手写神经网络解决解决Mnist数字集
手写神经网络解决解决Mnist数字集
- Mnist数据集介绍和训练数据准备
- 简单神经网络的几个重要部分
- 激励函数:sigmoid
- BP神经网络类初始化:BPNetwork:__init__
- 前向计算:BPNetwork:feedforward
- 反向计算:BPNetwork:backprop
- 使用小批量平均微分更新权重和偏移量:BPNetwork:update_mini_batch
- 批量梯度下降法:BPNetwork:SGD
- 性能评估:BPNetwork:evaluate
- 训练代码
Mnist数据集介绍和训练数据准备
使用的是mnist.npz文件作为数据集。npz实际上是numpy提供的数组存储方式,简单的可看做是一系列npy数据的组合,利用np.load函数读取后得到一个类似字典的对象,可以通过关键字进行值查询,关键字对应的值其实就是一个npy数据。扩展名为.npy的文件为np用来保存未压缩的多个数组的文件格式。存取的方法 np.load np.save 。 具体 mnist数据集常见格式(npz、gz等)简介
import numpy as np
def vectorized_result(j):
"""将标签从一个字段表示的(0,1.....9)转换为1个用10维向量表示的值。称为热独编码"""
e = np.zeros((10, 1))
e[j] = 1.0
return e
try:
data = np.load('mnist.npz')
print(data.keys())
x_train, y_train, x_test, y_test = data['x_train'],data['y_train'],data['x_test'],data['y_test']
print(len(x_train),len(y_train),len(x_test),len(y_test))
# 可以将其中一条数据保存成txt文件,查看一下,会对这组数据有个直观的感受
np.savetxt('test.txt',x_train[0],fmt='%3d',newline='\n')
# 将数据归一化
x_train, x_test = x_train/255.0, x_test/255.0
except Exception as e:
print('%s' %e)
training_data=[(x.reshape((784,1)),vectorized_result(y)) for x, y in zip(x_train, y_train)]
test_data=[(x.reshape((784,1)),y) for x, y in zip(x_test, y_test)]
简单神经网络的几个重要部分
激励函数:sigmoid
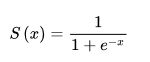
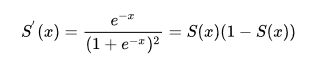
该方法主要用来对向量进行sigmoid激励
def sigmoid(z):
"""The sigmoid function."""
return 1.0/(1.0+np.exp(-z))
def sigmoid_prime(z):
"""Derivative of the sigmoid function."""
return sigmoid(z)*(1-sigmoid(z))
BP神经网络类初始化:BPNetwork:init
该类主要用来根据网络的结构,存储权重的。包括每一层的b 和 所有的w。其中,
sizes是一个list,包含了网络中每一层神经元的数量。
baises为一个list,存储中间层和输出层的每一个结点的b值。其中baises[0]保存的是第一个中间层中每一个结点的b值列表,长度为第一个中间层的结点的数量。
weights为一个list,存储中间层和结尾层与前一层的权重矩阵。其中weights[0]表示第一个中间层与输入层的权重矩阵。矩阵的形状为 输入层的结点数 * 第一个中间层的结点数。
newweights为一个list,存储中间层和结尾层与前一层的权重矩阵。其中weights[0]表示第一个中间层与输入层的权重矩阵(含b值)。矩阵的形状为第一个中间层的结点数 * 输入层的结点数+1 。
例如,sizes=[2,3,2] 则表示我们创建一个网络第一层有2个神经元,第二层有3个神经元,最后一层有2个神经元。baises为包含两个元素的列表。其中baises[0]为长度为3的列表,baises[1]为长度为2的列表。weights为包含2个元素的列表。其中weights[0]为形状为32的矩阵,weights[1]为形状为23的矩阵
newweights为包含2个元素的列表。其中newweights[0]为形状为33的矩阵,newweights[1]为形状为24的矩阵
class Network(object):
def __init__(self, sizes):
self.num_layers = len(sizes)
self.sizes = sizes
self.biases = [np.random.randn(y, 1) for y in sizes[1:]] # 为每个中间层和输出层建立一个列向量(矩阵)来存储b值。
self.weights = [np.random.randn(y, x)
for x, y in zip(sizes[:-1], sizes[1:])] # 为每个中间层和输出层建立一个(矩阵)来存储权重。形状为 【y,x】。 这样前向计算时,可以一次处理多个x的值。批量处理效果快。
self.newweights = [np.random.randn(y, x+1)
for x, y in zip(sizes[:-1], sizes[1:])]
前向计算:BPNetwork:feedforward
该方法主要用来对根据输入层的输入和各层权重的值,计算出输出层的值。该方法通过一个循环,逐层对中间层和输出层进行权重计算和激励计算。最后返回输出层的结果。该方法主要是预测的时候调用。
def feedforward(self, a):
"""Return the output of the network if ``a`` is input."""
