Caffe代码学习及cifar-10数据集解析
Caffe代码学习及cifar-10数据集解析
Caffe代码
CIFAR-10是什么?
Cifar-10是由Hinton的两个大弟子AlexKrizhevsky和llyaSutskever收集的一个用于普通物体识别的数据集。
CIFAR是由加拿大牵头投资的一个先进的科学项目研究所。Hinton和Bengio以及他的学生在2004年拿到了CIFAR项目投资少量的资金,建立了神经计算和自适应感知项目。这个项目集结了不少的科学家,电气工程师,神经科学家,物理学家,心理学家,加速推动深度学习的经常。从这个阵容开看,DL和ML(机器学习)系列的数据挖掘分的已经很远。DL强调的是自适应感知和人工智能,是计算机与神经科学交叉的一个学科,而ML强调的是高速,大数据,统计数学分析,是计算机和数学的交叉。
2. cifar-10数据集简介
(1)CIFAR-10这个数据集总共包含:60000张图片
(2)图片size:32pixel*32pixel
(3)图片深度:三通道RGB的彩色图片
(4)这60000张图片有:50000张训练样本,10000张测试样本
记住:
(1) Cifar-10:是一个普通物体的识别的数据集,因此这个数据集合和网络模型的最大特点就是:可以很容易的将物体识别迁移到其他普通的物体
(2) 而且可以将10分类问题扩展至100类物体的分类,甚至是10000类和更多类的物体分类(当然你们需要有更多的GPU和DataSet)。
(3) 注意一点是:
这个实例中的数据集存在一个。
1.----10000*3072的numpy的数组中------10000张图片*每张的像素组
2.----单位是uint8s
3.----3072存储了一个32*32的彩色图片(3*32*32=3*1024= 3072)
![]()
4.-----numpy的前1024位是RGB中的R分量像素值,中间的1024位是G分量的像素值,最后的1024是B分量
5.-----最后注意一点是:
CIFAR-10这个例子只能用于小图片的分类,正如前面讲的Mnist实例,主要用于手写数字的识别一样。
CIFAR-10所使用的卷积神经CNN的网络模型
1---DL的两大核心:数据+模型,上面,我们详细讲述了CIFAR-10所使用的数据集,下面我们来看看CIFAR-10所使用的网络Net模型。
2.---模型在caffe中的描述配置为:cifar10_quick_train_test.prototxt
3.---该文件所在的位置:/home/wei/examples/cifar10_quick_train_test.prototxt,如下:
4.---该 CNN-NET主要由:卷积层,POOLing层,非线性的变换层,局部对比归一化线性分类器组成。
Cifar10实例的具体操作运行过程:
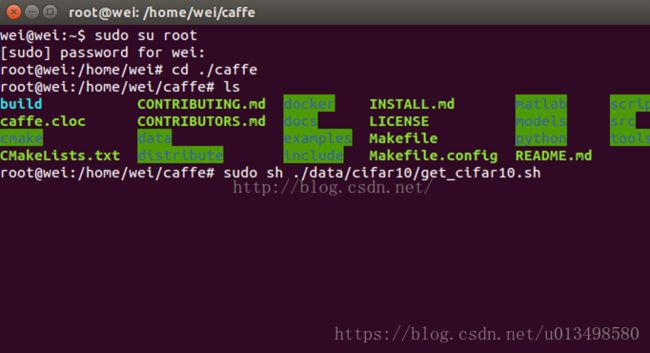
1----下载数据集
执行下面的命令:sudosh ./data/cifar10/get_cifar10.sh
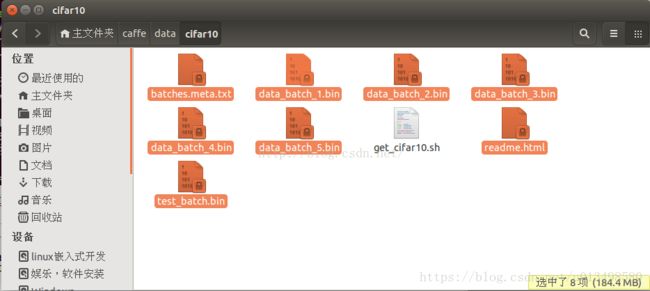
下载成功后,在/home/wei/data/cifar10/文件目录下会看到大多数的二进制文件数据;
2-----将刚才下载下来的二进制数据集文件转换成caffe所识别的LMDB或者LevelDB格式的数据库形式,并且计算数据集的均值文件
