论文阅读笔记|论文总结 AdaGAN、GAIL、SeqGAN等四篇
论文总结
文章目录
- 论文总结
- AdaGAN: Boosting Generative Models
- A Connection Between GAN, IRL and EBM
- Generative Adversarial Imitation Learning
- Motivation
- Summary
- Deficiency
- SeqGAN
- Motivation
- Summary
- Deficiency
- Diss
AdaGAN: Boosting Generative Models
AdaGAN论文阅读笔记
A Connection Between GAN, IRL and EBM
###Motivation

Then maximizing likelihood will lead to a distribution which “covers” all of the modes, but puts most of its mass in parts of the space that have negligible density under the data distribution.
A generator trained adversarially will instead try to “fill in” as many of modes as it can.
Complex multimodal distribution很难通过maximize likelihood评估密度分布。它会将尽可能地覆盖 P d a t a P_{data} Pdata而使其 P G P_{G} PG主要分布在各个mode之间的空白区域;而GAN则会尽量填满 P d a t a P_{data} Pdata而使 P G P_G PG更接近 P d a t a P_{data} Pdata。
###Summary
IRL methods are in fact mathematically equivalent to GANs.
In particular, a sample-based algorithm for maximum entropy IRL and a GAN.
Definition
Boltzmann distribution
p θ ( τ ) = 1 Z e − E θ ( τ ) p_{\theta}(\tau)=\frac{1}{Z}e^{-E_{\theta}(\tau)} pθ(τ)=Z1e−Eθ(τ).
Partition function
Z = ∫ e − E θ ( x ) d x Z=\int{e^{-E_{\theta}(x)}dx} Z=∫e−Eθ(x)dx.
Discriminator loss
L d i s c r i m i n a t o r ( D ) = E x ∼ p [ − log D ( x ) ] + E x ∼ G [ − log ( 1 − D ( x ) ) ] \mathcal{L}_{discriminator}(D)=\Bbb{E}_{x \sim p}[-\log D(x)]+\Bbb{E}_{x \sim G}[-\log (1-D(x))] Ldiscriminator(D)=Ex∼p[−logD(x)]+Ex∼G[−log(1−D(x))].
Generator loss
L g e n e r a t o r ( G ) = E x ∼ G [ − log D ( x ) ] + E x ∼ G [ log ( 1 − D ( x ) ) ] \mathcal{L}_{generator}(G)=\Bbb{E}_{x \sim G}[-\log D(x)]+\Bbb{E}_{x \sim G}[\log (1-D(x))] Lgenerator(G)=Ex∼G[−logD(x)]+Ex∼G[log(1−D(x))].
Calculation
使用cost function c θ c_{\theta} cθ表示energy E θ E_{\theta} Eθ。
Z = ∫ e − c θ ( τ ) d τ Z=\int{e^{-c_{\theta}(\tau)}d\tau} Z=∫e−cθ(τ)dτ
使用sampling distribution q ( τ ) q(\tau) q(τ)估算 Z Z Z。
L c o s t ( θ ) = E τ ∼ p [ c θ ( τ ) ] + log ( E τ ∼ q [ e − c θ ( τ ) q ( τ ) ] ) \mathcal{L}_{cost}(\theta)=\Bbb{E}_{\tau \sim p}[c_{\theta}(\tau)]+\log{(\Bbb{E}_{\tau \sim q}[\frac{e^{-c_{\theta}(\tau)}}{q(\tau)}])} Lcost(θ)=Eτ∼p[cθ(τ)]+log(Eτ∼q[q(τ)e−cθ(τ)])
通常最小化 q ( τ ) q(\tau) q(τ)与 1 Z e − c θ ( τ ) \frac{1}{Z}e^{-c_{\theta(\tau)}} Z1e−cθ(τ)的KL散度来更新 q ( τ ) q(\tau) q(τ),其等价于最小化learned cost同时最大化熵值(最小化交叉熵等价于最小化KL散度,花书P49)。
