init进程【2】——解析配置文件
欢迎转载,转载请注明:http://blog.csdn.net/zhgxhuaa
在前面的一篇文章中分析了init进程的启动过程和main函数,本文将着重对配置文件(init.rc)的解析做一下分析。
init.rc脚本语法
init.rc文件不同于init进程,init进程仅当编译完Android后才会生成,而init.rc文件存在于Android平台源代码中。init.rc在源代码中的位置为:@system/core/rootdir/init.rc。init.rc文件的大致结构如下图所示:
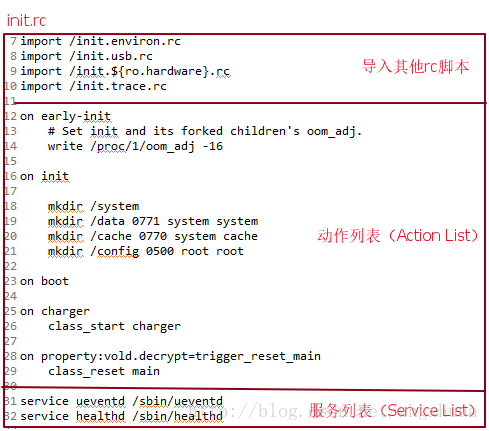
关于init.rc脚本的介绍,在@system/core/init/readme.txt中有完整的介绍,这里不再赘述,不想看英文的朋友也可以看下面的部分,这个部分关于rc脚本的介绍转自http://blog.csdn.net/nokiaguy/article/details/9109491。相当于readme的翻译吧。
init.rc文件并不是普通的配置文件,而是由一种被称为“Android初始化语言”(Android Init Language,这里简称为AIL)的脚本写成的文件。在了解init如何解析init.rc文件之前,先了解AIL非常必要,否则机械地分析init.c及其相关文件的源代码毫无意义。
为了学习AIL,读者可以到自己Android手机的根目录寻找init.rc文件,最好下载到本地以便查看,如果有编译好的Android源代码,在
AIL由如下4部分组成。
1. 动作(Actions)
2. 命令(Commands)
3.服务(Services)
4. 选项(Options)
这4部分都是面向行的代码,也就是说用回车换行符作为每一条语句的分隔符。而每一行的代码由多个符号(Tokens)表示。可以使用反斜杠转义符在Token中插入空格。双引号可以将多个由空格分隔的Tokens合成一个Tokens。如果一行写不下,可以在行尾加上反斜杠,来连接下一行。也就是说,可以用反斜杠将多行代码连接成一行代码。
AIL的注释与很多Shell脚本一行,以#开头。
AIL在编写时需要分成多个部分(Section),而每一部分的开头需要指定Actions或Services。也就是说,每一个Actions或Services确定一个Section。而所有的Commands和Options只能属于最近定义的Section。如果Commands和Options在第一个Section之前被定义,它们将被忽略。
Actions和Services的名称必须唯一。如果有两个或多个Action或Service拥有同样的名称,那么init在执行它们时将抛出错误,并忽略这些Action和Service。
下面来看看Actions、Services、Commands和Options分别应如何设置。
Actions的语法格式如下:
- on
-
-
-
也就是说Actions是以关键字on开头的,然后跟一个触发器,接下来是若干命令。例如,下面就是一个标准的Action
- on boot
- ifup lo
- hostname localhost
- domainname localdomain
其中boot是触发器,下面三行是command
那么init.rc到底支持哪些触发器呢?目前init.rc支持如下5类触发器。
1. boot
这是init执行后第一个被触发Trigger,也就是在 /init.rc被装载之后执行该Trigger
2.
当属性
on property:vold.decrypt=trigger_reset_main
class_reset main
3. device-added-
当设备节点被添加时触发
4. device-removed-
当设备节点被移除时添加
5. service-exited-
会在一个特定的服务退出时触发
Actions后需要跟若干个命令,这些命令如下:
1. exec
创建和执行一个程序(
2. export
在全局环境中将
3. ifup
启动网络接口
4. import
指定要解析的其他配置文件。常被用于当前配置文件的扩展
5. hostname
设置主机名
6. chdir
改变工作目录
7. chmod
改变文件的访问权限
8. chown
更改文件的所有者和组
9. chroot
改变处理根目录
10. class_start
启动所有指定服务类下的未运行服务。
11 class_stop
停止指定服务类下的所有已运行的服务。
12. domainname
设置域名
13. insmod
加载
14. mkdir
创建一个目录
15. mount
试图在目录
16. setkey
保留,暂时未用
17. setprop
将系统属性
18. setrlimit
设置
19. start
启动指定服务(如果此服务还未运行)。
20.stop
停止指定服务(如果此服务在运行中)。
21. symlink
创建一个指向
22. sysclktz
设置系统时钟基准(0代表时钟滴答以格林威治平均时(GMT)为准)
23. trigger
触发一个事件。用于Action排队
24. wait
等待一个文件是否存在,当文件存在时立即返回,或到
25. write
向
Services (服务)是一个程序,他在初始化时启动,并在退出时重启(可选)。Services (服务)的形式如下:
- service
[ ]*
例如,下面是一个标准的Service用法
- service servicemanager /system/bin/servicemanager
- class core
- user system
- group system
- critical
- onrestart restart zygote
- onrestart restart media
- onrestart restart surfaceflinger
- onrestart restart drm
1. critical
表明这是一个非常重要的服务。如果该服务4分钟内退出大于4次,系统将会重启并进入 Recovery (恢复)模式。
2. disabled
表明这个服务不会同与他同trigger (触发器)下的服务自动启动。该服务必须被明确的按名启动。
3. setenv
在进程启动时将环境变量
4. socket
Create a unix domain socketnamed /dev/socket/
its fd to the launchedprocess.