(1)数据格式的转化和计算均值所需要使用的所有的shell命令都被写在了一个shell脚本中,所以我们只需要运行这个shell
脚本就可以,这个shell脚本在:/home/amax/home/amax/caffe/examples/cifar10/文件夹下,名字为:
create_cifar10.sh
(2)使用下面的命令:sudosh ./home/amax/chunweitian/examples/cifar10/create_cifar10.sh
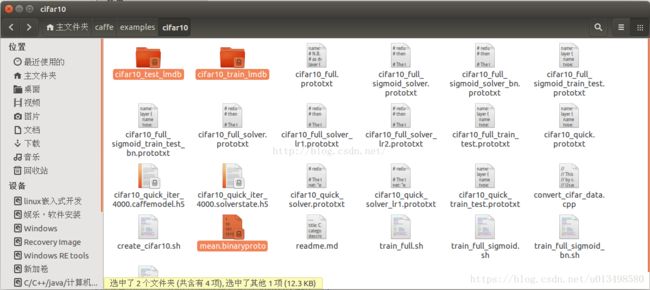
(3) 下载成功后,会在/home/amax/chunweitian/caffe/examples/cifar10/目录下生成三个文件:
cifar10_train_lmdb---训练样本数据集
cifar10_test_lmdb----测试样本数据集
mean.binaryproto----数据集的均值文件(用于减均值操作)
训练和测试网络模型
在这个阶段,寻找准备三个文件:
(1) 网络模型配置文件:cifar10_quick_train_test.prototxt
(2) 超参数配置文件:solver:cifar10_quick_solver.prototxt
(3) 训练脚本文件:train_quick_sh
1--建立训练上面数据的网络模型,当然在这个例子中,caffe已经为我们创建好了,那就是/home/wei/caffe/examples/cifar10/文件夹下面的:cifar10_quick_train_test.prototxt
2---配置参数设置solver文件,当然caffe也已经为我们准备好了,这个文件位于/home/wei/caffe/examples/cifar10/
文件夹下面的:cifar10_quick_solver.prototxt
3---编写训练模型的shell脚本文件:train_quick.sh
4---由于我使用的CPU没有GPU,所以还要改cifar10_quick_solver.prototxt配置文件的最后一项:将GPU改为CPU
准备好数据+模型+参数配置solver文件之后,执行下面的命令:
sudo./examples/cifar10/train_quick.sh、
当前位置:首页 > 电脑办公 > 电脑设计 > 程序设计 > caffe第二个比较经典的[小图片]识别例子CIFAR_10的运行,网络模型的详解
caffe cifar10 caffe第二个比较经典的[小图片]识别例子CIFAR_10的运行,网络模型的详解
分享人:虹一法师 来源:互联网 时间:2016-11-02 阅读:845次 大 中 小
分享:微信
(一)CIFAR-10简述
CIFAR-10是什么?
Cifar-10是由Hinton的两个大弟子Alex Krizhevsky和Ilya Sutskever收集的一个用于普通物体识别的数据集。
CIFAR是由加拿大牵头投资的一个先进的科学项目研究所.Hinton和Bengio以及他的学生在2004年拿到了CIFAR项目投
资的少量资金.建立了神经计算和自适应感知项目.
这个项目集结了不少的科学家,生物学家,电气工程师,神经科学家,物理学家,心理学家,加速推动了DL的进程.
从这个阵容来看,DL和ML系列的数据挖掘分的已经很远了.DL强调的是自适应感知和人工智能,是计算机与神经科学交叉
的一个学科.而ML强调的是高速,大数据,统计数学分析,是计算机和数学的交叉.
