百度飞桨(4)—— 车牌识别
前言
本节学习车牌识别,小改lenet-5网络。
视屏教程:百度飞浆
存在的问题
本地用pycharm读文件顺序和AI studio读取顺序不同… …导致加载本地匹配码总是错位,无奈只能静态的存匹配关系了。但是这样适配到别的机器上就要修改test_list.list和train_list.list文件里面的路径了,可以使用pycharm的replace_all功能替换。
网络搭建
参考上一节的Lenet-5网络分析:百度飞桨(3)—— 手势识别
本节使用的数据是20 × 20大小的单通道图片,所以输入层相对于上一节代码需要做变动。
网络代码:
#定义网络
class MyLeNet(fluid.dygraph.Layer):
def __init__(self):
super(MyLeNet, self).__init__()
self.c1 = Conv2D(1, 6, 5, 1)
self.s2 = Pool2D(pool_size=2, pool_type='max', pool_stride=1)
self.c3 = Conv2D(6, 16, 5, 1)
self.s4 = Pool2D(pool_size=2, pool_type='max', pool_stride=1)
self.c5 = Conv2D(16, 120, 10, 1)
self.f6 = Linear(120, 84, act='relu')
self.f7 = Linear(84, 65, act='softmax')
def forward(self, input):
print("input shape : " + str(input.shape))
x = self.c1(input)
print("C1 : " + str(x.shape))
x = self.s2(x)
print("S2 : " + str(x.shape))
x = self.c3(x)
print("C3 : " + str(x.shape))
x = self.s4(x)
print("S4 : " + str(x.shape))
x = self.c5(x)
print("C5 : " + str(x.shape))
x = fluid.layers.reshape(x, shape=[-1, 120])
print(x.shape)
x = self.f6(x)
y = self.f7(x)
return y
这里打印查看下每一层的形状:
input shape : [128, 1, 20, 20]
C1 : [128, 6, 16, 16]
S2 : [128, 6, 15, 15]
C3 : [128, 16, 11, 11]
S4 : [128, 16, 10, 10]
C5 : [128, 120, 1, 1]
[128, 120]
对于C5层图片尺寸必须是1 × 1的,
20200528修改:
这里我之前理解错了,不是必须1 × 1的,只要满足卷积层和全连接层相连的那个全连接层的输入是卷积层最后一层算出来的通道数乘图像的size即可。那么这里没有报错是因为128 = 128 × 1 × 1,那么这里为了和renet相同可以修改这几句代码为
self.c5 = Conv2D(16, 120, 5, 1)
self.f6 = Linear(120 * 6 * 6, 84, act=‘relu’)也是可以的。
不然形状变换成一维的就会报错,这句话self.c5 = Conv2D(16, 120, 10, 1)中的10就是:
10 - x + 1 = 1
求解出来的x的值,上面式子的参数10就是S4层的形状10 × 10中的10,等号右边的1是输出尺寸为1 × 1的1,左边的1是一个固定值,所以就知道如何配置C5层的参数了。如果C5层输出尺寸不为1就会报错如下:
----------------------
Error Message Summary:
----------------------
InvalidArgumentError: Input(X) and Input(Label) shall have the same shape except the last dimension. But received: the shape of Input(X) is [512, 65], the shape of Input(Label) is [128, 1].
[Hint: Expected framework::slice_ddim(x_dims, 0, rank - 1) == framework::slice_ddim(label_dims, 0, rank - 1), but received framework::slice_ddim(x_dims, 0, rank - 1):512 != framework::slice_ddim(label_dims, 0, rank - 1):128.] at (/paddle/paddle/fluid/operators/cross_entropy_op.cc:49)
训练结果

识别结果
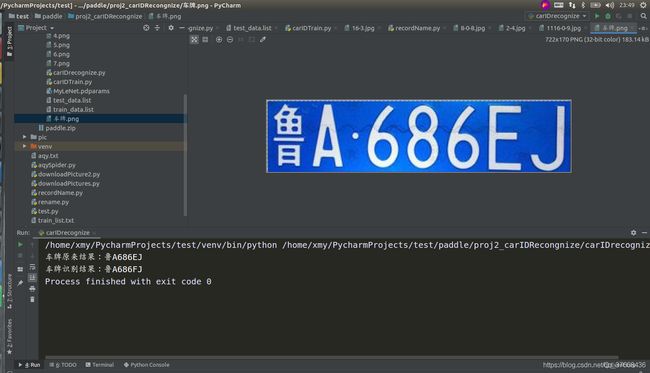
完整代码
训练文件的代码carIDTrain.py:
#导入需要的包
# -*- coding: utf-8 -*-
import numpy as np
import paddle as paddle
import paddle.fluid as fluid
from PIL import Image
import cv2
import matplotlib.pyplot as plt
import os
from multiprocessing import cpu_count
from paddle.fluid.dygraph import Pool2D,Conv2D
from paddle.fluid.dygraph import Linear
def makePictureList(data_path):
# 生成车牌字符图像列表
character_folders = os.listdir(data_path)
label = 0
LABEL_temp = {}
if (os.path.exists('./train_data.list')):
os.remove('./train_data.list')
if (os.path.exists('./test_data.list')):