L s a m p l e r ( q ) = E τ ∼ q [ c θ ( τ ) ] + E τ ∼ q [ log q ( τ ) ] \mathcal{L}_{sampler}(q)=\Bbb{E}_{\tau \sim q}[c_{\theta}(\tau)]+\Bbb{E}_{\tau \sim q}[\log{q(\tau)}] Lsampler(q)=Eτ∼q[cθ(τ)]+Eτ∼q[logq(τ)]
为了防止 q ( τ ) q(\tau) q(τ)方差过大。我们设mixture distribution μ = 1 2 p + 1 2 q \mu=\frac{1}{2}p+\frac{1}{2}q μ=21p+21q其中 p ~ ( τ ) \widetilde p(\tau) p (τ)为demonstration distribution的粗略估算。
L c o s t ( θ ) = E τ ∼ p [ c θ ( τ ) ] + log ( E τ ∼ μ [ exp ( − c θ ( τ ) ) 1 2 p ~ + 1 2 q ] ) \mathcal{L}_{cost}(\theta)=\Bbb{E}_{\tau \sim p}[c_{\theta}(\tau)]+\log{(\Bbb{E}_{\tau \sim \mu}[\frac{\exp({-c_{\theta}(\tau)})}{\frac{1}{2}\widetilde p+\frac{1}{2}q}])} Lcost(θ)=Eτ∼p[cθ(τ)]+log(Eτ∼μ[21p +21qexp(−cθ(τ))])
Conclusion
Z = E τ ∼ μ [ e x p ( − c θ ( τ ) ) μ ~ ] Z=\Bbb{E}_{\tau \sim \mu}[\frac{exp(-c_{\theta}(\tau))}{\widetilde{\mu}}] Z=Eτ∼μ[μ exp(−cθ(τ))].
∂ θ L c o s t ( θ ) = ∂ θ L d i s c r i m i n a t o r ( D θ ) \partial_{\theta} \mathcal{L}_{cost}(\theta)= \partial_{\theta} \mathcal{L}_{discriminator}(D_\theta) ∂θLcost(θ)=∂θLdiscriminator(Dθ).
L g e n e r a t o r ( q ) = L c o s t ( θ ) + E τ ∼ q [ log q ( τ ) ] = log Z + L s a m p l e r ( q ) \mathcal{L}_{generator}(q)=\mathcal{L}_{cost}(\theta)+\Bbb{E}_{\tau \sim q}[\log q(\tau)]=\log Z + \mathcal{L}_{sampler}(q) Lgenerator(q)=Lcost(θ)+Eτ∼q[logq(τ)]=logZ+Lsampler(q).
- 最小化Discriminator loss的 Z Z Z 的值可以由重要性采样(花书p285)partition function得到;
- 对于此 Z Z Z值,Discriminator loss与IRL cost的偏微分相等,即二者梯度下降等价;
- Generator loss等于IRL cost减去 q ( τ ) q(\tau) q(τ)的熵值。
###Deficiency
- 只做了理论推导,没有做出相关实验。
- 假设对demonstration distribution的组略估算已经具有较好的效果(IRL 算法的常用假设)。
Generative Adversarial Imitation Learning
Motivation
One approach is to recover the expert’s cost function with inverse reinforcement learning, then extract a policy from that cost function with reinforcement learning. The approach is indirect and can be slow.
instantiation
通过逆强化学习得到专家路线的cost function在通过强化学习得到策略是一种间接的过程(一次逆强化学习中需要多步强化学习的循环)。本文通过GAN,从数据中直接提取策略,就好像是通过逆强化学习后的强化学习,是一种即时性的学习方法。
Summary
Definition
Expectation with respect to the trajectory
$\Bbb{E}_\pi[c(s,a)] \triangleq \Bbb{E}[\sum _{t=0}{\infty}\gammat c(s_t,a_t)] $,where $ s_0 \sim p_0, a_t \sim \pi(\cdot |s_t)$, and s t + 1 ∼ P ( ⋅ ∣ s t , a t ) s_{t+1} \sim P(\cdot | s_t,a_t) st+1∼P(⋅∣st,at) for t ≥ 0 t \ge 0 t≥0.