User and group default to0.
创建一个unix域的名为/dev/socket/
5. user
在启动这个服务前改变该服务的用户名。此时默认为 root。
6. group
在启动这个服务前改变该服务的组名。除了(必需的)第一个组名,附加的组名通常被用于设置进程的补充组(通过setgroups函数),档案默认是root。
7. oneshot
服务退出时不重启。
8. class
指定一个服务类。所有同一类的服务可以同时启动和停止。如果不通过class选项指定一个类,则默认为"default"类服务。
9. onrestart
当服务重启,执行一个命令(下详)。
init.rc脚本分析
在上一篇文章中说过,init将动作执行的时间划分为几个阶段,按照被执行的先后顺序依次为:early-init、init、early-boot、boot。在init进程的main()方法中被调用的先后顺序决定了它们的先后(直接原因), 根本原因是:各个阶段的任务不同导致后面的对前面的有依赖,所以这里的先后顺序是不能乱调整的。
@system/core/init/init.c

early-init主要用于设置init进程(进程号为1)的oom_adj的值,以及启动ueventd进程。oom_adj是Linux和Android中用来表示进程重要性的一个值,取值范围为[-17, 15]。在Android中系统在杀死进程时会根据oom_adj和空闲内存大小作为依据,oom_adj越大越容易被杀死。
Android将程序分成以下几类,按照重要性依次降低的顺序:
| 名 称 | oom_adj | 解释 |
| FOREGROUD_APP | 0 | 前 台程序,可以理解为你正在使用的程序 |
| VISIBLE_APP | 1 | 用户可见的程序 |
| SECONDARY_SERVER | 2 | 后 台服务,比如说QQ会在后台运行服务 |
| HOME_APP | 4 | HOME,就是主界面 |
| HIDDEN_APP | 7 | 被 隐藏的程序 |
| CONTENT_PROVIDER | 14 | 内容提供者, |
| EMPTY_APP | 15 | 空程序,既不提供服务,也不提供内容 |
on early-init
# Set init and its forked children's oom_adj.
write /proc/1/oom_adj -16
# Set the security context for the init process.
# This should occur before anything else (e.g. ueventd) is started.
setcon u:r:init:s0
start ueventd在执行完early-init以后,接下来就是init阶段。在init阶段主要用来:设置环境变量,创建和挂在文件节点。下面是init接的的不分代码截选:
@system/core/rootdir/init.environ.rc.in
# set up the global environment
on init
export PATH /sbin:/vendor/bin:/system/sbin:/system/bin:/system/xbin
export LD_LIBRARY_PATH /vendor/lib:/system/lib
export ANDROID_BOOTLOGO 1
export ANDROID_ROOT /system
export ANDROID_ASSETS /system/app
export ANDROID_DATA /data
export ANDROID_STORAGE /storage
export ASEC_MOUNTPOINT /mnt/asec
export LOOP_MOUNTPOINT /mnt/obb
export BOOTCLASSPATH %BOOTCLASSPATH%
以前设置环境变量这一段时在init.rc中的,现在放到了init.environ.rc.in,这样代码也更清晰一些。
@system/core/rootdir/init.rc
on init
sysclktz 0
loglevel 3
# Backward compatibility
symlink /system/etc /etc
symlink /sys/kernel/debug /d
# Right now vendor lives on the same filesystem as system,
# but someday that may change.
symlink /system/vendor /vendor
# Create cgroup mount point for cpu accounting
mkdir /acct
mount cgroup none /acct cpuacct
mkdir /acct/uid
mkdir /system
mkdir /data 0771 system system
mkdir /cache 0770 system cache
mkdir /config 0500 root root接下来是fs相关的几个过程,它们主要用于文件系统的挂载,下面是截取的一小部分代码:
