马尔可夫决策过程(MDP)
一、强化学习引入
- 强化学习的一个经典简化图:

- 在上图中Agent首先观察获取当前环境的状态 S t S_t St,然后根据 S t S_t St采取一个行动 A t A_t At与环境进行交互,在动作 A t A_t At作用下环境的状态由 S t S_t St转变为 S t + 1 S_{t+1} St+1,同时环境会给出立即给Agent一个回报 R t R_t Rt。如此循环下去,Agent与环境进行不断地交互从而产生很多数据。强化学习算法利用产生的数据修改Agent的动作策略,再与环境交互,产生新的数据,并利用新的数据进一步改善Agent的行为,经过数次迭代学习后,智能体能最终地学到完成相应任务的最优动作。
- 在强化学习中,马尔科夫决策过程(Markov decision process, MDP)是对完全可观测的环境进行描述的,也就是说观测到的状态内容完整地决定了决策的需要的特征。几乎所有的强化学习问题都可以转化为MDP。
二、马尔科夫决策过程
- 内容大纲:
- 马尔科夫性
- 马尔科夫过程
- 马尔科夫决策过程
1、马尔科夫性
- 马尔科夫性:是指环境的下一个状态 s t + 1 s_{t+1} st+1仅与当前状态 s t s_t st有关,而与以前的状态无关,可用下面公式表达: P ( s t + 1 │ s t , … , s 1 ) = P ( s t + 1 │ s t ) P(s_{t+1}│s_t,…,s_1 )=P(s_{t+1}│s_t ) P(st+1│st,…,s1)=P(st+1│st)
- 马尔科夫性描述的是环境的每个状态的性质
- 马尔科夫随机过程:数学中用来描述随机变量序列的学科叫随机过程。所谓随机过程就是指随机变量序列。若将满足马尔可夫性的环境状态 s t s_t st视为一个随机变量,那么随机变量序列(随机过程): [ s 1 , s 2 … , s n ] [s_1,s_2…,s_n] [s1,s2…,sn]被称为马尔科夫随机过程
2、马尔科夫过程
- 马尔科夫过程:又叫马尔科夫链(Markov Chain),它是一个无记忆的随机过程,可以用一个二元组 [ S , P ] [S,P] [S,P]表示,且满足: S ∈ R N S∈R^N S∈RN是有限状态集合, P ∈ R n × n P∈R^{n×n} P∈Rn×n是状态转移概率矩阵:

- 例子:学生马尔科夫链:

- 上图是一个马尔科夫过程示例图,状态集合 S S S={娱乐,课程1,课程2,课程3,考过,睡觉,论文},状态转移概率矩阵 P P P的元素为图上边的权值。
- 一个学生一天可能的状态序列有很多种可能,比如:课1->课2->课3->考过->睡觉。这种状态序列称为马尔科夫链。当给定状态转移概率矩阵,从某个状态出发存在多条马尔科夫链。
- 但是马尔科夫过程中不存在动作(action)和奖励(reward),所有马尔科夫过程不足以描述图1所示的强化学习过程。将动作(action)和奖励(reward)考虑到马尔科夫过程中去就得到了马尔科夫决策过程。
3、马尔科夫决策过程
-
马尔科夫决策过程由元组 ( S , A , P , R , γ ) (S,A,P,R,γ) (S,A,P,R,γ)描述其中:
- S ∈ R n S∈R^n S∈Rn为有限的状态集
- A ∈ R m A∈R^m A∈Rm为有限的动作集
- P ∈ R n × m × n P∈R^{n×m×n} P∈Rn×m×n为状态转移概率矩阵
- R R R为回报函数
- γ γ γ为折扣因子,用来计算累积回报。
-
跟马尔科夫过程不同的是,马尔科夫决策过程的状态转移概率是包含动作的即: P s s ′ a = P [ S t + 1 = s ′ ∣ S t = s , A t = a ] P^a_{ss'}=P[S_{t+1}=s' |S_t=s,A_t=a] Pss′a=P[St+1=s′∣St=s,At=a]表示在状态 s s s下执行行为 a a a下一个状态为 s ′ s' s′的概率,
-
例子:学生马尔科夫决策过程:
其中黑色源点是起点,方块为终点。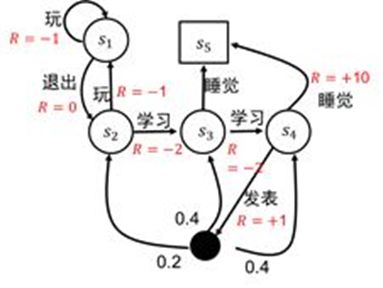
- 该图在上图的基础上加入了行为集合 A A A={完、学习、退出、睡觉、发表}和立即奖励函数 R R R
-
