《深入浅出多模态》:智能文档处理多模态大模型总结

✨专栏介绍: 本作者推出全新系列《深入浅出多模态》专栏,具体章节如导图所示(导图后续更新),将分别从各个多模态模型的概念、经典模型、创新点、论文综述、发展方向、数据集等各种角度展开详细介绍,欢迎大家关注。
作者主页: GoAI | 公众号: GoAI的学习小屋 | 交流群: 704932595 |个人简介 : 掘金签约作者、百度飞桨PPDE、领航团团长、开源特训营导师、CSDN、阿里云社区人工智能领域博客专家、新星计划计算机视觉方向导师等,专注大数据与AI 知识分享。
文章目录
《深入浅出多模态》(一):多模态模型论文最全总结
《深入浅出多模态》(二):多模态任务应用与背景
导读: 本文为《深入浅出多模态》系列,《OCR文档任务多模态预训练模型总结》主要介绍OCR文档任务的多模态模型的经典论文及内容结构展开介绍。
大模型时代的现实场景或者企业私域数据中,大多数数据都以文档的形式存在,如何更好的解析获取文档数据显得尤为重要。文档智能也从以前的目标检测(版面分析)阶段转向多模态预训练阶段,本文将介绍目前一些前沿的多模态预训练模型及相关数据集。本专栏适合从事多模态小白及爱好者学习,欢迎大家关注,如有侵权请联系删除!
《深入浅出多模态》:OCR文档后处理多模态任务总结

OCR大一统模型相关研究
针对OCR大一统模型相关的研究范式概述,以及近期OCR大一统模型相关的研究成果
将文档图像识别分析的各种任务定义为序列预测的形式文本,段落,版面分析,表格,公式等等,通过不同的prompt引导模型完成不同的OCR任务,支持篇章级的文档图像识别分析,输出Markdown/HTML/Text等标准格式将文档理解相关的工作交给LLM去做
对于多模态大模型在文档领域应用的范式与应用洞见,该范式包含以下几个关键步骤:
-
文档图像输入:技术首先处理文档的图像形式,包括扫描的纸质文件、拍照的照片,或电子文档的页面图像。
-
文档识别与版面分析:在此阶段,系统会识别文档中的文字、图片、表格等元素,并分析版面布局。这包括标题、段落、页眉和页脚,有助于理解文档的总体结构和内容组织。
-
文档切分和召回:技术将文档切分,分离不同部分的内容以便进一步处理。此外,实施召回策略来检索和提取特定元素,如标题、关键字和段落内容。
-
大语言模型问答应用:最后阶段,大语言模型问答用于文档中信息提取的问答任务。通过训练模型理解文档内容,实现智能理解和交互式查询,以回答用户提出的问题。
多模态预训练模型导图
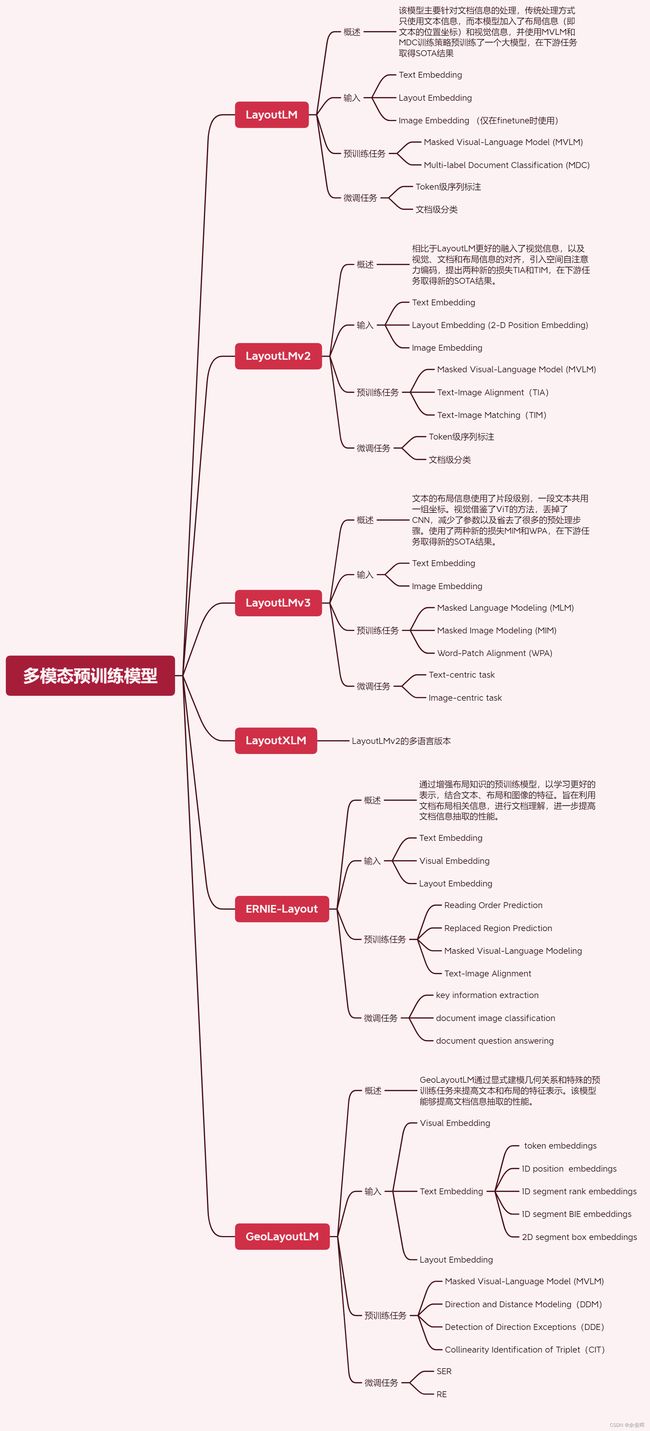
LayoutLM
概述:该模型主要针对文档信息的处理,传统的类Bert模型仅使用文本信息,该模型引入了布局信息(即文本的位置坐标)和视觉信息,并使用MVLM和MDC训练策略进行预训练。
paper:LayoutLM: Pre-training of Text and Layout for Document Image Understanding
link:https://arxiv.org/abs/1912.13318
code:https://github.com/microsoft/unilm/tree/master/layoutlm
模型结构
- 文本嵌入:Bert backbone
