Pytorch强化学习玩微信小游戏
文章目录
- 1.前言:
- 2.环境准备:
- 3.代码讲解
- A.首先是与调试环境交互相关的代码讲解:
- B.其次是神经网络代码的讲解
- C.最后就是模型训练的代码了
- 四.总结
1.前言:
学习了DQN有一段时间了,在我接触到的入门教程里,一般都是用它来玩集成好的Gym的游戏比如CartPole-v0,然后复杂一些的就是用它来玩Flappy bird,但是它们的环境都是集成好的,可以通过简单的调用api获得环境信息,奖励,在现实中少有这样准备的很好的api接口。于是,打算自己来设计一个简单的DQN神经网络,玩微信小游戏:
2.环境准备:
所使用的主要Python环境和库:
python = 3.6.6
numpy==1.15.4
Pillow==5.3.0
torch==1.0.0
torchvision==0.2.1
所使用的调试训练运行环境:
夜神模拟器 v6.2.6.3
微信版本 v7.0.0
小游戏名称 乒乓吧同学
执行操作方式 Adb调试工具的虚拟点击
如果想要运行此代码,需要将夜神模拟器设置为(运行时需要将模拟器窗口放于左上角,以方便截图):
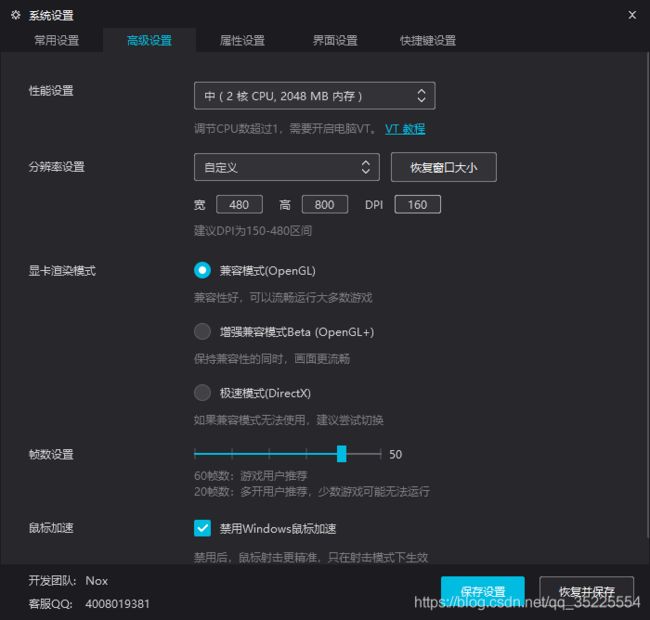

1.为什么要用模拟器,而不是用数据线连接接手机通过Adb工具截图?
因为手机不能改分辨率,只能用默认分辨率1920*1080,而且通过adb工具截图后上传到电脑大概需要0.5秒,在进行训练时,这个速度还会变大,而乒乓球这种快节奏游戏,很难忍受这种延迟,所以使用模拟器运行小游戏,然后可以直接通过Pillow库的相关函数截取特定区域获得图片。
2.为什么分辨率设置的这么低?
因为如果分辨率设置的很高,那么传入神经网络的图像参数就会很多,那么计算量就会增加,那么我的笔记本GPU可能就会跑不动。。。
3.为什么设置为双核2048MB内存?
