积层后得到),位置特征 f i f_{i} fi使用累加注意力权重 c α i c\alpha_i cαi卷积而来:
f i = F ∗ c α i − 1 c α i = ∑ j = 1 i − 1 α j f_i=F*c\alpha_{i-1}\\c\alpha_i=\sum_{j=1}^{i-1}\alpha_j fi=F∗cαi−1cαi=j=1∑i−1αj
解码器Decoder && 注意力
这里将注意力跟解码器综合到一起来分析是因为解码器每一步的输出都要用到注意力输出的注意力上下文向量attention context ,而解码器的输出又会作为注意力机制输入的一部分参与运算,因此两个部分是密切不可分的,下面分析完代码就能体会到了!
首先要说明的是解码器每一步输出的数据是 [B, n_mel_channels * n_frames_per_step],n_mel_channels也就是生成到的梅尔特征的维度,论文中使用的 n_mel_channels=80,n_frames_per_step就是一个时间步生成的帧数,Tacotron中这个参数是3,而Tacotron2中这个参数是1。
解码器使用的是LSTM,输出有两个分支,一个分支的每一个时间步都会输出 [B, n_mel_channels] 的数据,另外一个分支每一个时间点会输出一个控制门data,这个控制门data的 sigmoid(data) 值大于设定的阈值0.5时,整个解码器的工作便结束。另外如果sigmoid(data) 一直小于阈值0.5,而输出的时间步超过1000时,解码器工作也会停止,即控制解码器工作结束的方式有两种。
# 我们上面说了,注意力向量的计算需要用到解码器的输出,解码器的输出也要用到注意力的输出,两者构成了一个循环
# 注意力网络的输入由两部分concat而成,一是解码器输出经过prenet后的数据,二是其自身输出的注意力上下文向量
# 但是最开始的时候解码器还没有输出,注意力也没有输出,怎么计算注意力呢?方法是先构造一个全为零的数据当做解码器的输出,构造一个全为零的数据当做是注意力层的输出
decoder_input = torch.zeros(batch_size, 80) # 初始化一个全为零的数据充当解码器的输出作为原始输入 [B, 80]
self.attention_context = torch.zeros(batch_size, 512) # 注意力上下文向量的维度为512,跟编码器词向量的维度是一样的
self.attention_weights = torch.zeros(B, 26) # 注意力权重,最开始先初始化为0
self.attention_weights_cum = torch.zeros(B, 26) # 注意力权重的累加
self.memory = encoder_outputs # 我们这里将编码器的输出成为memory
while True:
# prenet就是两层全连接层,第一层的input_channels为80,output_channels为256,第二层的input_channels为256,output_channels为256。且每层全连接层后面都有接激活函数F.relu()和F.dropout(0.5)
decoder_input = self.prenet(decoder_input) # 前一步解码器的输出mel频谱的数据经过prenet后变成 [B, 256]
attention_cell_input = torch.cat((decoder_input, self.attention_context), -1) # concat之后作为attention cell的输入,数据规格为 [B, 256+512=768]
# 接着这个便作为attention cell的输入,attention cell就是attention层的LSTM网络的一个cell,与LSTM不同的是它的每一步输出的隐状态都可以取出来,这里的LSTMCell的input_channels=768, output_channels=1024。
# self.attention_hidden, self.attention_cell即LSTM单元输出的ht和ct,最开始都是初始化为全零的[B, 1024]
self.attention_hidden, self.attention_cell = torch.nn.LSTMCell(attention_cell_input, (self.attention_hidden, self.attention_cell)) # 规格为[B, 1024]:这里得到的self.attention_hidden会参与到注意力权重的计算
attention_weights_cat = torch.cat(self.attention_weights.unsqueeze(1), self.attention_weights_cum.unsqueeze(1), dim=1) # 规格为[B, 2, 26]:上一时间步的注意力权重会与以前积累的注意力权重concat到一起,参与到当前注意力权重和注意力上下文的计算当中
self.attention_context, self.attention_weights = self.attention_layer(self.attention_hidden, self.attention_weights_cat, self.memory)