强化学习的目标是给定一个马尔科夫决策过程,寻找最优策略。所谓策略是指状态到动作的映射,策略常用符号 π π π表示,它是指给定状态 s s s时,动作集上的一个分布,即: π ( a │ s ) = P ( A t ∣ S t = s ) π(a│s)=P(A_t |S_t=s) π(a│s)=P(At∣St=s)
-
累计回报 G t G_t Gt:是指从 t t t时刻所能带来的所有打折后的奖励总和: G t = R t + 1 + γ R t + ⋯ = ∑ k = 1 ∞ r k R t + k + 1 G_t=R_{t+1}+γR_t+⋯=∑_{k=1}^∞r^k R_{t+k+1} Gt=Rt+1+γRt+⋯=k=1∑∞rkRt+k+1
- 当给定策略 π π π时,假设从状态 s 1 s_1 s1出发,学生状态序列有很多的可能: s 1 → s 2 → s 3 → s 4 → s 5 s 1 → s 2 → s 3 → s 5 … … … … s_1→s_2→s_3→s_4→s_5\\s_1→s_2→s_3→s_5\\ ………… s1→s2→s3→s4→s5s1→s2→s3→s5…………
- 为了评价状态 s 1 s_1 s1的价值,我们需要定义一个确定量来描述状态 s 1 s_1 s1的价值,很自然的想法是利用累积回报来衡量状态 s 1 s_1 s1的价值。然而,由于策略 π π π是随机的,因此累积回报 G 1 G_1 G1是个随机变量,不是一个确定值,因此无法进行描述。但其期望是个确定值,可以作为状态 s 1 s_1 s1的价值。每个状态的价值又被称为状态值函数。
-
状态值函数:
- 当Agent采用策略 π π π时,累积回报 G G G服从一个分布,累积回报在状态 s s s处的期望值定义为状态值函数: v π ( s ) = E π [ ∑ k ∞ γ k R t + k + 1 ∣ S t = s ] v_π (s)=E_π [∑_k^∞γ^k R_{t+k+1} |S_t=s] vπ(s)=Eπ[k∑∞γkRt+k+1∣St=s]该式子是所有以状态 s s s为起点的状态序列的累计回报的期望(概率加权和)。
- 状态值函数是与策略 π π π是相对应的,这是因为策略 π π π决定了累积回报 G G G的状态分布。
- 例子:学生马尔科夫链的状态值函数示意图:
节点的数字就是状态值函数

-
状态-行为值函数: q π ( s , a ) = E π [ ∑ k ∞ γ k R ( t + k + 1 ) ∣ S t = s , A t = a ] q_π (s,a)=E_π [∑_k^∞γ^k R_(t+k+1) |S_t=s,A_t=a] qπ(s,a)=Eπ[k∑∞γkR(t+k+1)∣St=s,At=a]
- 由表示可以看出状态-行为值函数 q π ( s , a ) q_π (s,a) qπ(s,a)是在状态值函数 v π ( s ) v_π (s) vπ(s)的基础上选定一个动作 a a a而得到的。
-
上面两个式子分别给出了状态值函数和状态-行为值函数的定义计算式,但在实际真正计算和编程的时候并不会按照定义式去编程。
-
状态值函数与状态-行为值函数的贝尔曼方程:
- 状态值函数的贝尔曼方程 : v ( s ) = E [ G t │ S t = s ] = E [ R t + 1 + γ R t + 2 + ⋯ │ S t = s ] = E [ R t + 1 + γ ( R t + 2 + γ R t + 3 + ⋯ ) │ S t = s ] = E [ R t + 1 + γ G t + 1 │ S t = s ] = E [ R t + 1 + γ v ( S t + 1 ) ∣ S t = s ] v(s)=E[G_t│S_t=s]\\ =E[R_{t+1}+γR_{t+2}+⋯│S_t=s]\\ =E[R_{t+1}+γ(R_{t+2}+γR_{t+3}+⋯)│S_t=s] \\ =E[R_{t+1}+γG_{t+1}│S_t=s]\\ =E[R_{t+1}+γv(S_{t+1})|S_t=s] v(s)=E[Gt│St=s]=E[Rt+1+γRt+2+⋯│St=s]=E[Rt+1+γ(Rt+2+γRt+3+⋯)│St=s]=E[Rt+1+γGt+1│St=s]=E[Rt+1+γv(St+1)∣St=s]最后一个等式的证明: v ( s ) = E s , S t + 1 … [ R t + 