- 布局嵌入:(1)利用Bert的backbone,增加边界框嵌入(x 0 x_0x0,y 0 y_0y0,x 1 x_1x1,y 1 y_1y1),其中(x 0 x0x0 , y 0 y_0y0)对应于边界框中左上角的位置,(x 1 x_1x1 , y 1 y_1y1)表示右下角的位置;(2)[CLS]位置则用整个文本块的边界框坐标;
- 视觉嵌入(仅在finetune阶段使用):(1)用FasterRCNN提取扫描件的视觉特征,将其与bert的输出融合;(2)利用OCR获取文本和对应布局信息;(3)[CLS]使用Faster R-CNN模型来生成嵌入,使用整个扫描的文档图像作为感兴趣区域(ROI);
预训练任务
- Masked Visual-Language Model (MVLM):使用bert的MLM任务MASK掉token,但保留对应的布局信息,借助布局信息和上下文信息预测对应token。
- Multi-label Document Classification (MDC):一个可选策略,旨在对文档进行分类,模型可以对来自不同领域的知识进行聚类,并生成更好的文档级表示
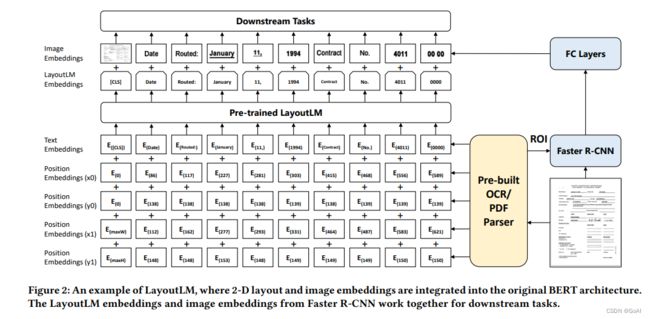
LayoutLMv2
概述: 相比于LayoutLM更好的融入了视觉信息,以及视觉、文档和布局信息的对齐,引入空间自注意力编码,提出两种新的损失函数TIA和TIM进行预训练。LayoutLMv1仅在fine-tuning阶段用到视觉特征,pretraining阶段没有视觉特征与文本特征的跨模态交互。Pretraining阶段,提出multi-modal transformer,融合text、layout、visual information;在LayoutLMv1中MVLM基础上,新增text-image alignment与text-image matching两个预训练任务。
paper:LayoutLMv2: Multi-modal Pre-training for Visually-rich Document Understanding
link:https://arxiv.org/abs/2012.14740
code:https://github.com/microsoft/unilm/tree/master/layoutlmv2
模型结构
- 文本嵌入:Bert backbone
- 视觉嵌入 :
V i = P r o j ( V i s T o k E m b ( I ) i ) + P o s E m b 1 D ( i ) + S e g E m b ( [ C ] ) V_i=Proj(VisTokEmb(I)_i)+PosEmb1D(i)+SegEmb([C])V**i=Proj(VisTokEmb(I)i)+PosE**mb1D(i)+SegEmb([C])- 视觉特征提取backbone:ResNeXt-FPN
- 将图片统一缩放到224x224大小,经过backbone后平均池化成固定大小WxH(7x7),再展平得到长度为49的序列,再经过一个线性层映射到与文本嵌入相同的维度;
- 额外增加一维位置嵌入,与文本一维位置嵌入共享参数
- 布局嵌入:
- 除边界框嵌入(x 0 x_0x0,y 0 y_0y0,x 1 x_1x1,y 1 y_1y1)外,还增加宽w和高h嵌入;
- 布局嵌入与LayoutLM中四个坐标相加不同,这里拼接六个位置嵌入为一个输入,每个位置嵌入维度为隐层维度/6;