因为对于我的笔记本而言,太高电脑反应变慢尤其是在训练的时候,太低玩微信小游戏都有延迟,所以多次测试后,选择这个配置。
3.代码讲解
A.首先是与调试环境交互相关的代码讲解:
class Handle:
def __init__(self):
self.debug = False
self.box = (3,43,483,823) # 完整截图区域
self.box_view = (0, 120, 460, 580) # 神经网络的视觉区域
self.box_reward = (144, 20, 334, 90)# 比分板区域
self.image = None # 未初始化的截图
self.image_view = None # 未初始化的神经网络视野
self.image_reward = None # 未初始化的分数板区域
self.state = []
self.score_previous = 0 # 之前的分数
def getimage(self):
self.image = ImageGrab.grab(self.box).convert('L')
self.image_view = self.image.crop(self.box_view)
self.image_reward = self.image.crop(self.box_reward)
getimage()方法用来从电脑屏幕的特定区域进行截图,此截图即为整个游戏界面,在截图之后将会吧图像转换为灰度图,以减少运算量,然后截取image_view作为神经网络的视野,截取image_reward比分扳区域用作之后的分数识别,两个截图如下图所示

def getstate(self):
self.state = []
for _ in range(4):
self.getimage()
self.state.append(self.image_view)
self.state = np.stack(self.state,axis=0)
def getscore(self):
image_one = self.image_reward.crop((0,0,72,70))
for _,_,filename in os.walk('./source/one'):
for file in filename:
name = os.path.join('./source/one',file)
image = Image.open(name)
if self.similar(image_one,image)>90:
return int(file.replace('.png',''))
print('No matching')
return None
@staticmethod
def similar(image_1,image_2):
lh, rh = image_1.histogram(), image_2.histogram()
ret = 100 * sum(1 - (0 if l == r else float(abs(l - r)) / max(l, r)) for l, r in zip(lh, rh)) / len(lh)
return ret
getstate() 连续截取四张图片,并且将四张图片拼接,乒乓球是在运动的,如果只截取一张图片作为神经网络的输入,神经网络就没法学习到通过乒乓球的运动轨迹来判断击球的行为了;getscore()方法通过模式匹配的方式获取当前比分扳的数值;similar()静态方法通过对比图片的直方图距离,来判断图片的相似度,注意,返回为整数,比如返回80就是相似度为80%,由于此识别方法有时会因为传入比分板图像处于翻页中,所以无法识别,所以会返回None,对应到下面的action()方法中,即跳过本次取值的保存,取值的训练,开始下一个回合。
def action(self,action):
score = self.getscore()
judge = self.judge()
if score is not None and judge!=0:
if action==0:
os.system('nox_adb.exe shell input tap 130 640')
print('选左边')
else:
os.system('nox_adb.exe shell input tap 360 640') # 选右边
print('选右边')
reward = float(judge)*0.6 + int(score)*0.4
print(f'score:{score},judge:{judge},reward:{reward}')
self.getstate() # 下一个状态
return self.state,reward,0
else:
return None,None,1
def judge(self):
if self.similar(self.image.crop((150, 570, 330, 630)), Image.open('./source/restart.png')) > 90:
os.system('nox_adb.exe shell input tap 240 600') # 重新开始
print('重新开始')
return 0 # 无操作
if self.similar(self.image.crop((150, 620, 330, 670)), Image.open('./source/loss_continue.png')) > 90:
os.system('nox_adb.exe shell input tap 80 623') # 丢分点击
print('失分惩罚')
return -2 # 惩罚
if self.similar(self.image.crop((150, 620, 330, 670)), Image.open('./source/get_continue.png')) > 90:
os.system('nox_adb.exe shell input tap 240 400') # 得分点击
print('得分奖励')
return 2 # 奖励