Maximum causal entropy IRL
max c ∈ C ( min π ∈ Π − H ( π ) + E π [ c ( s , a ) ] ) − E π E [ c ( s , a ) ] \max_{c \in \mathcal{C}}(\min_{\pi \in \Pi} -H(\pi) + \Bbb{E}_\pi[c(s,a)])-\Bbb{E}_{\pi_{E}}[c(s,a)] maxc∈C(minπ∈Π−H(π)+Eπ[c(s,a)])−EπE[c(s,a)] where H ( π ) ≜ E π [ − log π ( a ∣ s ) ] H(\pi) \triangleq \Bbb{E}_\pi [-\log \pi (a|s)] H(π)≜Eπ[−logπ(a∣s)].
(Maximum causal entropy IRL looks for a cost function c that assigns low cost to the expert policy and high cost to other policies.)
Minimize the expected cumulative cost
R L ( c ) = arg min π ∈ Π − H ( π ) + E π [ c ( s , a ) ] RL(c) = {\arg \min}_{\pi \in \Pi} -H(\pi) + \Bbb{E}_{\pi}[c(s,a)] RL(c)=argminπ∈Π−H(π)+Eπ[c(s,a)].
IRL primitive procedure
$IRL_{\psi}(\pi _ {E}) = \arg \max _ {c \in \Bbb{R}^{\mathcal{S} \times \mathcal{A} }} -\psi© + (\min_{\pi \in \Pi} -H(\pi) + \Bbb{E}{\pi}[c(s,a)]) - \Bbb{E}{\pi _ E}[c(s,a)] $.
(Where cost regularized by ψ \psi ψ, a (closed, proper) convex function.)
Occupancy measure
ρ π : S × A → R \rho_\pi : \mathcal{S} \times \mathcal{A} \to \Bbb{R} ρπ:S×A→R as ρ π ( s , a ) = π ( a ∣ s ) ∑ t = 0 ∞ γ t P ( s t = s ∣ π ) \rho _ \pi (s,a) = \pi(a|s)\sum_{t=0}^{\infty} \gamma^t P(s_t = s|\pi) ρπ(s,a)=π(a∣s)∑t=0∞γtP(st=s∣π).
(Interpreted as the distribution of state-action pairs with policy π \pi π)
Calculation
将Occupancy measure代入Expectation式中
E π [ c ( s , a ) ] = ∑ s , a ρ π ( s , a ) c ( s , a ) \Bbb{E}_\pi[c(s,a)]=\sum_{s,a}\rho_\pi(s,a)c(s,a) Eπ[c(s,a)]=∑s,aρπ(s,a)c(s,a)
(显然这里的 ρ π ( s , a ) \rho_\pi(s,a) ρπ(s,a)已经就是一种概率分布,依据概率分布算期望)
可以证明,policy π ρ ( a ∣ s ) \pi_\rho(a|s) πρ(a∣s)是occupancy measure ρ ( s , a ) \rho(s,a) ρ(s,a)唯一对应的policy,即。
π ρ ( a ∣ s ) ≜ ρ ( s , a ) / ∑ a ′ ρ ( s , a ′ ) \pi_\rho(a|s) \triangleq \rho(s,a)/ \sum_{a'}\rho(s,a') πρ(a∣s)≜ρ(s,a)/∑a′ρ(s,a′)
描述 R L ( c ~ ) RL(\widetilde c) RL(c ),即RL根据IRL学习到的policy
R L ∘ I R L ψ ( π E ) = arg min π ∈ Π − H ( π ) + ψ ∗ ( ρ π − ρ π E ) RL \circ IRL_\psi(\pi_E)=\arg \min_{\pi \in \Pi} -H(\pi) + \psi^*(\rho_\pi - \rho_{\pi_E}) RL∘IRLψ(πE)=argminπ∈Π−H(π)+ψ∗(ρπ−ρπE)
(convex conjugate f ∗ f^* f∗,凸共轭)
IRL的目标是寻找一个鞍点,而RL则去揭示其他鞍点。
我们考虑policy和occupancy measure两种熵
H ( π ) ≜ E π [ − log π ( a ∣ s ) ] = − ∑ s , a π ( a ∣ s ) log π ( a ∣ s ) H(\pi) \triangleq \Bbb{E}_{\pi}[-\log \pi (a|s)] = -\sum_{s,a} \pi(a|s) \log \pi (a|s) H(π)≜Eπ[−logπ(a∣s)]=−∑s,aπ(a∣s)logπ(a∣s)