1 + γ G t + 1 ] = E s , S t + 1 [ R t + 1 + γ E S t + 1 … [ G t + 1 ] ] = E s , S t + 1 [ R t + 1 + γ v ( S t + 1 ) ] v(s)=E_{s,S_{t+1}…} [R_{t+1}+γG_{t+1} ]\\ =E_{s,S_{t+1} } [R_{t+1}+γE_{S_{t+1}…}[G_{t+1}]]\\=E_{s,S_{t+1} } [R_{t+1}+γv(S_{t+1} )] v(s)=Es,St+1…[Rt+1+γGt+1]=Es,St+1[Rt+1+γESt+1…[Gt+1]]=Es,St+1[Rt+1+γv(St+1)]其中: s , S t + 1 … s,S_{t+1}… s,St+1…是枚举所有的以状态 s s s为起点的状态序列。 s , S t + 1 s,S_{t+1} s,St+1表示状态s到状态 S t + 1 S_{t+1} St+1的概率分布(可以直接连接为概率)。
- 状态-动作值函数的贝尔曼方程: q π ( s , a ) = E π [ R t + 1 + γ q π ( S t + 1 , A t + 1 ) ∣ S t = s , A t = a ] q_π (s,a)=E_π [R_{t+1}+γq_π (S_{t+1},A_{t+1})|S_t=s,A_t=a] qπ(s,a)=Eπ[Rt+1+γqπ(St+1,At+1)∣St=s,At=a]
-
状态值函数与状态-行为值函数的分解公式:
- 状态值函数的计算分解示意图:
其中空心点表示状态,实心点表示行为

- 由B图可以得到: v π ( s ) = ∑ a ∈ A π ( a │ s ) q π ( s , a ) v_π (s)=∑_{a∈A}π(a│s) q_π (s,a) vπ(s)=a∈A∑π(a│s)qπ(s,a)
- 由C图可以得到: q π ( s , a ) = R s a + γ ∑ s ′ P s s ′ a v π ( s ′ ) q_π (s,a)=R_s^a+γ∑_{s'}P_{ss'}^a v_π (s') qπ(s,a)=Rsa+γs′∑Pss′avπ(s′) R s a R_s^a Rsa是在状态s采取行为 a a a获得的收益, P s s ′ a P_{ss'}^a Pss′a在状态 s s s采取行为 a a a后状态转变为 s ′ s' s′的概率。
- 最终状态值函数变为: v π ( s ) = ∑ a ∈ A π ( a │ s ) ( R s a + γ ∑ s ′ P s s ′ a v π ( s ′ ) ) v_π (s)=∑_{a∈A}π(a│s)(R_s^a+γ∑_{s'}P_{ss'}^a v_π (s' )) vπ(s)=a∈A∑π(a│s)(Rsa+γs′∑Pss′avπ(s′))
- 状态-行为值函数的计算分解示意图:

- 由图C可以得到: v π ( s ′ ) = ∑ a ∈ A π ( a ′ │ s ′ ) q π ( s ′ , a ′ ) v_π (s')=∑_{a∈A}π(a'│s' ) q_π (s',a') vπ(s′)=a∈A∑π(a′│s′)qπ(s′,a′)
- 最终得到行为状态-行为值函数: q π ( s , a ) = R s a + γ ∑ s ′ ∈ S P s s ′ a ∑ a ∈ A π ( a ′ │ s ′ ) q π ( s ′ , a ′ ) q_π (s,a)=R_s^a+γ∑_{s'∈S}P_{ss'}^a ∑_{a∈A}π(a'│s' ) q_π (s',a') qπ(s,a)=Rsa+γs′∈S∑Pss′aa∈A∑π(a′│s′)qπ(s′,a′)
- 状态值函数的计算分解示意图:
-
计算状态值函数的目的是为了构建学习算法从数据中得到最优策略。每个策略对应着一个状态值函数,最优策略自然对应着最优状态值函数;
- 最优状态值函数 v ∗ ( s ) v^*(s) v∗(s)为:在所有策略中值最大的状态值函数即: v ∗ ( s ) = m a x π v π ( s ) v^* (s)=max_πv_π (s) v∗(s)=maxπvπ(s)