on post-fs
# once everything is setup, no need to modify /
mount rootfs rootfs / ro remount
# mount shared so changes propagate into child namespaces
mount rootfs rootfs / shared rec
mount tmpfs tmpfs /mnt/secure private rec
# We chown/chmod /cache again so because mount is run as root + defaults
chown system cache /cache
chmod 0770 /cache
# We restorecon /cache in case the cache partition has been reset.
restorecon /cache如果你看过以前的版本的init.rc脚本,看到这里会想起,应该还有几行:
mount yaffs2 mtd@system /system
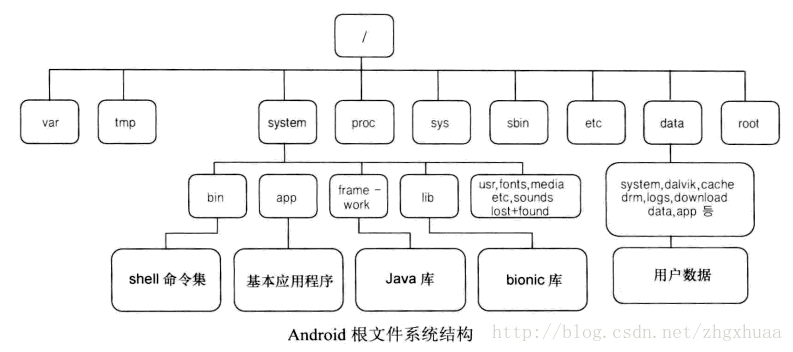
mount yaffs2 mtd@userdata /data可以看出在Android 4.4中默认已经不再使用yaffs2。在完成文件系统的创建和挂载后,完整的Android根文件系统结构如下:
接下来看一下boot部分,该部分主要用于设置应用程序终止条件,应用程序驱动目录及文件权限等。下面是一部分代码片段:
on boot
# basic network init
ifup lo
hostname localhost
domainname localdomain
# set RLIMIT_NICE to allow priorities from 19 to -20
setrlimit 13 40 40
# Memory management. Basic kernel parameters, and allow the high
# level system server to be able to adjust the kernel OOM driver
# parameters to match how it is managing things.
write /proc/sys/vm/overcommit_memory 1
write /proc/sys/vm/min_free_order_shift 4
chown root system /sys/module/lowmemorykiller/parameters/adj
chmod 0664 /sys/module/lowmemorykiller/parameters/adj
chown root system /sys/module/lowmemorykiller/parameters/minfree
chmod 0664 /sys/module/lowmemorykiller/parameters/minfree
class_start core
class_start main在on boot部分,我们可以发现许多”on property:
解析配置文件
init_parse_config_file("/init.rc");//解析init.rc配置文件int init_parse_config_file(const char *fn)
{
char *data;
data = read_file(fn, 0);
if (!data) return -1;
parse_config(fn, data);
DUMP();
return 0;
}read_file(fn, 0)函数将fn指针指向的路径(这里即:/init.rc)所对应的文件读取到内存中,保存为字符串形式,并返回字符串在内存中的地址;然后parse_config会对文件进行解析,生成动作列表(Action List)和服务列表(Service List)。关于read_file()函数的实现在@system/core/init/util.c中。下面是parse_config()的实现:
static void parse_config(const char *fn, char *s)
{
struct parse_state state;
struct listnode import_list;//导入链表,用于保持在init.rc中通过import导入的其他rc文件
struct listnode *node;
char *args[INIT_PARSER_MAXARGS];
int nargs;
nargs = 0;
state.filename = fn;//初始化filename的值为init.rc文件
state.line = 0;//初始化行号为0
state.ptr = s;//初始化ptr指向s,即read_file读入到内存中的init.rc文件的首地址
state.nexttoken = 0;//初始化nexttoken的值为0
state.parse_line = parse_line_no_op;//初始化行解析函数
list_init(&import_list);
state.priv = &import_list;
for (;;) {
switch (next_token(&state)) {
case T_EOF://如果返回为T_EOF,表示init.rc已经解析完成,则跳到parser_done解析import进来的其他rc脚本
state.parse_line(&state, 0, 0);
goto parser_done;
case T_NEWLINE:
state.line++;//一行读取完成后,行号加1
if (nargs) {//如果刚才解析的一行为语法行(非注释等),则nargs的值不为0,需要对这一行进行语法解析
int kw = lookup_keyword(args[0]);//init.rc中每一个语法行均是以一个keyword开头的,因此args[0]即表示这一行的keyword
if (kw_is(kw, SECTION)) {
state.parse_line(&state, 0, 0);
parse_new_section(&state, kw, nargs, args);
} else {
state.parse_line(&state, nargs, args);
}
nargs = 0;//复位
}
break;
case T_TEXT://将nexttoken解析的一个text保存到args字符串数组中,nargs的最大值为INIT_PARSER_MAXARGS(64),即init.rc中一行最多不能超过INIT_PARSER_MAXARGS个text(单词)
if (nargs < INIT_PARSER_MAXARGS) {
args[nargs++] = state.text;
}
break;
}
}
parser_done:
list_for_each(node, &import_list) {
struct import *import = node_to_item(node, struct import, list);
int ret;
INFO("importing '%s'", import->filename);
ret = init_parse_config_file(import->filename);
if (ret)
ERROR("could not import file '%s' from '%s'\n",
import->filename, fn);
}
}parse_config()函数,代码虽然很短,实际上却比较复杂。接下来将对其进行详细分析。首先看一下struct parse_state的定义:
struct parse_state
{
char *ptr;//指针,指向剩余的尚未被解析的数据(即:ptr指向当前解析到的位置)
char *text;//一行文本
int line; //行号
int nexttoken;//下一行的标示,T_EOF标示文件结束,T_TEXT表示需要进行解释的文本,T_NEWLINE标示一个空行或者是注释行
void *context;//一个action或者service
void (*parse_line)(struct parse_state *state, int nargs, char **args);//函数指针,指向当前行的解析函数
