基于内容的推荐
思想:根据物品的属性和用户的特殊偏好,直观的选择可推荐物品。
比如,《哈利.波特》是一本科幻小说;用户爱丽丝很喜欢科幻小说,系统就会直接推荐一本新出版的《哈利.波特》给爱丽丝。
需求:
1.物品的特征描述(标签)
2.描述了用户(历史)兴趣的用户记录(标签)
首先,我们需要根据实际应用场景构建自己的标签库
标签库来源:已有内容(物品,以下相同)的标签;网络抓取流行标签;对运营的内容进行关键词提取
内容特征化(物品画像):人工打标签;机器自动打标签
其中,机器自动打标签常采用机器学习相关算法实现,如分词 + Word2Vec来实现。
1.将文本语料进行分词,使用结巴分词;
2.使用Word2Vec训练词的相似度模型;
3.使用tfidf提取内容的关键词;
4.遍历每一个标签,计算关键词于此标签的相似度之和;
5.取出TopN相似度最高的标签即为此内容的标签。
用户特征化(用户画像):
通过用户的行为日志和一定的模型算法得到用户的每个标签的权重。
1.用户对内容的行为:点赞,不感兴趣,点击,浏览。对用户的反馈行为如点赞赋予权重1,不感兴趣赋予-1,对于用户的浏览行为,使用ctr=click/pv作为权重。
2.将发生行为的内容的特征,作为用户的特征。
3.用户的兴趣是时间衰减的,可以借助时间衰减函数。
4.要考虑到热门内容会干预用户的标签,需要对热门内容进行降权。使用ctr=click/pv作为用户浏览行为权重即可达到此目的。
5.需要考虑噪声干扰,如标题党等。(这里可以考虑在数据预处理时,清除作弊数据)
物品画像和用户画像都表示成带权重的词向量
推荐:
方式一,.隐语义推荐:
用户对于某一个内容的兴趣程度可以用公式表示为:

其中i=1…N是内容c具有的标签,m(ci)指的内容c和标签i的关联度(可以简单认为是1),n(ui)指的是用户u的标签i的权重值,当用户不具有此标签时n(ui)=0,qc指的是内容c的质量,可以使用点击率(ctr=click/pv)表示。
m(ci)的计算方法也可以表示为:
1.对于存在的用户物品评分矩阵U,计算用户u所有打分的平均分AVG。
2.根据公式![]() 计算用户对某个词c的喜好程度,即m(ci)。其中xi为用户对于包含词c的物品的评分,AVG为1步得到的平均分,n为用户评过分的物品数量。
计算用户对某个词c的喜好程度,即m(ci)。其中xi为用户对于包含词c的物品的评分,AVG为1步得到的平均分,n为用户评过分的物品数量。
缺点:这种方式很依赖于用户的历史行为数据,不利于没有用户数据情况下的冷启动问题,一般适合商品不多,用户有特殊兴趣的情况。
方式二:
根据事物的相关性,通过比较事物之间共有属性的相似度进行推荐,例如,如果用户A喜欢Data2,Dota2属于竞技类游戏,那么用户A就有可能喜欢英雄联盟。
这种方式好处就是可以不用依赖用户的行为,但是要求事物的内容是准确和完善的,并且是没有歧义的,可以通过手动输入标签的方式来解决这个问题。
采用余弦相似度进行推荐:
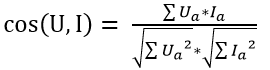
Ua表示用户对特征(关键词)a的喜好值;Ia表示物品I是否包含特征(关键词)a。
特征选择:
1.基于经验选取阈值,去除那些“太稀少”或“太频繁”的特征。
2.基于统计的方法如卡方分布(适用于大规模文本数据)。
注意事项:
近邻用户:KNN K值得选取?根据经验进行选取,一般选取20~50个
关于用户行为的处理方式:短期记录维护用户短期兴趣,长期记录(比如几个月)维护用户长期兴趣。如何组合短期模型推荐数据与长期模型推荐数据。
优缺点比较:和协同过滤算法相比,基于内容的推荐系统具有以下几个优点:
1.用户独立。基于内容的推荐系统不需要用户的近邻信息,而协同过滤方法根据相似用户的喜好进行推荐,被推荐的item只可能是近邻用户评价过的item,局限性较大。
2.可解释性。可以列出内容的特征或描述对推荐item进行解释,推荐结果更容易得到用户的信任。
3.新的item。基于内容的推荐系统可以对未被用户评分过的item进行推荐。
缺陷:
推荐结果缺乏新颖性。倾向于给出相同的推荐,会推荐与当前用户已经(正面)评价过的物品比较相似的物品。
解决方法:选取合适的阈值,滤除与用户记录差别太大的物品,也要滤除太相似的物品。
目标:提高推荐列表的惊喜度。