# if self.similar(self.image.crop((110,620,390,665)), Image.open('./source/wait.png')) > 90:
# os.system('nox_adb.exe shell input tap 240 400') # 得分点击,对战模式
# print('得分奖励')
# return 2 # 奖励
if self.similar(self.image.crop((170,590,360,620)), Image.open('./source/nextoppent.png'))>90:
os.system('nox_adb.exe shell input tap 250 610') # 点击挑战下一个对手
print('挑战下一个对手')
return 4 # 奖励
if self.similar(self.image.crop((170,675,310,705)), Image.open('./source/skip.png'))>90:
os.system('nox_adb.exe shell input tap 230 700') # 跳过看视频复活
print('跳过看视频复活')
time.sleep(0.5)
return 0 # 无操作
if self.similar(self.image.crop((170,640,310,670)), Image.open('./source/video_skip.png'))>90:
os.system('nox_adb.exe shell input tap 235 660') # 跳过看视频奖励
print('跳过看视频奖励')
return 0 # 无操作
if self.similar(self.image.crop((420,250,470,300)), Image.open('./source/x.png'))>90:
os.system('nox_adb.exe shell input tap 445 285') # 关闭向朋友推荐
print('关闭向朋友推荐')
return 0 # 无操作
if self.similar(self.image.crop((34,560,90,615)), Image.open('./source/rechallenge.png'))>90:
os.system('nox_adb.exe shell input tap 60 600') # 重新挑战
print('重新挑战')
return 0 # 无操作
return 0.1
action(action)方法用来执行相应的行为,这里的行为分为两个,一个是左击球,一个是右击球;judge()方法用来判断当前的游戏状态,一样的也是使用模式匹配方式,由于微信小游戏有许多的推广状态,所以需要很多的判断,比如 看视频复活 、朋友推荐复活 、看视频奖励翻倍等,如果是能继续游戏的操作,那么就会返回相应的奖励惩罚值,如果是不能继续游戏的操作,则返回0,对应到action()方法中,即跳过本次取值的保存,取值的训练,开始下一个回合。
B.其次是神经网络代码的讲解
Actions = 2 # 游戏的两种行为
class Brain(nn.Module):
def __init__(self):
super(Brain, self).__init__()
self.replay_memory = deque()
self.actions = Actions
self.mem_size = 300
self.conv1 = nn.Conv2d(4,32,kernel_size=4,stride=2,padding=2)
self.relu1 = nn.ReLU(inplace=True)
self.conv2 = nn.Conv2d(32,64,kernel_size=4,stride=2,padding=1)
self.relu2 = nn.ReLU(inplace=True)
self.conv3 = nn.Conv2d(64, 64, kernel_size=4, stride=2, padding=1)
self.relu3 = nn.ReLU(inplace=True)
self.net = nn.Sequential(self.conv1, self.relu1, self.conv2, self.relu2, self.conv3, self.relu3)
self.fc1 = nn.Linear(64*57*57,256)
self.relu4 = nn.ReLU(inplace=True)
self.fc2 = nn.Linear(256,self.actions)
def forward(self, input):
out = self.net(input)
out = out.view(out.size()[0],-1)
out = self.fc1(out)
out = self.relu4(out)
out = self.fc2(out)
return out
神经网络方面一目了然,由三层卷积神经网络加两层全连接层构成,由于乒乓球的运动轨迹是一跳细线,所以选用了较小的卷积核对输入图像进行处理,最后的输出为左和右的数值,格式如下[[0.45,-3.8]]
C.最后就是模型训练的代码了
# Hyper Parameters
Batch_size = 64
LR = 0.001 # learning rate
Epsilon = 0.9 # greedy policy
Gamma = 0.9 # reward discount
Target_replace_iter = 32 # target net update frequency
Memory_capacity = 64 # total memory
States = 4 # state Action Reward state_next
Actions = 2
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
首先是超参数的定义,学习速率为0.001,贪婪策略为0.9(即0.1的可能是随机反应,其他的都是神经网络的输出),奖励衰减Gamma值为0.9 ,目标网络的更新频率为32次学习/更新一次,总的记忆为64。
为什么记忆数量那么少,更新频率这么快?