const char *filename;//解析的rc文件
void *priv;//执行import链表的指针
};next_token()以行为单位分割参数传递过来的字符串。
@system/core/init/parser.c
int next_token(struct parse_state *state)
{
char *x = state->ptr;
char *s;
if (state->nexttoken) {//nexttoken的值为0
int t = state->nexttoken;
state->nexttoken = 0;
return t;
}
for (;;) {
switch (*x) {
case 0://到底末尾,解析完成
state->ptr = x;
return T_EOF;
case '\n'://换行符,返回T_NEWLINE,表示下一个token是新的一行
x++;
state->ptr = x;
return T_NEWLINE;
case ' '://忽略空格、制表符等
case '\t':
case '\r':
x++;
continue;
case '#'://在当前解析到的字符为#号时,将指针一直移动到#行的末尾,然后判断下一个字符是T_NEWLINE还是T_EOF
while (*x && (*x != '\n')) x++;//注意x++,当指针移动到#行末尾时,x执行末尾的下一个字符
if (*x == '\n') {
state->ptr = x+1;
return T_NEWLINE;
} else {
state->ptr = x;
return T_EOF;
}
default:
goto text;//解析的为普通文本
}
}
textdone://x指向一个单词的开头位置,s指向末尾位置,将s设置为0(C字符串末尾为0),即表示单词结束
state->ptr = x;
*s = 0;
return T_TEXT;
text:
state->text = s = x;
textresume:
for (;;) {
switch (*x) {
case 0:
goto textdone;
case ' ':
case '\t':
case '\r':
x++;
goto textdone;
case '\n':
state->nexttoken = T_NEWLINE;
x++;
goto textdone;
case '"':
x++;
for (;;) {
switch (*x) {
case 0:
/* unterminated quoted thing */
state->ptr = x;
return T_EOF;
case '"':
x++;
goto textresume;
default:
*s++ = *x++;
}
}
break;
case '\\':
x++;
switch (*x) {
case 0:
goto textdone;
case 'n':
*s++ = '\n';
break;
case 'r':
*s++ = '\r';
break;
case 't':
*s++ = '\t';
break;
case '\\':
*s++ = '\\';
break;
case '\r':
/* \ -> line continuation */
if (x[1] != '\n') {
x++;
continue;
}
case '\n':
/* \ -> line continuation */
state->line++;
x++;
/* eat any extra whitespace */
while((*x == ' ') || (*x == '\t')) x++;
continue;
default:
/* unknown escape -- just copy */
*s++ = *x++;
}
continue;
default:
*s++ = *x++;
}
}
return T_EOF;
} 在parse_config()中通过next_token从rc脚本中解析出一行行的rc语句,下面看一下另一个重要的函数lookup_keyword()的实现:
int lookup_keyword(const char *s)
{
switch (*s++) {
case 'c':
if (!strcmp(s, "opy")) return K_copy;
if (!strcmp(s, "apability")) return K_capability;
if (!strcmp(s, "hdir")) return K_chdir;
if (!strcmp(s, "hroot")) return K_chroot;
if (!strcmp(s, "lass")) return K_class;
if (!strcmp(s, "lass_start")) return K_class_start;
if (!strcmp(s, "lass_stop")) return K_class_stop;
if (!strcmp(s, "lass_reset")) return K_class_reset;
if (!strcmp(s, "onsole")) return K_console;
if (!strcmp(s, "hown")) return K_chown;
if (!strcmp(s, "hmod")) return K_chmod;
if (!strcmp(s, "ritical")) return K_critical;
break;
case 'd':
if (!strcmp(s, "isabled")) return K_disabled;
if (!strcmp(s, "omainname")) return K_domainname;
break;
case 'e':
if (!strcmp(s, "xec")) return K_exec;
if (!strcmp(s, "xport")) return K_export;
break;
case 'g':
if (!strcmp(s, "roup")) return K_group;
break;
case 'h':
if (!strcmp(s, "ostname")) return K_hostname;
break;
case 'i':
if (!strcmp(s, "oprio")) return K_ioprio;
if (!strcmp(s, "fup")) return K_ifup;
if (!strcmp(s, "nsmod")) return K_insmod;
if (!strcmp(s, "mport")) return K_import;
break;
case 'k':
if (!strcmp(s, "eycodes")) return K_keycodes;
break;
case 'l':
if (!strcmp(s, "oglevel")) return K_loglevel;
if (!strcmp(s, "oad_persist_props")) return K_load_persist_props;
break;
case 'm':
if (!strcmp(s, "kdir")) return K_mkdir;
if (!strcmp(s, "ount_all")) return K_mount_all;
if (!strcmp(s, "ount")) return K_mount;
break;
case 'o':
if (!strcmp(s, "n")) return K_on;
if (!strcmp(s, "neshot")) return K_oneshot;
if (!strcmp(s, "nrestart")) return K_onrestart;
break;
case 'p':
if (!strcmp(s, "owerctl")) return K_powerctl;
case 'r':
if (!strcmp(s, "estart")) return K_restart;
if (!strcmp(s, "estorecon")) return K_restorecon;
if (!strcmp(s, "mdir")) return K_rmdir;
if (!strcmp(s, "m")) return K_rm;
break;
case 's':