os.remove('./test_data.list')
for character_folder in character_folders:
with open('./train_data.list', 'a') as f_train:
with open('./test_data.list', 'a') as f_test:
if character_folder == '.DS_Store' or character_folder == '.ipynb_checkpoints' or character_folder == 'data23617':
continue
print(character_folder + " " + str(label))
LABEL_temp[str(label)] = character_folder # 存储一下标签的对应关系
character_imgs = os.listdir(os.path.join(data_path, character_folder))
for i in range(len(character_imgs)):
if i % 10 == 0:
f_test.write(
os.path.join(os.path.join(data_path, character_folder), character_imgs[i]) + "\t" + str(
label) + '\n')
else:
f_train.write(
os.path.join(os.path.join(data_path, character_folder), character_imgs[i]) + "\t" + str(
label) + '\n')
label = label + 1
print('图像列表已生成')
return LABEL_temp
# 用上一步生成的图像列表定义车牌字符训练集和测试集的reader
def data_mapper(sample):
img, label = sample
path = img
img = paddle.dataset.image.load_image(file=img, is_color=False)
try:
img = img.flatten().astype('float32') / 255.0
except:
print(path)
return img, label
def data_reader(data_list_path):
def reader():
with open(data_list_path, 'r') as f:
lines = f.readlines()
for line in lines:
img, label = line.split('\t')
yield img, int(label)
return paddle.reader.xmap_readers(data_mapper, reader, cpu_count(), 1024)
#定义网络
class MyLeNet(fluid.dygraph.Layer):
def __init__(self):
super(MyLeNet, self).__init__()
self.c1 = Conv2D(1, 6, 5, 1)
self.s2 = Pool2D(pool_size=2, pool_type='max', pool_stride=1)
self.c3 = Conv2D(6, 16, 5, 1)
self.s4 = Pool2D(pool_size=2, pool_type='max', pool_stride=1)
self.c5 = Conv2D(16, 120, 10, 1)
self.f6 = Linear(120, 84, act='relu')
self.f7 = Linear(84, 65, act='softmax')
def forward(self, input):
print("input shape : " + str(input.shape))
x = self.c1(input)
print("C1 : " + str(x.shape))
x = self.s2(x)
print("S2 : " + str(x.shape))
x = self.c3(x)
print("C3 : " + str(x.shape))
x = self.s4(x)
print("S4 : " + str(x.shape))
x = self.c5(x)
print("C5 : " + str(x.shape))
x = fluid.layers.reshape(x, shape=[-1, 120])
print(x.shape)
x = self.f6(x)
y = self.f7(x)
return y
def load_image(path):
img = paddle.dataset.image.load_image(file=path, is_color=False)
img = img.astype('float32')
img = img[np.newaxis,] / 255.0
return img
if __name__ == '__main__':
#data_path = "/home/xmy/PycharmProjects/test/paddle/data/characterData"
#LABEL_temp = makePictureList(data_path)
# 用于训练的数据提供器
train_reader = paddle.batch(reader=paddle.reader.shuffle(reader=data_reader('./train_data.list'), buf_size=512),
batch_size=128)
# 用于测试的数据提供器
test_reader = paddle.batch(reader=data_reader('./test_data.list'), batch_size=128)
with fluid.dygraph.guard():
model = MyLeNet() # 模型实例化
model.train() # 训练模式
opt = fluid.optimizer.SGDOptimizer(learning_rate=0.01,
parameter_list=model.parameters()) # 优化器选用SGD随机梯度下降,学习率为0.001.