# self.attention_layer实现的就是上述注意力机制的公式
# self.attention_hidden就是公式中的s_{i-1},Ws_{i-1}的计算方法为将s_{i-1}输入到一维卷积中得到,维度规格为[B, 1, 128]
# self.attention_weights_cat就是公式中的f_{i,j},用于计算位置注意力权重,Uf_{i,j}的计算方法是将h_j输入到一个二维卷积和一个全连接层中
# h_j的规格为[B, 2, 26],经过二维卷积后规格变为[B, 32, 26],经过全连接层后变为[B, 26, 128]
# self.memory用于计算编码器的隐状态,计算方法是将self.memory输入到一个全连接层中映射得到,规格从[B, 26, 512]变成[B, 26, 128]
# 我们假设以上三个输入经过上述所讲的处理之后分别变成processed_query, processed_attention_weights, processed_memory
# 于是 self.attention_layer做的就是:
self.attention_weights = torch.nn.Linear(torch.tanh(processed_query + processed_attention_weights + processed_memory)) # 规格为[B, 26, 1]
self.attention_weights = self.attention_weights.unsqueeze(-1) #变成[B, 26]
self.attention_weights = F.softmax(self.attention_weights, dim=1) # 注意力得分归一化
self.attention_context = torch.bmm(self.attention_weights.unsqueeze(1), self.memory).squeeze(1) # 让注意力得分与编码器输出做矩阵相乘,便得到了注意力的上下文向量,
# 到这里注意力机制也就计算完了,因为是while循环会一直计算下去,所以下面要更新一下变量
self.attention_weights_cum += self.attention_weights # 注意力累加
上面便是注意力机制的计算,注意力cell隐状态和上下文向量计算出来之后,用作后面解码器的输入(注意以下代码还是在while循环当中)
decoder_input = torch.cat((self.attention_hidden, self.attention_context), dim=-1) # 规格为[B,1024+512=1536]
self.decoder_hidden, self.decoder_cell = torch.nn.LSTMCell(decoder_input, (self.decoder_hidden, self.decoder_cell)) # 规格为[B, 1024]:这里self.decoder_hidden, self.decoder_cell同样最开始是初始化为全零
# 最后mel频谱预测层的输入是decoder cell隐状态和注意力上下文向量的concat,规则为 [B, 1024+512]
decoder_hidden_attention_context = torch.cat((self.decoder_hidden, self.attention_context), dim=1)
mel_outputs = torch.nn.Linear(decoder_hidden_attention_context) # 规格为[B, 80],这里便得到了输出的mel频谱,用一个数组将每一个时间步输入的mel_output装起来,作为后续postnet的输入
# 但同时,decoder_hidden_attention_context会输入到另一个全连接层中,输出一个控制门数值
gate_prediction = torch.nn.Linear(decoder_hidden_attention_context) # 当这个值超过设定的阈值0.5时,解码器工作停止,输出结束
# 以上输出的mel频谱还要经过一个5层一维卷积的后处理层PostNet,然后相加
mel_outputs_postnet = self.postnet(mel_outputs) # postnet就是5层的一维卷积层,中间隐藏层的channels数为512, 卷积核大小为5,输出层的channels还是80
mel_outputs_postnet = mel_outputs_postnet + mel_outputs
得到mel频谱特征的输出之后,后面的工作就交给WaveNet了,本文暂时先不讲解WaveNet相关的处理。
损失函数
L o s s = 1 n ∑ i = 1 n ( y r e a l , i − y i ) 2 + 1 n ∑ i = 1 n ( y r e a l , i − y f i n a l , i ) 2 + λ ∑ j = 1 p w j 2 Loss=\frac{1}{n}\sum_{i=1}^{n}(y_{real, i}-y_i)^2+\frac{1}{n}\sum_{i=1}^{n}(y_{real, i}-y_{final,i})^2+\lambda\sum_{j=1}^pw_j^2 Loss=n1i=1∑n(yreal,i−yi)2+n1i=1∑n(yreal,i−yfinal,i)2+λj=1∑pwj2
其中, y r e a l , i y_{real,i} yreal,i为真实语音提取得到的mel频谱特征, y i y_i yi、 y f i n a l , i y_{final,i} yfinal,i分别为进入后处理网络前、后的mel频谱,n为batch中的样本数, λ \lambda λ为正则化系数, p p p为模型的参数总数, w w w为模型的参数,但需要注意的是这里的参数是不包含偏置值bias的。若正则化了偏置值,则意味着在寻找模型最优解的过程中将模型限制在了原点附近,而往往最优解并不在原点附近。
结语
模型整体比较复杂,不敢保证以上自己梳理的东西完全没有错误,如有错误请在评论区指出,我会及时修正过来!
一起学习~