if (!strcmp(s, "eclabel")) return K_seclabel;
if (!strcmp(s, "ervice")) return K_service;
if (!strcmp(s, "etcon")) return K_setcon;
if (!strcmp(s, "etenforce")) return K_setenforce;
if (!strcmp(s, "etenv")) return K_setenv;
if (!strcmp(s, "etkey")) return K_setkey;
if (!strcmp(s, "etprop")) return K_setprop;
if (!strcmp(s, "etrlimit")) return K_setrlimit;
if (!strcmp(s, "etsebool")) return K_setsebool;
if (!strcmp(s, "ocket")) return K_socket;
if (!strcmp(s, "tart")) return K_start;
if (!strcmp(s, "top")) return K_stop;
if (!strcmp(s, "wapon_all")) return K_swapon_all;
if (!strcmp(s, "ymlink")) return K_symlink;
if (!strcmp(s, "ysclktz")) return K_sysclktz;
break;
case 't':
if (!strcmp(s, "rigger")) return K_trigger;
break;
case 'u':
if (!strcmp(s, "ser")) return K_user;
break;
case 'w':
if (!strcmp(s, "rite")) return K_write;
if (!strcmp(s, "ait")) return K_wait;
break;
}
return K_UNKNOWN;
} case T_NEWLINE:
state.line++;//一行读取完成后,行号加1
if (nargs) {//如果刚才解析的一行为语法行(非注释等),则nargs的值不为0,需要对这一行进行语法解析
int kw = lookup_keyword(args[0]);//init.rc中每一个语法行均是以一个keyword开头的,因此args[0]即表示这一行的keyword
if (kw_is(kw, SECTION)) {
state.parse_line(&state, 0, 0);
parse_new_section(&state, kw, nargs, args);
} else {
state.parse_line(&state, nargs, args);
}
nargs = 0;//复位
}
break;在parse_config()中,在找的keyword以后,接下来会判断这个keyword是否是section,是则走解析section的逻辑,否则走其他逻辑。下面我们看一下kw_is的实现:
#define kw_is(kw, type) (keyword_info[kw].flags & (type))关键字定义
#ifndef KEYWORD//如果没有定义KEYWORD则执行下面的分支
//声明一些函数,这些函数即Action的执行函数
int do_chroot(int nargs, char **args);
int do_chdir(int nargs, char **args);
int do_class_start(int nargs, char **args);
int do_class_stop(int nargs, char **args);
int do_class_reset(int nargs, char **args);
int do_domainname(int nargs, char **args);
int do_exec(int nargs, char **args);
int do_export(int nargs, char **args);
int do_hostname(int nargs, char **args);
int do_ifup(int nargs, char **args);
int do_insmod(int nargs, char **args);
int do_mkdir(int nargs, char **args);
int do_mount_all(int nargs, char **args);
int do_mount(int nargs, char **args);
int do_powerctl(int nargs, char **args);
int do_restart(int nargs, char **args);
int do_restorecon(int nargs, char **args);
int do_rm(int nargs, char **args);
int do_rmdir(int nargs, char **args);
int do_setcon(int nargs, char **args);
int do_setenforce(int nargs, char **args);
int do_setkey(int nargs, char **args);
int do_setprop(int nargs, char **args);
int do_setrlimit(int nargs, char **args);
int do_setsebool(int nargs, char **args);
int do_start(int nargs, char **args);
int do_stop(int nargs, char **args);
int do_swapon_all(int nargs, char **args);
int do_trigger(int nargs, char **args);
int do_symlink(int nargs, char **args);
int do_sysclktz(int nargs, char **args);
int do_write(int nargs, char **args);
int do_copy(int nargs, char **args);
int do_chown(int nargs, char **args);
int do_chmod(int nargs, char **args);
int do_loglevel(int nargs, char **args);
int do_load_persist_props(int nargs, char **args);
int do_wait(int nargs, char **args);
#define __MAKE_KEYWORD_ENUM__//定义一个宏
/*
* 定义KEYWORD宏,这里KEYWORD宏中有四个参数,其各自的含义如下:
* symbol表示keyword的名称(即init.rc中的关键字);
* flags表示keyword的类型,包括SECTION、COMMAND和OPTION三种类型,其定义在init_parser.c中;
* nargs表示参数的个数,即:该keyword需要几个参数
* func表示该keyword所对应的处理函数。
*
* KEYWORD宏虽然有四个参数,但是这里只用到了symbol,其中K_##symbol中的##表示连接的意思,
* 即最后的得到的值为K_symbol。
*/
#define KEYWORD(symbol, flags, nargs, func) K_##symbol,
enum {
K_UNKNOWN,
#endif
KEYWORD(capability, OPTION, 0, 0)//根据上面KEYWORD的宏定义,这一行就变成了K_capability,
KEYWORD(chdir, COMMAND, 1, do_chdir)//key_chdir,后面的依次类推
KEYWORD(chroot, COMMAND, 1, do_chroot)
KEYWORD(class, OPTION, 0, 0)
KEYWORD(class_start, COMMAND, 1, do_class_start)