epochs_num = 40 # 迭代次数为20(可在此处进行调参)
for pass_num in range(epochs_num):
for batch_id, data in enumerate(train_reader()):
images = np.array([x[0].reshape(1, 20, 20) for x in data], np.float32)
labels = np.array([x[1] for x in data]).astype('int64')
labels = labels[:, np.newaxis]
image = fluid.dygraph.to_variable(images)
label = fluid.dygraph.to_variable(labels)
predict = model(image) # 使用训练好的模型进行预测
loss = fluid.layers.cross_entropy(predict, label)
avg_loss = fluid.layers.mean(loss) # 获取avg_loss值
acc = fluid.layers.accuracy(predict, label) # 计算精度
if batch_id != 0 and batch_id % 50 == 0:
print("train_pass:{},batch_id:{},train_loss:{},train_acc:{}".format(pass_num, batch_id,
avg_loss.numpy(), acc.numpy()))
avg_loss.backward()
opt.minimize(avg_loss)
model.clear_gradients()
fluid.save_dygraph(model.state_dict(), 'MyLeNet') # 保存模型
# 模型校验
with fluid.dygraph.guard():
accs = []
model = MyLeNet() # 模型实例化
model_dict, _ = fluid.load_dygraph('MyLeNet')
model.load_dict(model_dict) # 加载模型参数
model.eval() # 评估模式
for batch_id, data in enumerate(test_reader()): # 测试集
images = np.array([x[0].reshape(1, 20, 20) for x in data], np.float32)
labels = np.array([x[1] for x in data]).astype('int64')
labels = labels[:, np.newaxis]
image = fluid.dygraph.to_variable(images)
label = fluid.dygraph.to_variable(labels)
predict = model(image) # 预测
acc = fluid.layers.accuracy(predict, label)
accs.append(acc.numpy()[0])
avg_acc = np.mean(accs)
print(avg_acc)
识别的代码carIDRecognize.py:
#导入需要的包
import numpy as np
import paddle as paddle
import paddle.fluid as fluid
from PIL import Image
import cv2
import matplotlib.pyplot as plt
import os
from carIDTrain import MyLeNet
from multiprocessing import cpu_count
from paddle.fluid.dygraph import Pool2D,Conv2D
from paddle.fluid.dygraph import Linear
def load_image(path):
img = paddle.dataset.image.load_image(file=path, is_color=False)
img = img.astype('float32')
img = img[np.newaxis,] / 255.0
return img
# 对车牌图片进行处理,分割出车牌中的每一个字符并保存
license_plate = cv2.imread('车牌.png')
gray_plate = cv2.cvtColor(license_plate, cv2.COLOR_RGB2GRAY)
ret, binary_plate = cv2.threshold(gray_plate, 175, 255, cv2.THRESH_BINARY)
result = []
for col in range(binary_plate.shape[1]):
result.append(0)
for row in range(binary_plate.shape[0]):
result[col] = result[col] + binary_plate[row][col] / 255
character_dict = {}
num = 0
i = 0
while i < len(result):
if result[i] == 0:
i += 1
else:
index = i + 1
while result[index] != 0:
index += 1
character_dict[num] = [i, index - 1]
num += 1
i = index
for i in range(8):
if i == 2:
continue
padding = (170 - (character_dict[i][1] - character_dict[i][0])) / 2
ndarray = np.pad(binary_plate[:, character_dict[i][0]:character_dict[i][1]], ((0, 0), (int(padding), int(padding))),
'constant', constant_values=(0, 0))
ndarray = cv2.resize(ndarray, (20, 20))
cv2.imwrite('./' + str(i) + '.png', ndarray)
#将标签进行转换
LABEL ={'0': 'A', '1': '新', '2': '陕', '3': 'B', '4': '津', '5': 'W', '6': 'E', '7': 'P', '8': '8', '9': 'D', '10': 'M', '11': '贵', '12': '1', '13': 'Z', '14': '吉', '15': 'F', '16': '辽', '17': 'H', '18': '蒙', '19': '豫', '20': '皖', '21': 'L', '22': '冀', '23': '琼', '24': '黑', '25': 'X', '26': '浙', '27': '5', '28': '6', '29': 'R', '30': '沪', '31': '鄂', '32': '藏', '33': 'C', '34': 'T', '35': '赣', '36': 'J', '37': 'Q', '38': 'G', '39': '川', '40': 'U', '41': '鲁', '42': '2', '43': 'K', '44': '渝', '45': '苏', '46': '7', '47': '云', '48': '晋', '49': '宁', '50': 'S', '51': '闽', '52': '9', '53': 'N', '54': '0', '55': '粤', '56': '桂', '57': '4', '58': 'V', '59': 'Y', '60': '青', '61': '京', '62': '湘', '63': '甘', '64': '3'}
#构建预测动态图过程
with fluid.dygraph.guard():
model=MyLeNet()#模型实例化
model_dict,_=fluid.load_dygraph('/home/xmy/PycharmProjects/test/paddle/proj2_carIDRecongnize/MyLeNet')
model.load_dict(model_dict)#加载模型参数
model.eval()#评估模式
lab=[]
for i in range(8):
if i==2:
continue
infer_imgs = []
infer_imgs.append(load_image('./' + str(i) + '.png'))
infer_imgs = np.array(infer_imgs)
infer_imgs = fluid.dygraph.to_variable(infer_imgs)
result=model(infer_imgs)
lab.append(np.argmax(result.numpy()))
cv2.imshow("carID",cv2.imread("车牌.png"))
print("车牌原来结果:鲁A686EJ")
print('车牌识别结果:',end='')
for i in range(len(lab)):
print(LABEL[str(lab[i])],end='')
工程下载
工程下载地址