SELU︱在keras、tensorflow中使用SELU激活函数
arXiv 上公开的一篇 NIPS 投稿论文《Self-Normalizing Neural Networks》引起了圈内极大的关注,它提出了缩放指数型线性单元(SELU)而引进了自归一化属性,该单元主要使用一个函数 g 映射前后两层神经网络的均值和方差以达到归一化的效果。 Shao-Hua Sun 在 Github 上放出了 SELU 与 Relu、Leaky Relu 的对比,机器之心对比较结果进行了翻译介绍,具体的实现过程可参看以下项目地址。
项目地址:shaohua0116/Activation-Visualization-Histogram
来源机器之心:引爆机器学习圈:「自归一化神经网络」提出新型激活函数SELU
keras中使用SELU激活函数
在keras 2.0.6版本之后才可以使用selu激活函数,但是在版本2.0.5还是不行,所以得升级到这个版本。
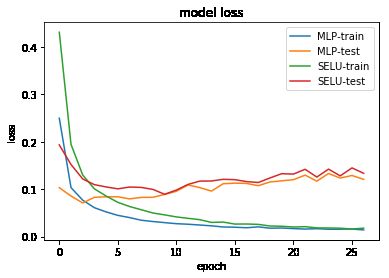
在全连接层后面接上selu最终收敛会快一些
来看一下,一个介绍非常详细的github:bigsnarfdude/SELU_Keras_Tutorial
具体对比效果:
from __future__ import print_function
import keras
from keras.datasets import mnist
from keras.models import Sequential
from keras.layers.core import Dense, Dropout, Activation
from keras.layers.noise import AlphaDropout
from keras.utils import np_utils
from keras.optimizers import RMSprop, Adam
batch_size = 128
num_classes = 10
epochs = 20
learning_rate = 0.001
# the data, shuffled and split between train and test sets
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train = x_train.reshape(60000, 784)
x_test = x_test.reshape(10000, 784)
x_train = x_train.astype('float32')
x_test = x_test.astype('float32')
x_train /= 255
x_test /= 255
print(x_train.shape[0], 'train samples')
print(x_test.shape[0], 'test samples')
# convert class vectors to binary class matrices
y_train = keras.utils.to_categorical(y_train, num_classes)
y_test = keras.utils.to_categorical(y_test, num_classes)
modelSELU = Sequential()
modelSELU.add(Dense(512, activation='selu', input_shape=(784,)))
modelSELU.add(AlphaDropout(0.1))
modelSELU.add(Dense(512, activation='selu'))
modelSELU.add(AlphaDropout(0.1))
modelSELU.add(Dense(10, activation='softmax'))
modelSELU.summary()
modelSELU.compile(loss='categorical_crossentropy',
optimizer=RMSprop(),
metrics=['accuracy'])
historySELU = modelSELU.fit(x_train, y_train,
batch_size=batch_size,
epochs=epochs,
verbose=1,
validation_data=(x_test, y_test))
scoreSELU = modelSELU.evaluate(x_test, y_test, verbose=0)
print('Test loss:', scoreSELU[0])
print('Test accuracy:', scoreSELU[1])tensorflow中使用dropout_selu + SELU
该文作者在tensorflow也加入了selu 和 dropout_selu两个新的激活函数。
可见:https://github.com/bigsnarfdude/SELU_Keras_Tutorial/blob/master/Basic_MLP_combined_comparison.ipynb
定义了两个新函数:SELU 和 dropout_selu
def selu(x):
with ops.name_scope('elu') as scope:
alpha = 1.6732632423543772848170429916717
scale = 1.0507009873554804934193349852946
return scale*tf.where(x>=0.0, x, alpha*tf.nn.elu(x))
def dropout_selu(x, keep_prob, alpha= -1.7580993408473766, fixedPointMean=0.0, fixedPointVar=1.0,
noise_shape=None, seed=None, name=None, training=False):
"""Dropout to a value with rescaling."""