for b, w in zip(self.biases, self.weights):
a = sigmoid(np.dot(w, a)+b)
return a
反向计算:BPNetwork:backprop
该方法主要是根据根据输入的x和y,完成一次对b值和w值的delta值(微分)的求解。
x是一维向量。y也是一维向量。
def backprop(self, x, y):
"""创建两个变量,用来存储所有b值和所有w值对应的梯度值。初始化为0.nabla_b为一个list,形状与biases的形状完全一致。nabla_w 为一个list,形状与weights的形状完全一致。
"""
nabla_b = [np.zeros(b.shape) for b in self.biases]
nabla_w = [np.zeros(w.shape) for w in self.weights]
# feedforward
"""activations,用来所有中间层和输出层在一次前向计算过程中的最终输出值,即a值。该值记录下来,以供后期使用BP算法求每个b和w的梯度。
"""
activation = x
activations = [x] # list to store all the activations, layer by layer
"""zs,用来所有中间层和输出层在一次前向计算过程中的线性输出值,即z值。该值记录下来,以供后期使用BP算法求每个b和w的梯度。
"""
zs = [] # list to store all the z vectors, layer by layer
"""
通过一次正向计算,将中间层和输出层所有的z值和a值全部计算出来,并存储起来。供接下来求梯度使用。
"""
for b, w in zip(self.biases, self.weights):
z = np.dot(w, activation)+b
zs.append(z)
activation = sigmoid(z)
activations.append(activation)
"""
以下部分是采用BP算法求解每个可训练参数的计算方法。是权重更新过程中的关键。
"""
# backward pass
# 求出输出层的delta值
delta = (activations[-1]-y) * sigmoid_prime(zs[-1])
nabla_b[-1] = delta
nabla_w[-1] = np.dot(delta, activations[-2].transpose())
# Note that the variable l in the loop below is used a little
# differently to the notation in Chapter 2 of the book. Here,
# l = 1 means the last layer of neurons, l = 2 is the
# second-last layer, and so on. It's a renumbering of the
# scheme in the book, used here to take advantage of the fact
# that Python can use negative indices in lists.
for l in range(2, self.num_layers):
z = zs[-l]
sp = sigmoid_prime(z)
delta = np.dot(self.weights[-l+1].transpose(), delta) * sp
nabla_b[-l] = delta
nabla_w[-l] = np.dot(delta, activations[-l-1].transpose())
return (nabla_b, nabla_w)
使用小批量平均微分更新权重和偏移量:BPNetwork:update_mini_batch
该方法将批次中的每一个
def update_mini_batch(self, mini_batch, eta):
"""Update the network's weights and biases by applying
gradient descent using backpropagation to a single mini batch.
The ``mini_batch`` is a list of tuples ``(x, y)``, and ``eta``
is the learning rate."""
""" 初始化变量,去存储各训练参数的微分和。
"""
nabla_b = [np.zeros(b.shape) for b in self.biases]
nabla_w = [np.zeros(w.shape) for w in self.weights]
""" 循环获取batch中的每个数据,获取各训练参数的微分,相加后获得各训练参数的微分和。
"""
for x, y in mini_batch:
delta_nabla_b, delta_nabla_w = self.backprop(x, y)
nabla_b = [nb+dnb for nb, dnb in zip(nabla_b, delta_nabla_b)]
nabla_w = [nw+dnw for nw, dnw in zip(nabla_w, delta_nabla_w)]
""" 使用各训练参数的平均微分和与步长的乘积,去更新每个训练参数
"""
self.weights = [w-(eta/len(mini_batch))*nw
for w, nw in zip(self.weights, nabla_w)]
self.biases = [b-(eta/len(mini_batch))*nb
for b, nb in zip(self.biases, nabla_b)]
批量梯度下降法:BPNetwork:SGD
该方法使用批量梯度完成一轮权重更新,并进行多轮训练,获得最优权重。每轮之后都会进行一次性能评估。
def SGD(self, training_data, epochs, mini_batch_size, eta,
test_data=None):
"""Train the neural network using mini-batch stochastic
gradient descent. The ``training_data`` is a list of tuples
``(x, y)`` representing the training inputs and the desired
outputs. The other non-optional parameters are
self-explanatory. If ``test_data`` is provided then the
network will be evaluated against the test data after each
epoch, and partial progress printed out. This is useful for
tracking progress, but slows things down substantially."""
if test_data: n_test = len(test_data)
n = len(training_data)
for j in range(epochs):
random.shuffle(training_data)
mini_batches = [
training_data[k:k+mini_batch_size]
for k in range(0, n, mini_batch_size)]
for mini_batch in mini_batches:
self.update_mini_batch(mini_batch, eta)
if test_data:
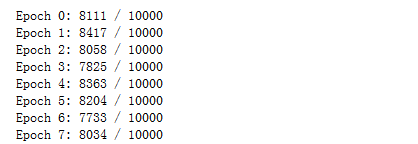
print("Epoch {0}: {1} / {2}".format(
j, self.evaluate(test_data), n_test))
else:
print("Epoch {0} complete".format(j))
性能评估:BPNetwork:evaluate
该方法返回预测值和真实值完全一致的数量,作为评价指标。
def evaluate(self, test_data):
"""Return the number of test inputs for which the neural
network outputs the correct result. Note that the neural
network's output is assumed to be the index of whichever
neuron in the final layer has the highest activation."""
test_results = [(np.argmax(self.feedforward(x)), y)
for (x, y) in test_data]
return sum(int(x == y) for (x, y) in test_results)
训练代码
net = Network([784, 30, 10])
net.SGD(training_data, 30, 1, 3.0, test_data=test_data)