I i = C o n c a t ( P o s E m b 2 D x ( x m i n , x m a x , w i d t h ) , P o s E m b 2 D y ( y m i n , y m a x , h e i g h t ) ) I_i=Concat(PosEmb2D_x(x_{min},x_{max},width),PosEmb2D_y(y_{min},y_{max},height))I**i=Conca**t(PosE**mb2D**x(x**min,xmax,width),PosE**mb2D**y(y**min,ymax,heigh**t)) - 图像经backbone得到长度为49的序列,将其视为把原图切分成49个块,视觉部分的布局嵌入使用每个块的布局信息;
- 对于[CLS], [SEP]和[PAD],布局信息使用(0,0,0,0,0,0)表示;
预训练任务
- Masked Visual-Language Model (MVLM):与LayoutLM相同,为了避免视觉信息泄露,在送入视觉backbone之前,将对应掩码token的视觉区域掩盖掉。
- Text-Image Alignment (TIA):作用:帮助模型学习图像和边界框坐标之间的空间位置对应关系。(1)随机选择一些文本行,覆盖对应图像区域;(2)在编码器最后一层设置一个分类层,预测是否被覆盖,分类标签为[Convered]、[Not Convered],计算二元交叉熵损失;当同时被mask和cover时,不计算TIA损失,为了防止学习到mask到cover的映射。
- Text-Image Matching (TIM):将[CLS]处的输出表示输入分类器,以预测图像和文本是否来自同一文档页面。帮助模型学习文档图像和文本内容之间的对应关系。
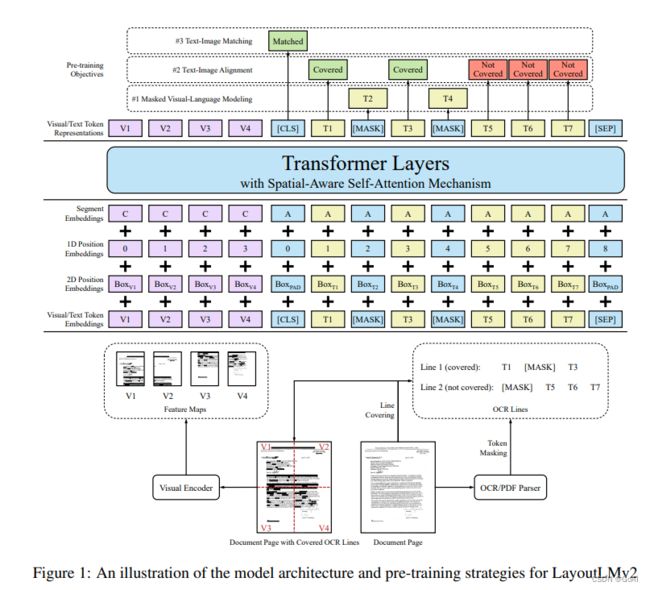
LayoutLMv3
概述: 文本的布局信息使用了片段级别,一段文本共用一组坐标。视觉借鉴了ViT的方法替换CNN,减少了参数以及省去了很多的预处理步骤。使用了两种新的损失MIM和WPA进行预训练。
paper:LayoutLMv3: Pre-training for Document AI with Unified Text and Image Masking
link:https://arxiv.org/abs/2204.08387
code:https://github.com/microsoft/unilm/tree/master/layoutlmv3
模型结构

LayoutLMv3并没有充分利用有用的几何关系信息:
(a) LayoutLMv3 倾向于链接两个实体,它们更依赖于它们的语义,而不是几何布局;
(b) LayoutLMv3 成功地预测了上半部分的链接,但忽略了下面的链接,尽管这两个链接在几何布局上是相似的。
这两个例子说明了几何信息在关系提取(RE)中的重要性。
LayoutLMv3详细结构图:
backbone
- 视觉嵌入:与layoutLMv2相同,与之前的单词级别的边界框不同,此处使用了片段级别的嵌入,即:块边界框。
- 布局嵌入:不再使用CNN网络,采用类似ViT思想的backbone,将图片切分成一个个的patches。
预训练任务