def dropout_selu_impl(x, rate, alpha, noise_shape, seed, name):
keep_prob = 1.0 - rate
x = ops.convert_to_tensor(x, name="x")
if isinstance(keep_prob, numbers.Real) and not 0 < keep_prob <= 1:
raise ValueError("keep_prob must be a scalar tensor or a float in the "
"range (0, 1], got %g" % keep_prob)
keep_prob = ops.convert_to_tensor(keep_prob, dtype=x.dtype, name="keep_prob")
keep_prob.get_shape().assert_is_compatible_with(tensor_shape.scalar())
alpha = ops.convert_to_tensor(alpha, dtype=x.dtype, name="alpha")
keep_prob.get_shape().assert_is_compatible_with(tensor_shape.scalar())
if tensor_util.constant_value(keep_prob) == 1:
return x
noise_shape = noise_shape if noise_shape is not None else array_ops.shape(x)
random_tensor = keep_prob
random_tensor += random_ops.random_uniform(noise_shape, seed=seed, dtype=x.dtype)
binary_tensor = math_ops.floor(random_tensor)
ret = x * binary_tensor + alpha * (1-binary_tensor)
a = tf.sqrt(fixedPointVar / (keep_prob *((1-keep_prob) * tf.pow(alpha-fixedPointMean,2) + fixedPointVar)))
b = fixedPointMean - a * (keep_prob * fixedPointMean + (1 - keep_prob) * alpha)
ret = a * ret + b
ret.set_shape(x.get_shape())
return ret
with ops.name_scope(name, "dropout", [x]) as name:
return utils.smart_cond(training,
lambda: dropout_selu_impl(x, keep_prob, alpha, noise_shape, seed, name),
lambda: array_ops.identity(x))作者将其使用在以下案例之中:
mnist = input_data.read_data_sets("MNIST_data/", one_hot=True)
# Check out https://www.tensorflow.org/get_started/mnist/beginners for
# more information about the mnist dataset
# parameters
learning_rate = 0.001
training_epochs = 50
batch_size = 100
# input place holders
X = tf.placeholder(tf.float32, [None, 784])
Y = tf.placeholder(tf.float32, [None, 10])
# dropout (keep_prob) rate 0.7 on training, but should be 1 for testing
keep_prob = tf.placeholder(tf.float32)
# weights & bias for nn layers
# http://stackoverflow.com/questions/33640581/how-to-do-xavier-initialization-on-tensorflow
W1 = tf.get_variable("W1", shape=[784, 512],
initializer=tf.contrib.layers.xavier_initializer())
b1 = tf.Variable(tf.random_normal([512]))
L1 = selu(tf.matmul(X, W1) + b1)
L1 = dropout_selu(L1, keep_prob=keep_prob)
W2 = tf.get_variable("W2", shape=[512, 512],
initializer=tf.contrib.layers.xavier_initializer())
b2 = tf.Variable(tf.random_normal([512]))
L2 = selu(tf.matmul(L1, W2) + b2)
L2 = dropout_selu(L2, keep_prob=keep_prob)
W3 = tf.get_variable("W3", shape=[512, 512],
initializer=tf.contrib.layers.xavier_initializer())
b3 = tf.Variable(tf.random_normal([512]))
L3 = selu(tf.matmul(L2, W3) + b3)
L3 = dropout_selu(L3, keep_prob=keep_prob)
W4 = tf.get_variable("W4", shape=[512, 512],
initializer=tf.contrib.layers.xavier_initializer())
b4 = tf.Variable(tf.random_normal([512]))
L4 = selu(tf.matmul(L3, W4) + b4)
L4 = dropout_selu(L4, keep_prob=keep_prob)
W5 = tf.get_variable("W5", shape=[512, 10],
initializer=tf.contrib.layers.xavier_initializer())
b5 = tf.Variable(tf.random_normal([10]))
hypothesis = tf.matmul(L4, W5) + b5
# define cost/loss & optimizer
cost = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(
logits=hypothesis, labels=Y))
optimizer = tf.train.AdamOptimizer(learning_rate=learning_rate).minimize(cost)
# initialize
sess = tf.Session()
sess.run(tf.global_variables_initializer())
# train my model
for epoch in range(training_epochs):
avg_cost = 0
total_batch = int(mnist.train.num_examples / batch_size)
for i in range(total_batch):
batch_xs, batch_ys = mnist.train.next_batch(batch_size)
feed_dict = {X: batch_xs, Y: batch_ys, keep_prob: 0.7}
c, _ = sess.run([cost, optimizer], feed_dict=feed_dict)
avg_cost += c / total_batch
print('Epoch:', '%04d' % (epoch + 1), 'cost =', '{:.9f}'.format(avg_cost))
print('Learning Finished!')
# Test model and check accuracy
correct_prediction = tf.equal(tf.argmax(hypothesis, 1), tf.argmax(Y, 1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))