(二)cifar-10数据集简介:
1---CIFAR-10(DataSet)这个数据集总共包含:60000张图片
1---图片size:32pixel*32pixel
2---图片深度:三通道RGB的彩色图片
2---这60000张图片:
1---共分为10类,具体的分类如下图所示:
2---60000张图片里面有:
1--50000张训练样本
2--10000张测试样本(验证Set)
3---记住:
1---CIFAR-10:是一个[普通物体]识别的数据集
2---因此,这个数据集和网络模型的最大特点就是:可以很容易的将[物体识别]迁移到其他普通的物体
3---而且可以将10分类问题扩展至100类物体的分类,甚至1000类和更多类的物体分类(当然,需要你们
有更多的GPU和DataSet)

4---注意的一点是:
这个示例中的数据集存在一个L
1---10000*3072的numpy的数组中------10000张图片*每张图片的像素数组
2---单位是uint8s
3---3072存储了一个32*32的彩色图片(3*32*32==3*1024==3072)
4---numpy的前1024位是RGB中的R分量像素值,中间的1024位是G分量的像素值,最后的1024是B分量
的像素值
5---最后注意的一点是:
CIFAR-10这个例子只能用于[小图片]的分类,正如前面讲的Mnist示例,主要用于[手写数字的识别一样]
(三)CIFAR-10所使用的卷积神经CNN的网络模型
1---DL的两大核心:数据+模型,上面,我们比较详细的讲述了CIFAR-10所使用的数据集(DataSet),下面我们来
看看CIFAR-10所使用的网络Net模型吧
2---该模型在caffe中的描述配置文件为:cifar10_quick_train_test.prototxt
3---该文件所在的位置:/home/wei/caffe/examples/cifar10/cifar10_quick_train_test.prototxt,如下
图所示:
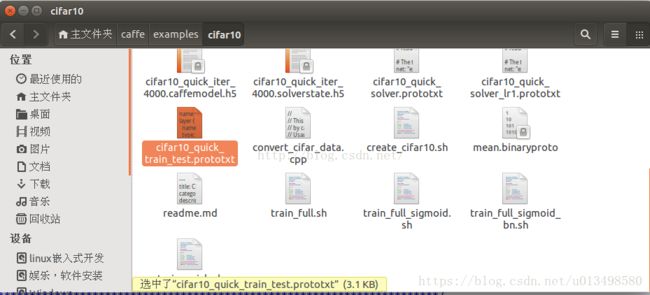
4---该CNN-NET主要由:卷积层,POOLing层,非线性变换层,局部对比归一化线性分类器组成
#(四)CIFAR10示例的具体操作运行过程:
1--下载数据集
执行下面的命令:sudo sh ./data/cifar10/get_cifra10.sh
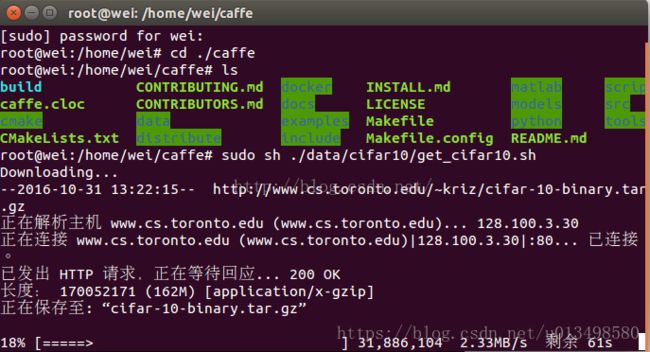
如下图所示:
下载过程如下所示:
下载成功之后,在/home/wei/data/cifar10/文件目录下会看到以下的二进制文件数据:
2--将刚才下载下来的[二进制数据集文件]转换成[caffe所识别的LMDB或者LevelDB格式的数据库形式],并且计算
数据集的均值文件
1---数据格式的转化和计算均值所需要使用的所有的shell命令都被写在了一个shell脚本中,所以我们只需
要运行这个shell脚本就可以了,这个shell脚本在:/home/wei/examples/cifar10/文件夹下,名字为:
create_cifar10.sh
2--使用下面的命令:sudo sh ./examples/cifar10/create_cifar10.sh
3--下载成功之后,会在/home/wei/caffe/examplse/cifar10/目录下生成三个文件(如下图所示):
1--cifar10_train_lmdb--------训练样本数据集
2--cifar10_test_lmdb---------测试样本数据集
3--mean.binaryproto----------数据集的均值文件(用于减均值操作)
(五)训练和测试网络模型
在这个阶段,寻妖准备三个文件:
1---网络模型配置文件:cifar10_quick_train_test.prototxt
2---超参数配置文件solver:cifar10_quick_solver.prototxt
3---训练脚本文件:train_quick.sh
1--建立训练上面数据的网络模型,当然在这个例子中,caffe已经为我们创建好了,那就是/home/wei/caffe/examples/