- Masked Language Modeling (MLM):使用span掩码策略,mask掉30%的文本token,maks的span长度服从泊松分布(λ=3)
- Masked Image Modeling (MIM):
- 用分块掩码策略随机掩盖掉40%的图像token,用交叉熵损失驱动其重建被掩盖的图像区域;
- 图像token的标签来自一个图像tokenizer,通过图像vocab将密集图像的像素转化成离散token,相比于低级高噪声的细节部分,更促进学习高级特征;
- Word-Patch Alignment (WPA):学习文本单词和图像patches之间的细粒度对齐。WPA的目的是预测文本单词的相应图像补丁是否被屏蔽。具体地说,当对应的图像标记也被取消屏蔽时,为未屏蔽的文本标记分配一个对齐的标签[aligned]。否则,将指定一个未对齐的标签[unaligned]。
LayoutXLM
概述: 该模型是LayoutLMv2的多语言版本,这里不再详细赘述。
paper:LayoutXLM: Multimodal Pre-training for Multilingual Visually-rich Document Understanding
link:https://arxiv.org/abs/2104.08836
code:https://github.com/microsoft/unilm/tree/master/layoutxlm
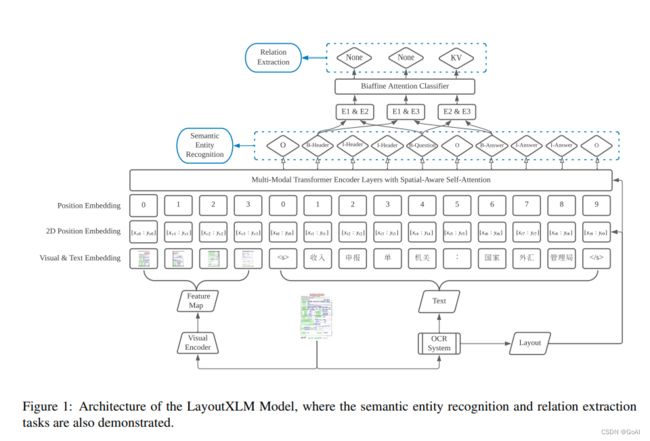
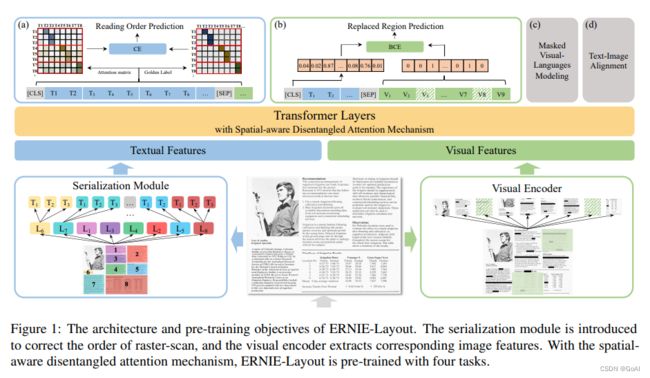
ERNIE-Layout
概述: 通过增强布局知识的预训练模型,以学习更好的表示,结合文本、布局和图像的特征。旨在利用文档布局相关信息,进行文档理解,进一步提高文档信息抽取的性能。
paper:ERNIE-Layout: Layout Knowledge Enhanced Pre-training for Visually-rich Document Understanding
link:https://arxiv.org/abs/2210.06155
code:https://github.com/PaddlePaddle/PaddleNLP/tree/develop/model_zoo/ernie-layout
引言
问题1:以OCR识别文档将信息序列化,以从左到右、从上到下的形式排列文字。然而,对于复杂结构布局的文档,效果不够理想。
解决方法:在文本输入后的序列化过程中加入一个基于布局的文档解析器,为每个输入文档生成一个合适的阅读顺序,这么做可以比OCR出来的结果的顺序更符合人类阅读习惯,然后为每个文本、视觉token都设置位置嵌入和布局嵌入。
问题2:现有方案将布局信息作为一种特殊的位置特征,如:layoutlm、layoutlmv2等,然而,布局可以看作是一种模态信息,将布局信息编码为一种特殊的位置特征,模型将缺少布局上的语义表达。
解决方法:为了实现多模态间的互动,文章借鉴了DeBERTa的解耦注意力,并提出了一种空间感知的分解注意力机制。以此向模型引入布局语义信息。
ERNIE-Layout基于Transformer Encode架构,并提出以下trick:
2.1 OCR工具提取信息
借助OCR工具提取图片中的文字及文字对应的坐标信息(bounding box)。例如:paddleOCR等.