H ˉ ( ρ ) ≜ E ρ [ − log π ρ ( a ∣ s ) ] = − ∑ s , a ρ ( s , a ) log ( ρ ( s , a ) / ∑ a ′ ρ ( s , a ′ ) ) \bar H(\rho) \triangleq \Bbb{E}_{\rho}[-\log \pi_\rho(a|s)] = - \sum_{s,a} \rho(s,a) \log(\rho(s,a)/ \sum_{a'}\rho(s,a')) Hˉ(ρ)≜Eρ[−logπρ(a∣s)]=−∑s,aρ(s,a)log(ρ(s,a)/∑a′ρ(s,a′))
可以证明
H ( π ) = H ˉ ( ρ π ) H(\pi) = \bar H(\rho_\pi) H(π)=Hˉ(ρπ)
H ˉ ( ρ ) = H ( π ρ ) \bar H(\rho) = H(\pi_\rho) Hˉ(ρ)=H(πρ)
设
L ( π , c ) = − H ( π ) + E π [ c ( s , a ) ] L(\pi,c)=-H(\pi)+\Bbb{E}_\pi[c(s,a)] L(π,c)=−H(π)+Eπ[c(s,a)]
L ˉ ( ρ , c ) = − H ˉ ( ρ ) + ∑ s , a c ( s , a ) ( ρ ( s , a ) − ρ π E ( s , a ) ) \bar L(\rho,c) = -\bar H(\rho) + \sum_{s,a}c(s,a)( \rho(s,a)-\rho_{\pi_E}(s,a)) Lˉ(ρ,c)=−Hˉ(ρ)+∑s,ac(s,a)(ρ(s,a)−ρπE(s,a))
可以证明
L ( π , c ) = L ˉ ( ρ π , c ) L(\pi,c)=\bar L(\rho_\pi,c) L(π,c)=Lˉ(ρπ,c)
L ˉ ( ρ , c ) = L ( π ρ , c ) \bar L(\rho,c)=L(\pi_\rho,c) Lˉ(ρ,c)=L(πρ,c)
上述过程,讲述了如此一个推论,policy和occupancy measure是双射的。
通过构建一个cost regularize
ψ G A ( c ) ≜ { E π E [ g ( c ( s , a ) ) ] , if c < 0 + ∞ , otherwise \psi_{GA}(c) \triangleq \begin{cases} \Bbb{E}_{\pi_E}[g(c(s,a))], & \text{if $c < 0$}\\ +\infty , & \text{otherwise} \end{cases} ψGA(c)≜{EπE[g(c(s,a))],+∞,if c<0otherwise
g ( x ) = { − x − log ( 1 − e x ) , if x < 0 + ∞ , otherwise g(x)=\begin{cases} -x-\log(1-e^x), & \text{if $x < 0$} \\ + \infty , & \text{otherwise} \end{cases} g(x)={−x−log(1−ex),+∞,if x<0otherwise
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-FdH6dU2W-1593782415193)(C:\Users\hasee007\AppData\Local\Temp\1525432340607.png)]
构建这个cost regularizer的动机是
ψ G A ∗ ( ρ π − ρ π E ) = max D ∈ ( 0 , 1 ) S × A E π [ log ( D ( s , a ) ) ] + E π E [ log ( 1 − D ( s , a ) ) ] \psi^*_{GA}(\rho_\pi - \rho_{\pi_E}) = \max_{D \in (0,1)^{\mathcal{S} \times \mathcal{A} }} \Bbb{E}_\pi [\log(D(s,a))] + \Bbb{E}_{\pi_E}[\log(1-D(s,a))] ψGA∗(ρπ−ρπE)=D∈(0,1)S×AmaxEπ[log(D(s,a))]+EπE[log(1−D(s,a))]
后者是Jensen-Shannon divergence表达的original GAN。至此,将Imitation Learning与GAN通过凸共轭变换从理论上联系起来。
Conclusion
寻找表达式(Loss function)
E π [ log ( D ( s , a ) ) ] + E π E [ log ( 1 − D ( s , a ) ) ] − λ H ( π ) \Bbb{E}_{\pi}[\log(D(s,a))]+\Bbb{E}_{\pi_E}[\log(1-D(s,a))]-\lambda H(\pi) Eπ[log(D(s,a))]+EπE[log(1−D(s,a))]−λH(π)
鞍点 ( π , D ) (\pi,D) (π,D):
- 使用Adam gradient在 D ω D_\omega Dω的参数 ω \omega ω使表达式上升;
- 使用TRPO在 π θ \pi_\theta πθ的参数 θ \theta θ使表达式下降。