cifar10/文件夹下面的:cifar10_quick_train_test.prototxt
2---配置参数设置solver文件,当然caffe也已经为我们准备好了,这个文件位于/home/wei/caffe/examples/cifar10/
文件夹下面的:cifar10_quick_solver.prototxt
3---编写训练模型的shell脚本文件:train_quick.sh
4---由于我使用的CPU没有GPU,所以还要改cifar10_quick_solver.prototxt配置文件的最后一项:将GPU改为CPU
准备好数据+模型+参数配置solver文件之后,执行下面的命令:
sudo./examples/cifar10/train_quick.sh

训练的过程如下所示:
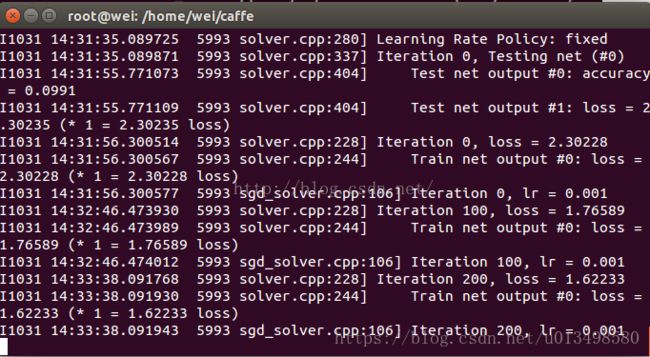
其中,每迭代100次,显示一次训练时的lr(learning rate)和loss(训练损失函数),每过500次,输出score 0(准确率)
注意:
训练完成后,训练好的模型参数存储在二进制protobuf格式的文件中,CIFAR10训练好的模型存储在:/home/wei/
caffe/examples/cifar10/文件夹低下,名字为:cifar10_quick_iter_5000
最后,总结一下训练一个网络用到的相关文件:
cifar10_quick_solver.prototxt:方案配置,用于配置迭代次数等信息,训练时直接调用caffe train指定这个文件,就会开始训练
cifar10_quick_train_test.prototxt:训练网络配置,用来设置训练用的网络,这个文件的名字会在solver.prototxt里指定
cifar10_quick_iter_4000.caffemodel.h5:训练出来的模型,后面就用这个模型来做分类
cifar10_quick_iter_4000.solverstate.h5:也是训练出来的,应该是用来中断后继续训练用的文件
cifar10_quick.prototxt:分类用的网络
Caffe代码
参考网站:https://www.zhihu.com/question/27982282
https://www.zhihu.com/question/27982282/answer/39350629
大家在学习交流时候,可以关注知乎,
.2. Caffe代码层次。
回答里面有人说熟悉Blob,Layer,Net,Solver这样的几大类,我比较赞同。我基本是从这个顺序开始学习的,这四个类复杂性从低到高,贯穿了整个Caffe。把他们分为三个层次介绍。
- Blob:是基础的数据结构,是用来保存学习到的参数以及网络传输过程中产生数据的类。
- Layer:是网络的基本单元,由此派生出了各种层类。修改这部分的人主要是研究特征表达方向的。
- Net:是网络的搭建,将Layer所派生出层类组合成网络。Solver:是Net的求解,修改这部分人主要会是研究DL求解方向的。
==============================================================
2. Caffe进阶
2.1. Blob:
Caffe支持CUDA,在数据级别上也做了一些优化,这部分最重要的是知道它主要是对protocol buffer所定义的数据结构的继承,Caffe也因此可以在尽可能小的内存占用下获得很高的效率。(追求性能的同时Caffe也牺牲了一些代码可读性)
在更高一级的Layer中Blob用下面的形式表示学习到的参数:
vector
这里使用的是一个Blob的容器是因为某些Layer包含多组学习参数,比如多个卷积核的卷积层。
以及Layer所传递的数据形式,后面还会涉及到这里:
vector
vector
2.2. Layer:
2.2.1. 5大Layer派生类型
Caffe十分强调网络的层次性,也就是说卷积操作,非线性变换(ReLU等),Pooling,权值连接等全部都由某一种Layer来表示。具体来说分为5大类Layer