2.2 复杂布局position_ids
如下图,文档中同时包含了双栏结构、图片、表格等内容,其布局结构非常复杂,如果借鉴传统的OCR识别,效果非常差,在ERNIE-Layout借鉴了 DeBERTa 的解耦注意力,依靠Layout-Parser来设计 position_ids。LayoutParser是借助于目标检测模型来提取重要的内容patch,从而避免了两列内容按行扫描的混乱结果。
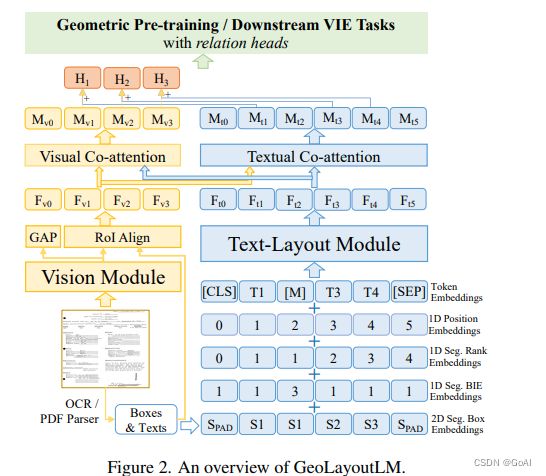
GeoLayoutLM
概述: GeoLayoutLM通过显式建模几何关系和特殊的预训练任务来提高文本和布局的特征表示。该模型能够提高文档信息抽取的性能。
paper:GeoLayoutLM: Geometric Pre-training for Visual Information Extraction
link:https://arxiv.org/abs/2304.10759
code:https://github.com/AlibabaResearch/AdvancedLiterateMachinery/tree/main/DocumentUnderstanding/GeoLayoutLM
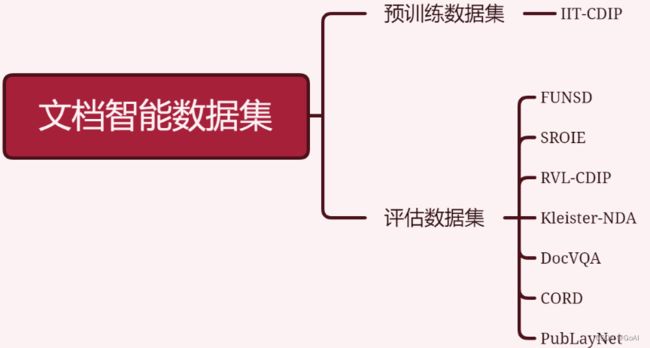
数据集
总结
本文简单介绍了文档智能领域关于多模态预训练语言模型相关内容及相关数据集,相对于基于目标检测(版面分析)的pipline形式,多模态预训练模型能够一定程度的实现端到端的提取文本内容。但实际应用还需要根据特定的场景进行进一步的研究。
学习资料
合合TextIn: 文档图像多模态大模型技术发展、探索与应用
【1】GeoLayoutLM:一种用于视觉信息提取(VIE)的多模态预训练模型
【2】https://mp.weixin.qq.com/s/3l4NvGfy8LaKuj_3HGH5pg
【3】LayoutLM: Pre-training of Text and Layout for Document Image Understanding
【4】LayoutLMv2: Multi-modal Pre-training for Visually-rich Document Understanding
【5】LayoutLMv3: Pre-training for Document AI with Unified Text and Image Masking
【6】LayoutXLM: Multimodal Pre-training for Multilingual Visually-rich Document Understanding
【7】ERNIE-Layout: Layout Knowledge Enhanced Pre-training for Visually-rich Document Understanding
【8】GeoLayoutLM: Geometric Pre-training for Visual Information Extraction