KEYWORD(class_stop, COMMAND, 1, do_class_stop)
KEYWORD(class_reset, COMMAND, 1, do_class_reset)
KEYWORD(console, OPTION, 0, 0)
KEYWORD(critical, OPTION, 0, 0)
KEYWORD(disabled, OPTION, 0, 0)
KEYWORD(domainname, COMMAND, 1, do_domainname)
KEYWORD(exec, COMMAND, 1, do_exec)
KEYWORD(export, COMMAND, 2, do_export)
KEYWORD(group, OPTION, 0, 0)
KEYWORD(hostname, COMMAND, 1, do_hostname)
KEYWORD(ifup, COMMAND, 1, do_ifup)
KEYWORD(insmod, COMMAND, 1, do_insmod)
KEYWORD(import, SECTION, 1, 0)
KEYWORD(keycodes, OPTION, 0, 0)
KEYWORD(mkdir, COMMAND, 1, do_mkdir)
KEYWORD(mount_all, COMMAND, 1, do_mount_all)
KEYWORD(mount, COMMAND, 3, do_mount)
KEYWORD(on, SECTION, 0, 0)
KEYWORD(oneshot, OPTION, 0, 0)
KEYWORD(onrestart, OPTION, 0, 0)
KEYWORD(powerctl, COMMAND, 1, do_powerctl)
KEYWORD(restart, COMMAND, 1, do_restart)
KEYWORD(restorecon, COMMAND, 1, do_restorecon)
KEYWORD(rm, COMMAND, 1, do_rm)
KEYWORD(rmdir, COMMAND, 1, do_rmdir)
KEYWORD(seclabel, OPTION, 0, 0)
KEYWORD(service, SECTION, 0, 0)
KEYWORD(setcon, COMMAND, 1, do_setcon)
KEYWORD(setenforce, COMMAND, 1, do_setenforce)
KEYWORD(setenv, OPTION, 2, 0)
KEYWORD(setkey, COMMAND, 0, do_setkey)
KEYWORD(setprop, COMMAND, 2, do_setprop)
KEYWORD(setrlimit, COMMAND, 3, do_setrlimit)
KEYWORD(setsebool, COMMAND, 2, do_setsebool)
KEYWORD(socket, OPTION, 0, 0)
KEYWORD(start, COMMAND, 1, do_start)
KEYWORD(stop, COMMAND, 1, do_stop)
KEYWORD(swapon_all, COMMAND, 1, do_swapon_all)
KEYWORD(trigger, COMMAND, 1, do_trigger)
KEYWORD(symlink, COMMAND, 1, do_symlink)
KEYWORD(sysclktz, COMMAND, 1, do_sysclktz)
KEYWORD(user, OPTION, 0, 0)
KEYWORD(wait, COMMAND, 1, do_wait)
KEYWORD(write, COMMAND, 2, do_write)
KEYWORD(copy, COMMAND, 2, do_copy)
KEYWORD(chown, COMMAND, 2, do_chown)
KEYWORD(chmod, COMMAND, 2, do_chmod)
KEYWORD(loglevel, COMMAND, 1, do_loglevel)
KEYWORD(load_persist_props, COMMAND, 0, do_load_persist_props)
KEYWORD(ioprio, OPTION, 0, 0)
#ifdef __MAKE_KEYWORD_ENUM__
KEYWORD_COUNT,
};
#undef __MAKE_KEYWORD_ENUM__
#undef KEYWORD//取消KEYWORD宏的定义
#endif看一下keyword在init_parse.c中是如何被使用的:
#include "keywords.h"
#define KEYWORD(symbol, flags, nargs, func) \
[ K_##symbol ] = { #symbol, func, nargs + 1, flags, },
struct {
const char *name;//关键字的名称
int (*func)(int nargs, char **args);//对应关键字的处理函数
unsigned char nargs;//参数个数,每个关键字的参数个数是固定的
unsigned char flags;//关键字属性,包括:SECTION、OPTION和COMMAND,其中COMMAND有对应的处理函数,见keyword的定义。
} keyword_info[KEYWORD_COUNT] = {
[ K_UNKNOWN ] = { "unknown", 0, 0, 0 },
#include "keywords.h"
};
#undef KEYWORD
#define kw_is(kw, type) (keyword_info[kw].flags & (type))
#define kw_name(kw) (keyword_info[kw].name)
#define kw_func(kw) (keyword_info[kw].func)
#define kw_nargs(kw) (keyword_info[kw].nargs)- 第一次包含keywords.h时,它声明了一些诸如do_class_start的函数,另外还定义了一个枚举,枚举值为K_class、K_mkdir等关键字。
- 第二次包含keywords.h后,得到了keyword_info结构体数组,这个keyword_info结构体数组以前定义的枚举值为索引,存储对应的关键字信息。
#define SECTION 0x01
#define COMMAND 0x02
#define OPTION 0x04在了解了keyword后,下面我们继续来分析rc脚本的解析,让我们回到之前的代码,继续分析。
case T_NEWLINE:
state.line++;//一行读取完成后,行号加1
if (nargs) {//如果刚才解析的一行为语法行(非注释等),则nargs的值不为0,需要对这一行进行语法解析
int kw = lookup_keyword(args[0]);//init.rc中每一个语法行均是以一个keyword开头的,因此args[0]即表示这一行的keyword
if (kw_is(kw, SECTION)) {
state.parse_line(&state, 0, 0);
parse_new_section(&state, kw, nargs, args);
} else {
state.parse_line(&state, nargs, args);
}
nargs = 0;//复位
}
break;void parse_new_section(struct parse_state *state, int kw,
int nargs, char **args)
{
printf("[ %s %s ]\n", args[0],
nargs > 1 ? args[1] : "");
switch(kw) {
case K_service://解析Service
state->context = parse_service(state, nargs, args);//当service_list中不存在同名service时,执行新加入service_list中的service
if (state->context) {//service为新增加的service时,即:service_list中不存在同名service