关于这个表达式:
- 前半部分为Jensen-Shannon divergence(李宏毅PPT GAN P32),同时也是original GAN,通过构建cost regularizer ψ G A ∗ \psi^*_{GA} ψGA∗做凸共轭变换,并将 c ( s , a ) = log ( D ( s , a ) ) c(s,a)=\log(D(s,a)) c(s,a)=log(D(s,a))得到;
- 后半部分为policy的熵值。
Deficiency
- 在训练中,对于环境交互的样本效率不高(?),由于TRPO本身需要一些样本数量才能有用(?)。
It is not particularly sample efficient in terms of environment interaction during training.
- model free需要更多的环境交互。
SeqGAN
Motivation
GAN has limitations when the goal is for generating sequences of discrete tokens.
The discrete outputs from the generative model make it difficult to pass the gradient update from the discriminative model to the generative model.
The discriminative model can only assess a complete sequence.
It is nontrivial to balance its current score and the future.
- 生成模型的离散序列输出很难将辨别模型的梯度更新传递回离散模型(可由RL算法解决)。
- 辨别模型需要对完整的序列进行辨别,如果部分生成序列时,需要平衡当前得分与未来得分(此文用Monte Carlo搜索解决,我们可以用ADA-IRL算法来解决)。
Summary
- GAN is designed for generating real-valued, continuous data but has difficulties in directly generating sequences of discrete tokens. The “slight change” makes little sense.
- GAN can only give the score loss for an entire sequence when it has been generated.
GAN应用于序列生成时有两大缺点:
- GAN的设计目的是生成连续的实数,它利用辨别模型给出的判断对生成模型做微小的工作,然而对于离散模型而言,这种微小的工作不足以使之从有限的字典空间里找到对应的生成;
- GAN的辨别模型只能对完整的生成结果进行辨别。
- The generative model is treated as an agent of RL; the state is the generated tokens so far and the action is the next token to be generated;
- Employ a discriminator to evaluate the sequence and feedback the evaluation to guide the learning of the generative model;
- Regard the generative model as a stochastic parametrized policy.
- Employ Monte Carlo search to approximate the state-action value.
相应的解决方案:
- 将生成模型当作一个RL agent,将当前生成当作state,下一步生成当作action(RL基本思路);
- 建立一个Discriminator,来评估序列,并反馈给生成模型(Discriminator作为reward function);
- 将生成模型是做一个随机参数化的策略(应该是为了公式推导方便,这里即可使用概率分布来表达policy正如GAIL中一样);
- SeqGAN中使用蒙特卡罗搜索(可能耗费较多计算资源)解决缺点2;我们使用IRL的时候对于每一个state-action对都会有一个reward,再将这些reward做 γ \gamma γ discounted累加(Q Learning、Sarsa Lambda Learning的思想)即可。
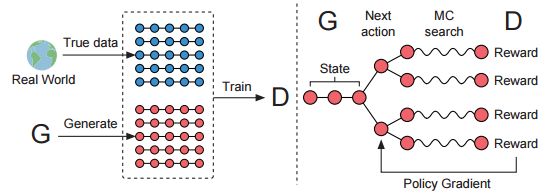
- D is trained over the real data and the generated data by G.
- G is trained by policy gradient where the final reward signal is provided by D and is passed back to the intermediate action value via Monte Carlo search.
