算法研究---MNIST数据集
MNIST简介
MNIST(Mixed National Institute of Standards and Technology database)是一个计算机视觉数据集,它包含70000张手写数字的灰度图片,其中每一张图片包含 28 X 28 个像素点。
每一张图片都有对应的标签,也就是图片对应的数字,例如上面这张图片的标签就是 1。
数据集格式:
60000行的训练数据集是一个形状为 [60000, 784] 的张量,第一个维度数字用来索引图片,第二个维度数字用来索引每张图片中的像素点。在此张量里的每一个元素,都表示某张图片里的某个像素的强度值,值介于 0 和 1 之间。每一个像素点用一个utf-8来表示。范围是0~255,0表示是黑色(背景色),255表示白色(前景色)

标签集格式(???):
60000行的训练数据标签集是一个形状为 [60000, 10] 的张量。采用one-hot vectors来表示0~9之间数字,从0开始到9,总共10个位置。一个one-hot向量是[1,10]的张量,每一次只有一个维度上面的数字是1,其他各个维度的数字都为0。数字n表示为一个只有在第n个维度为1的1*10的向量。表示如下:
60000行的训练数据标签集是一个形状为[60000,1]的张量。每个维度表示对应的标签值,标签的访问是0~9。
下载
MNIST下载地址:http://yann.lecun.com/exdb/mnist/, 从官方网站下载的数据是gz格式的压缩包,解压后可以得到原始文件。mnist数据集包含4个文件,分别对应60000个训练图片,60000个训练标签,10000个测试图片,10000个测试标签。数据集被分成两部分:60000 行的训练数据集(mnist.train)和10000行的测试数据集(mnist.test)。其中:60000 行的训练集分拆为 55000 行的训练集和 5000 行的验证集。
train-images-idx3-ubyte.gz: 60000个训练图片 (9912422 bytes)
train-labels-idx1-ubyte.gz: 60000个训练标签 (28881 bytes)
t10k-images-idx3-ubyte.gz: 10000个测试图片 (1648877 bytes)
t10k-labels-idx1-ubyte.gz: 10000个测试标签 (4542 bytes)
文件格式
train-images-idx3-ubyte.gz解压之后会生成一个train-images.idx3-ubyte的文件。该文件的格式如下:
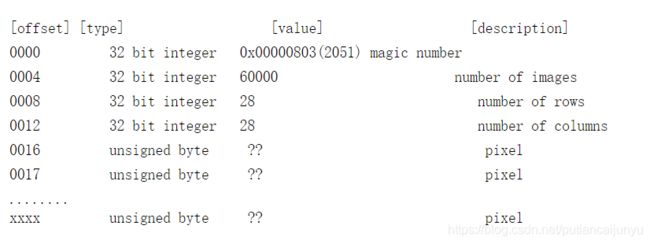
Pixels are organized row-wise. Pixel values are 0 to 255. 0 means background (black), 255 means foreground (white).
train-labels-idx1-ubyte.gz解压之后,会生成train-labels.idx1-ubyte的文件,文件格式如下:

The labels values are 0 to 9.
t10k-images-idx3-ubyte.gz解压之后,会生成一个t10k-images.idx3-ubyte的文件,其格式如下:

Pixels are organized row-wise. Pixel values are 0 to 255. 0 means background (black), 255 means foreground (white).
t10k-labels-idx1-ubyte.gz解压之后,生成t10k-labels.idx1-ubyte的文件,格式如下:

The labels values are 0 to 9.
MNIST数据预处理
基于上个章节中提到的4个文件的数据格式,我们可以将data进行预处理,分割出图像文件出来。
在处理binary数据之前,需要特别注意的是MNIST数据集是采用大端格式(高字节优先,即数字0x01020304在内存中存储的情况是(从低地址到高地址)0x01,0x02,0x03,0x04)。
import numpy as np
import struct
import matplotlib.pyplot as plt
import time as time
TrainImgfilename = r'/home/yml/桌面/mnist/train-images.idx3-ubyte'
TIbinfile = open(TrainImgfilename,'rb')
TIbuf = TIbinfile.read()
TrainLabelFileName = r'/home/yml/桌面/mnist/train-labels.idx1-ubyte'
TLbinfile = open(TrainLabelFileName,'rb')
TLbuf = TLbinfile.read()
TIindex = 0
TLindex = 0
TImagic,TInumImages,TInumRows,TInumColumn = struct.unpack_from('>IIII',TIbuf,TIindex)
TIindex += struct.calcsize('>IIII')
TLmagic,TLnumLabel = struct.unpack_from('>II',TLbuf,TLindex)
TLindex += struct.calcsize('>II')
fig = plt.figure()
plotwindow = fig.add_subplot(111)
for i in range(TInumImages):
im = struct.unpack_from('>784B',TIbuf,TIindex)
TIindex += struct.calcsize('>784B')
im = np.array(im)
im = im.reshape(28,28)
label = struct.unpack_from('>B', TLbuf,TLindex)
TLindex += struct.calcsize('>B')
print(label)
label = label[0]
plt.title('true number :%d'%label)
plt.axis('off')
plt.imshow(im,cmap='gray')
plt.pause(1)
TIbinfile.close()
TLbinfile.close()
plt.close()
参考文献
【1】https://blog.csdn.net/chekongfu/article/details/85555389
【2】https://yq.aliyun.com/ziliao/550948