state->parse_line = parse_line_service;//制定解析service行的函数为parse_line_service
return;
}
break;
case K_on://解析section
state->context = parse_action(state, nargs, args);
if (state->context) {
state->parse_line = parse_line_action;
return;
}
break;
case K_import://解析import
parse_import(state, nargs, args);
break;
}
state->parse_line = parse_line_no_op;
}先看一下service的解析:
static void *parse_service(struct parse_state *state, int nargs, char **args)
{
struct service *svc;//保持Service相关信息
if (nargs < 3) {
parse_error(state, "services must have a name and a program\n");
return 0;
}
if (!valid_name(args[1])) {
parse_error(state, "invalid service name '%s'\n", args[1]);
return 0;
}
//service_list中是否已存在同名service
svc = service_find_by_name(args[1]);
if (svc) {//如果已存在同名service则直接返回,不再做其他操作
parse_error(state, "ignored duplicate definition of service '%s'\n", args[1]);
return 0;
}
nargs -= 2;
svc = calloc(1, sizeof(*svc) + sizeof(char*) * nargs);
if (!svc) {
parse_error(state, "out of memory\n");
return 0;
}
svc->name = args[1];
svc->classname = "default";//设置classname为“default”
memcpy(svc->args, args + 2, sizeof(char*) * nargs);
svc->args[nargs] = 0;
svc->nargs = nargs;
svc->onrestart.name = "onrestart";
list_init(&svc->onrestart.commands);
list_add_tail(&service_list, &svc->slist);//将service添加到全局链表service_list中
return svc;
}@system/core/init/init.h
struct service {
/* list of all services */
struct listnode slist;//双向链表
const char *name;//service的名字
const char *classname;//service所属class的名字,默认是“default”
unsigned flags;//service的属性
pid_t pid;//进程号
time_t time_started; /* time of last start 上一次启动的时间*/
time_t time_crashed; /* first crash within inspection window 第一次死亡的时间*/
int nr_crashed; /* number of times crashed within window 死亡次数*/
uid_t uid;
gid_t gid;
gid_t supp_gids[NR_SVC_SUPP_GIDS];
size_t nr_supp_gids;
char *seclabel;
struct socketinfo *sockets;//有些service需要使用socket,socketinfo用来描述socket相关信息
struct svcenvinfo *envvars;//service一般运行在一个单独的进程中,envvars用来描述创建这个进程时所需的环境变量信息
//关键字onrestart标示一个OPTION,可是onrestart后面一般跟着COMMAND,下面这个action结构体可用来存储command信息
struct action onrestart; /* Actions to execute on restart. */
/* keycodes for triggering this service via /dev/keychord */
int *keycodes;
int nkeycodes;
int keychord_id;
int ioprio_class;
int ioprio_pri;
int nargs;//参数个数
/* "MUST BE AT THE END OF THE STRUCT" */
char *args[1];//用于存储参数
}; /* ^-------'args' MUST be at the end of this struct! */从parse_service函数可以看出,它的作用就是讲service添加到service_list列表中,并制定解析函数为parse_line_service,也就是说具体的service的解析靠的是parse_line_service方法。
static void parse_line_service(struct parse_state *state, int nargs, char **args)
{
struct service *svc = state->context;
struct command *cmd;
int i, kw, kw_nargs;
if (nargs == 0) {
return;
}
svc->ioprio_class = IoSchedClass_NONE;
kw = lookup_keyword(args[0]);
switch (kw) {
case K_capability:
break;
case K_class:
if (nargs != 2) {
parse_error(state, "class option requires a classname\n");
} else {
svc->classname = args[1];
}
break;
case K_console:
svc->flags |= SVC_CONSOLE;
break;
case K_disabled:
svc->flags |= SVC_DISABLED;
svc->flags |= SVC_RC_DISABLED;
break;
case K_ioprio:
if (nargs != 3) {
parse_error(state, "ioprio optin usage: ioprio \n");
} else {
svc->ioprio_pri = strtoul(args[2], 0, 8);
if (svc->ioprio_pri < 0 || svc->ioprio_pri > 7) {
parse_error(state, "priority value must be range 0 - 7\n");
break;
}
if (!strcmp(args[1], "rt")) {
svc->ioprio_class = IoSchedClass_RT;
} else if (!strcmp(args[1], "be")) {
svc->ioprio_class = IoSchedClass_BE;
} else if (!strcmp(args[1], "idle")) {
svc->ioprio_class = IoSchedClass_IDLE;
} else {
parse_error(state, "ioprio option usage: ioprio <0-7>\n");
}
}
break;
case K_group:
if (nargs < 2) {