Definition
Generator
G θ ( y t ∣ Y 1 : t − 1 ) G_\theta(y_t|Y_{1:t-1}) Gθ(yt∣Y1:t−1) 可以表达为Sequence: Y 1 : T = ( y 1 , . . . , y t , . . . , y T ) , y t ∈ Y Y_{1:T}=(y_1,...,y_t,...,y_T),y_t \in \mathcal{Y} Y1:T=(y1,...,yt,...,yT),yt∈Y,即In timestep t t t, state ( y 1 , . . . , y t − 1 ) (y_1,...,y_{t-1}) (y1,...,yt−1), action y t y_t yt.
Expected end reward
J ( θ ) = E [ R T ∣ s 0 , θ ] = ∑ y 1 ∈ Y G θ ( y 1 ∣ s 0 ) ⋅ Q D ϕ G θ ( s 0 , y 1 ) J(\theta) = \Bbb{E}[R_T|s_0, \theta] = \sum _ {y_1 \in \mathcal{Y}} G_\theta(y_1|s_0) \cdot Q_{D_\phi} ^ {G_\theta}(s_0,y_1) J(θ)=E[RT∣s0,θ]=y1∈Y∑Gθ(y1∣s0)⋅QDϕGθ(s0,y1)
N-time Monte Carlo search
{ Y 1 : T 1 , . . . , Y 1 : T N } = M C G β ( Y 1 : T ; N ) \{ Y_{1:T}^1,...,Y_{1:T}^N \} = MC^{G_\beta}(Y_{1:T};N) {Y1:T1,...,Y1:TN}=MCGβ(Y1:T;N)
Action-value function
$Q_{D_\phi}^{G_\theta}(s=Y_{1:T-1},a=y_T) = \begin{cases} \frac{1}{N} \sum_{n=1}^N D_\phi (Y_{1:T}^n), Y_{1:T}^n \in MC^{G_\beta}(Y_{1:t};N) , & \text{for t < T t < T t<T} \ D_\phi(Y_{1:t}), & \text{for t = T t=T t=T} \end{cases}$
Training
Update Discriminator
min ϕ − E Y ∼ p d a t a [ log D ϕ ( Y ) ] − E Y ∼ G θ [ log ( 1 − D ϕ ( Y ) ) ] \min _ \phi - \Bbb{E}_{Y \sim p_{data} } [\log D_\phi(Y)] - \Bbb{E}_{Y \sim G_\theta} [\log (1-D_\phi (Y))] ϕmin−EY∼pdata[logDϕ(Y)]−EY∼Gθ[log(1−Dϕ(Y))]
Update Generator
θ ← θ + α h ∇ θ J ( θ ) \theta \leftarrow \theta + \alpha_h \nabla_{\theta}J(\theta) θ←θ+αh∇θJ(θ)
Deficiency
- 使用Monte Carlo搜索求未来状态奖励的平均值;
- 使用一个CNN作为Discriminator,先将生成序列作为列向量concatenation成为一个矩阵,再做卷积和max-over-time pooling。
Diss
Behavioral cloning only tends to succeed with large amounts of data, due to compounding error caused by covariate shift.
Behavioral cloning 毕竟是一种supervised learning。
Many IRL algorithms are extremely expensive to run, requiring reinforcement learning in an inner loop.
IRL算法最大的问题在于其间接获得policy,即使用一个RL算法作为内循环。(讲道理,IRL都是这么干的)
Scheduled sampling(partially fed with its own synthetic data as prefix) is an inconsistent training strategy and fails to address the problem fundamentally.
SS算法会使训练结果一致性不好(?)。
- GAN is designed for generating real-valued, continuous data but has difficulties in directly generating sequences of discrete tokens. The “slight change” makes little sense.
- GAN can only give the score loss for an entire sequence when it has been generated.
GAN应用于序列生成时有两大缺点:
- GAN的设计目的是生成连续的实数,它利用辨别模型给出的判断对生成模型做微小的工作,然而对于离散模型而言,这种微小的工作不足以使之从有限的字典空间里找到对应的生成;
- GAN的辨别模型只能对完整的生成结果进行辨别。