MySQL学习(五、数据操作语言DML和事务处理语言TCL)
一、数据操作语言DML
插入操作
INSERT INTO table_name [(column [, column...])] VALUES (value [, value...]);一般来说,一条INSERT只能插入一条数据,因为MYSQL没有batch操作,所以,MYSQL也支持在一条INSERT中插入多条数据
INSERT INTO table [(column [, column...])] VALUES (value [, value...]),(value [, value...]),...
当然,一条SQL的长度是有限的,可以通过调整max_allowed_packet参数;
更新操作
UPDATE table_name
SET columnName = value [, column = value] …
[WHERE condition];
UPDATE语句也可以使用表连接,子查询等多种方式执行;
删除操作
DELETE FROM table_name [WHERE condition];
在delete语句中,where子句是可选的部分,如果使用了where子句,则删除的数据是符合where条件的所有记录; 如果省略了where子句,则全表的数据都会被删除,delete语句的where条件也同样支持子查询,但是一定注意,删除语句中的where条件不能是要删除的数据表中的数据;所以,在涉及到删除的数据是通过要删除的表中的数据查询出来的,一般会把查询结果临时保存到另一张表,再通过delete语句删除;
二、事务操作语言TCL
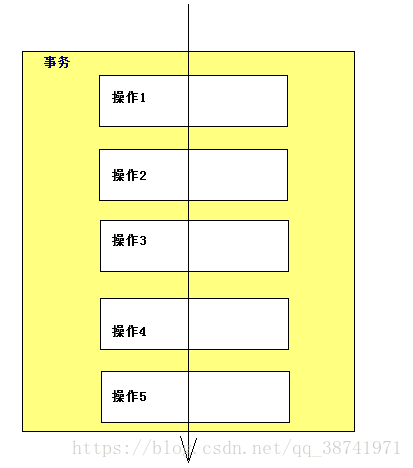
在数据库中,所谓事务是指一组逻辑操作单元,使数据从一种状态变换到另一种状态。为确保数据库中数据的一致性,数据的操纵应当是离散的成组的逻辑单元:当它全部完成时,数据的一致性可以保持,而当这个单元中的一部分操作失败,整个事务应全部视为错误,所有从起始点以后的操作应全部回退到开始状态。
事务的操作:先定义开始一个事务,然后对数据作修改操作,这时如果提交(COMMIT),这些修改就永久地保存下来,如果回退(ROLLBACK),数据库管理系统将放弃您所作的所有修改而回到开始事务时的状态。
事务的ACID:
1. 原子性(Atomicity)原子性是指事务是一个不可分割的工作单位,事务中的操作要么都发生,要么都不发生。
2. 一致性(Consistency)事务必须使数据库从一个一致性状态变换到另外一个一致性状态。(数据不被破坏).
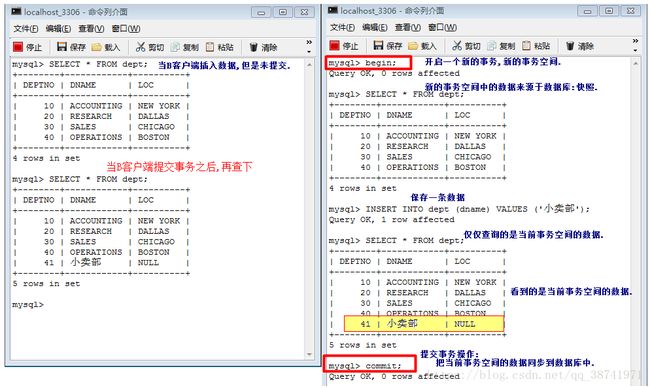
3. 隔离性(Isolation)事务的隔离性是指一个事务的执行不能被其他事务干扰,即一个事务内部的操作及使用的数据对并发的其他事务是隔离的,并发执行的各个事务之间不能互相干扰,每一个事务都存在一个事务空间,彼此不干扰。
4. 持久性(Durability)持久性是指一个事务一旦被提交,它对数据库中数据的改变就是永久性的,接下来的其他操作和数据库故障
不应该对其有任何影响.
事务控制的语言:
begin:开启一个事务,开启一个新的事务空间。
commit:提交事务。
rollback:回滚事务。
COMMIT和 ROLLBACK可以显示的控制事务。好处:
1、保证数据一致性,修改过的数据在没有提交之前是不能被其他用户看到的。
2、在数据永久性生效前重新查看修改的数据
3、将相关操作组织在一起,一个事务中相关的数据改变或者都成功,或者都失败。
数据库的事务并发问题:
存在五种问题:脏读,不可重复读,幻读,第一类丢失更新,第二类丢失更新。
为了解决上述的问题,我们提出了隔离级别的概念,不同的隔离级别可以处理的并发问题是不一样的。
使用不同的隔离级别就可以阻止自己所期望的并发问题。
使用锁机制来解决:
悲观锁: SELECT ....... FOR UPDATE.
乐观锁:使用版本控制.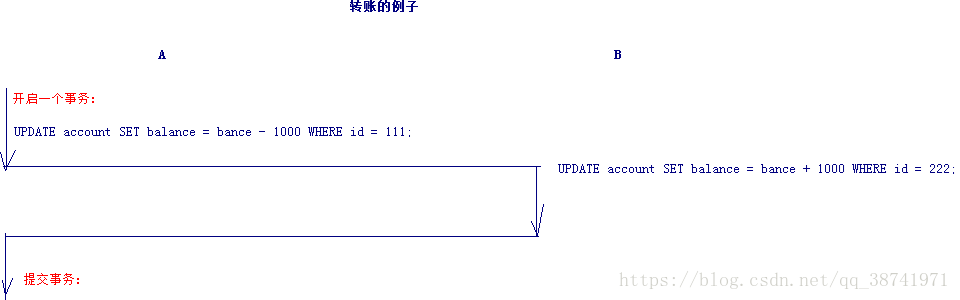





三、索引
创建索引:
自动: 当在表上定义一个PRIMARY KEY时,自动创建一个对应的唯一索引.
当在表上定义一个外键时,自动创建一个普通索引;
手动: 用户可以创建索引以加速查询,在一列或者多列上创建索引。
CREATE INDEX index ON table (column[, column]...);
如果多列在一起,就叫做复合索引;在很多情况下,复合索引比单个索引更好(理解原理即可);
--------------------------------------------------
哪些值可以创建索引?
1,外键一般要创建索引
2,经常使用的查询条件要创建索引。如果使用like ‘%’操作,不会使用索引。
3,索引不是越多越好
4,不要在可选值很少的属性上面创建索引
5,MySQL索引的使用,并不是所有情况下都会使用索引,只有当MySQL认为索引足够能够提升查询性能时才会使用;

四、视图
视图也就是虚表,实际上视图就是一个命名的查询,用于改变基表数据的显示。
视图的作用:
可以限制对数据的访问
可以使复杂的查询变的简单
提供了数据的独立性
提供了对相同数据的不同显示
--------------------------------------------
语法:
在CREATE VIEW语句后加入子查询.
CREATE [OR REPLACE] VIEW view
[(alias[, alias]...)]
AS subquery
[WITH READ ONLY];
创建视图
CREATE OR REPLACE VIEW emp_v_30
AS SELECT empno, ename, sal
FROM emp
WHERE deptno =30;
在子查询中使用别名创建视图.
CREATE VIEW sal_v_10
AS SELECT employee_id ID, last_name NAME,
salary*12 ANN_SALARY
FROM employees
WHERE department_id = 10;
在视图中的列名使用的是子查询中列的别名.