parse_error(state, "group option requires a group id\n");
} else if (nargs > NR_SVC_SUPP_GIDS + 2) {
parse_error(state, "group option accepts at most %d supp. groups\n",
NR_SVC_SUPP_GIDS);
} else {
int n;
svc->gid = decode_uid(args[1]);
for (n = 2; n < nargs; n++) {
svc->supp_gids[n-2] = decode_uid(args[n]);
}
svc->nr_supp_gids = n - 2;
}
break;
case K_keycodes:
if (nargs < 2) {
parse_error(state, "keycodes option requires atleast one keycode\n");
} else {
svc->keycodes = malloc((nargs - 1) * sizeof(svc->keycodes[0]));
if (!svc->keycodes) {
parse_error(state, "could not allocate keycodes\n");
} else {
svc->nkeycodes = nargs - 1;
for (i = 1; i < nargs; i++) {
svc->keycodes[i - 1] = atoi(args[i]);
}
}
}
break;
case K_oneshot:
svc->flags |= SVC_ONESHOT;
break;
case K_onrestart:
nargs--;
args++;
kw = lookup_keyword(args[0]);
if (!kw_is(kw, COMMAND)) {
parse_error(state, "invalid command '%s'\n", args[0]);
break;
}
kw_nargs = kw_nargs(kw);
if (nargs < kw_nargs) {
parse_error(state, "%s requires %d %s\n", args[0], kw_nargs - 1,
kw_nargs > 2 ? "arguments" : "argument");
break;
}
cmd = malloc(sizeof(*cmd) + sizeof(char*) * nargs);
cmd->func = kw_func(kw);
cmd->nargs = nargs;
memcpy(cmd->args, args, sizeof(char*) * nargs);
list_add_tail(&svc->onrestart.commands, &cmd->clist);
break;
case K_critical:
svc->flags |= SVC_CRITICAL;
break;
case K_setenv: { /* name value */
struct svcenvinfo *ei;
if (nargs < 2) {
parse_error(state, "setenv option requires name and value arguments\n");
break;
}
ei = calloc(1, sizeof(*ei));
if (!ei) {
parse_error(state, "out of memory\n");
break;
}
ei->name = args[1];
ei->value = args[2];
ei->next = svc->envvars;
svc->envvars = ei;
break;
}
case K_socket: {/* name type perm [ uid gid ] */
struct socketinfo *si;
if (nargs < 4) {
parse_error(state, "socket option requires name, type, perm arguments\n");
break;
}
if (strcmp(args[2],"dgram") && strcmp(args[2],"stream")
&& strcmp(args[2],"seqpacket")) {
parse_error(state, "socket type must be 'dgram', 'stream' or 'seqpacket'\n");
break;
}
si = calloc(1, sizeof(*si));
if (!si) {
parse_error(state, "out of memory\n");
break;
}
si->name = args[1];
si->type = args[2];
si->perm = strtoul(args[3], 0, 8);
if (nargs > 4)
si->uid = decode_uid(args[4]);
if (nargs > 5)
si->gid = decode_uid(args[5]);
si->next = svc->sockets;
svc->sockets = si;
break;
}
case K_user:
if (nargs != 2) {
parse_error(state, "user option requires a user id\n");
} else {
svc->uid = decode_uid(args[1]);
}
break;
case K_seclabel:
if (nargs != 2) {
parse_error(state, "seclabel option requires a label string\n");
} else {
svc->seclabel = args[1];
}
break;
default:
parse_error(state, "invalid option '%s'\n", args[0]);
}
} section的处理与service类似,通过分析init.rc的解析过程,我们知道,所谓的解析就是将rc脚本中的内容通过解析,填充到service_list和action_list中去。那他们是在哪里进行调用的呢,让我们回忆一下init进程中main函数的实现。
INFO("reading config file\n");
init_parse_config_file("/init.rc");//解析init.rc配置文件
action_for_each_trigger("early-init", action_add_queue_tail);
queue_builtin_action(wait_for_coldboot_done_action, "wait_for_coldboot_done");
queue_builtin_action(mix_hwrng_into_linux_rng_action, "mix_hwrng_into_linux_rng");
queue_builtin_action(keychord_init_action, "keychord_init");
queue_builtin_action(console_init_action, "console_init");
/* execute all the boot actions to get us started */
action_for_each_trigger("init", action_add_queue_tail);
/* skip mounting filesystems in charger mode */
if (!is_charger) {
action_for_each_trigger("early-fs", action_add_queue_tail);
action_for_each_trigger("fs", action_add_queue_tail);
action_for_each_trigger("post-fs", action_add_queue_tail);
action_for_each_trigger("post-fs-data", action_add_queue_tail);
}OK,到这里init.rc脚本的解析就完了。