因为!是微信小游戏啊!!!每次死亡后,都会有一堆的需要识别点击的东西,才能开始下一次训练,流程太慢了,当然,这些都是可以修改的,太小只是能很快的看到学习的效果,如果有耐心也可以设置的大一些
class DeepQN(object):
def __init__(self):
self.device = device
self.eval_net = Brain().to(self.device)
self.target_net = Brain().to(self.device)
self.replay_memory = deque()
self.memory_capacity = Memory_capacity
self.learn_step_counter = 0
self.memory_counter = 0
self.batch_size = 32
self.optimizer = torch.optim.Adam(self.eval_net.parameters(),lr=LR)
self.loss_func = nn.MSELoss()
def choose_action(self,views):
views = torch.unsqueeze(torch.FloatTensor(views),0).to(device)
if np.random.uniform()<Epsilon: # greedy
actions_value = self.eval_net.forward(views)
action = torch.max(actions_value,1)[1].cpu().data.numpy() # 改动点
action = action[0]
else:
action = np.random.randint(0,Actions)
return action
def store_transition(self, state, Action, Reward, state_next):
next_state = state_next
self.replay_memory.append((state, Action, Reward, next_state, terminal))
if len(self.replay_memory) > self.memory_capacity:
self.replay_memory.popleft()
self.memory_counter +=1
def learn(self):
# target parameter update
if self.learn_step_counter % Target_replace_iter == 0:
self.target_net.load_state_dict(self.eval_net.state_dict())
self.learn_step_counter +=1
# sample batch transitions
minibatch = random.sample(self.replay_memory, self.batch_size)
b_state = torch.FloatTensor(np.array([data[0] for data in minibatch])).to(device)
b_action = torch.LongTensor(np.array([[data[1]] for data in minibatch])).to(device)
b_reword = torch.FloatTensor(np.array([data[2] for data in minibatch])).to(device)
b_state_next = torch.FloatTensor(np.array([data[3] for data in minibatch])).to(device)
q_eval = self.eval_net(b_state).gather(1,b_action)
q_next = self.target_net(b_state_next).detach()
q_target = b_reword + Gamma * q_next.max(1)[0].view(self.batch_size,1)
loss = self.loss_func(q_eval,q_target)
self.optimizer.zero_grad()
loss.backward()
self.optimizer.step()
def save(self):
torch.save(self.target_net, './model/model_gpu.check')
def load(self):
self.eval_net = torch.load('./model/model_gpu.check')
self.target_net = torch.load('./model/model_gpu.check')
print('load model succes...')
上面的代码就是标准的DQN形式,两个神经网络同时运作,eval_net来训练学习,target_net用来评估下一次的行为,用双向队列deque来保存记忆,新记忆从左边存入,如果队列满了就从左边弹出旧记忆,save()、load()方法用来保存、载入神经网络
dqn = DeepQN()
Op = Handle()
if os.path.exists('./model/model_gpu.check'):
dqn.load()
total_step = 0
for i_episode in range(1000):
Op.getstate()
while True:
action = dqn.choose_action(Op.state)
# 执行行为
state_next,reward,terminal = Op.action(action)
if terminal:
break
dqn.store_transition(Op.state,action,reward,state_next)
if dqn.memory_counter>Memory_capacity:
dqn.learn()
print(f'Ep:{i_episode} | Ep_r:{round(reward,3)} | total_step:{total_step}')
if i_episode % 50 == 0:
dqn.save()
total_step+=1
Op.state = state_next
最后就是训练了,先实例化两个对象,一个用来学习,另一个用来与环境交互,然后获取初始状态,将初始转台放入有贪婪策略的神经网络中,返回相应的action,再根据返回的action与环境进行交互。。。
看完这篇后,可能感觉会少了点什么东西,没错,木有评估相关的代码,因为训练的过程太慢了… ,慢到怀疑人生,而且有些在打完一局后的 点击操作还不能太快,不然就会点出一些其他的窗口(见
action中的time.sleep()),而且因为是使用匹配的方式,识别比分板也特别的艰难,有些时候会识别不到,奖励函数设置的也不是很合理,所以没有训练好的模型,之后的时间需要好好的优化。。。优化后的代码会继续更新。
四.总结
和那些集成好的环境对比,想设计这种自用型神经网络很大的一个问题就是与环境的交互上,各类操作的延迟简直不要太高,而且微信小程序本来就是属于网页,有时还会受到网络延迟,加载失败的影响,让学习过程难上加难。有兴趣的同学阔以去下载代码,配好环境自己优化一下代码,反正模板就在这里,其他的微信小游戏也是一样的通吃,只是改下输入和输出而已,如果需要的话,可以出一期如何取相应的点击 点位置的教程(其实百度上有很多了,而且夜神模拟器可以支持直接用adb调试), 因为我也是新手,可能上面会有不对的地方,代码中可能会有bug…
完整代码: play_wechatgame_with_DQN