- NeuronLayer类 定义于neuron_layers.hpp中,其派生类主要是元素级别的运算(比如Dropout运算,激活函数ReLu,Sigmoid等),运算均为同址计算(in-place computation,返回值覆盖原值而占用新的内存)。
- LossLayer类 定义于loss_layers.hpp中,其派生类会产生loss,只有这些层能够产生loss。
- 数据层 定义于data_layer.hpp中,作为网络的最底层,主要实现数据格式的转换。
- 特征表达层(我自己分的类)定义于vision_layers.hpp(为什么叫vision这个名字,我目前还不清楚),实现特征表达功能,更具体地说包含卷积操作,Pooling操作,他们基本都会产生新的内存占用(Pooling相对较小)。
- 网络连接层和激活函数(我自己分的类)定义于common_layers.hpp,Caffe提供了单个层与多个层的连接,并在这个头文件中声明。这里还包括了常用的全连接层InnerProductLayer类。
2.2.2. Layer的重要成员函数
在Layer内部,数据主要有两种传递方式,正向传导(Forward)和反向传导(Backward)。Forward和Backward有CPU和GPU(部分有)两种实现。Caffe中所有的Layer都要用这两种方法传递数据。
virtual void Forward(constvector
vector
virtual void Backward(const vector
const vector
vector
Layer类派生出来的层类通过这实现这两个虚函数,产生了各式各样功能的层类。Forward是从根据bottom计算top的过程,Backward则相反(根据top计算bottom)。注意这里为什么用了一个包含Blob的容器(vector),对于大多数Layer来说输入和输出都各连接只有一个Layer,然而对于某些Layer存在一对多的情况,比如LossLayer和某些连接层。在网路结构定义文件(*.proto)中每一层的参数bottom和top数目就决定了vector中元素数目。
layers {
bottom:"decode1neuron" // 该层底下连接的第一个Layer
bottom:"flatdata" // 该层底下连接的第二个Layer
top:"l2_error" // 该层顶上连接的一个Layer
name:"loss" // 该层的名字
type:EUCLIDEAN_LOSS // 该层的类型
loss_weight: 0
}
2.2.3. Layer的重要成员变量
loss
vector
每一层又有一个loss_值,只不多大多数Layer都是0,只有LossLayer才可能产生非0的loss_。计算loss是会把所有层的loss_相加。
learnable parameters
vector
前面提到过的,Layer学习到的参数。
2.3. Net:
Net用容器的形式将多个Layer有序地放在一起,其自身实现的功能主要是对逐层Layer进行初始化,以及提供Update( )的接口(更新网络参数),本身不能对参数进行有效地学习过程。
vector
同样Net也有它自己的
vector
Dtype* loss =NULL);
void Net
他们是对整个网络的前向和方向传导,各调用一次就可以计算出网络的loss了。
2.4. Solver
这个类中包含一个Net的指针,主要是实现了训练模型参数所采用的优化算法,它所派生的类就可以对整个网络进行训练了。
shared_ptr
不同的模型训练方法通过重载函数ComputeUpdateValue( )实现计算update参数的核心功能
virtual void ComputeUpdateValue() = 0;
最后当进行整个网络训练过程(也就是你运行Caffe训练某个模型)的时候,实际上是在运行caffe.cpp中的train( )函数,而这个函数实际上是实例化一个Solver对象,初始化后调用了Solver中的Solve( )方法。而这个Solve( )函数主要就是在迭代运行下面这两个函数,就是刚才介绍的哪几个函数。
ComputeUpdateValue();
net_->Update();