- 最优状态-行为值函数 q ∗ ( s , a ) q^*(s,a) q∗(s,a)为:在所有策略中最大的状态-行为值函数,即: q ∗ ( s , a ) = m a x π q π ( s , a ) q^*(s,a)=max_πq_π (s,a) q∗(s,a)=maxπqπ(s,a)
-
最优状态值函数和最优状态-行动值函数的贝尔曼最优方程:
-
最优状态值函数: v ∗ ( s ) = m a x π v π ( s ) = m a x π ( ∑ a ∈ A π ( a │ s ) q π ( s , a ) ) v^* (s)=max_πv_π (s)=max_π(∑_{a∈A}π(a│s) q_π (s,a)) v∗(s)=maxπvπ(s)=maxπ(a∈A∑π(a│s)qπ(s,a))假设最优决策为 π ∗ π^* π∗,假设 a ∗ = a r g m a x a q π ∗ ( s , a ) = a r g m a x a q ∗ ( s , a ) a^*=arg max_aq_{π^* } (s,a)=arg max_aq^* (s,a) a∗=argmaxaqπ∗(s,a)=argmaxaq∗(s,a),则要想 v ∗ ( s ) v^*(s) v∗(s)最大必须有: π ∗ ( a │ s ) = { 1 if a = a ∗ 1 if a ≠ a ∗ π^*(a│s)= \begin{cases} 1& \text{if } a=a^* \\ 1 & \text{if } a≠a^* \end{cases} π∗(a│s)={11if a=a∗if a=a∗这样就有: v ∗ ( s ) = m a x a q ∗ ( s , a ) v^*(s)=max_aq^*(s,a) v∗(s)=maxaq∗(s,a)由此可知:最优状态值函数为与其相连的最优状态-行动值函数的最大值决定
-
最优状态-行动值函数: q ∗ ( s , a ) = m a x π q π ( s , a ) = m a x π ( R s a + γ ∑ s ′ P s s ′ a v π ( s ′ ) ) = R s a + γ ∑ s ′ ∈ S P s s ′ a m a x π v π ( s ′ ) = R s a + γ ∑ s ′ ∈ S P s s ′ a v ∗ ( s ′ ) q^*(s,a)=max_πq_π (s,a)\\=max_π(R_s^a+γ∑_{s'}P_{ss'}^a v_π (s'))\\=R_s^a+γ∑_{s'∈S}P_{ss'}^a max_πv_π (s') =R_s^a+γ∑_{s'∈S}P_{ss'}^a v^*(s') q∗(s,a)=maxπqπ(s,a)=maxπ(Rsa+γs′∑Pss′avπ(s′))=Rsa+γs′∈S∑Pss′amaxπvπ(s′)=Rsa+γs′∈S∑Pss′av∗(s′)由此可知:最优状态-行动值函数为与其相连的最优状态值函数的概率加权和。由于: v ∗ ( s ′ ) = m a x a ′ q ∗ ( s ′ , a ′ ) v^* (s')=max_{a'}q^*(s',a') v∗(s′)=maxa′q∗(s′,a′)所以最终最优状态-行动值函数为: q ∗ ( s , a ) = R s a + γ ∑ s ′ ∈ S P s s ′ a m a x a ′ q ∗ ( s ′ , a ′ ) q^* (s,a)=R_s^a+γ∑_{s'∈S}P_{ss'}^a max_a'q^* (s',a') q∗(s,a)=Rsa+γs′∈S∑Pss′amaxa′q∗(s′,a′)
-
所以最终最优状态值函数为: v ∗ ( s ) = m a x a q ∗ ( s , a ) = m a x a ( R s a + γ ∑ s ′ ∈ S P s s ′ a m a x π v π ( s ′ ) ) = m a x a ( R s a + γ ∑ s ′ ∈ S P s s ′ a v ∗ ( s ′ ) ) v^*(s)=max_aq^* (s,a)=max_a(R_s^a+γ∑_{s'∈S}P_{ss'}^a max_πv_π (s' ))\\=max_a(R_s^a+γ∑_{s'∈S}P_{ss'}^a v^*(s') ) v∗(s)=maxaq∗(s,a)=maxa(Rsa+γs′∈S∑Pss′amaxπvπ(s′))=maxa(Rsa+γs′∈S∑Pss′av∗(s′))
-
-
例子:学生马尔科决策过程的最优值函数和最优策略如下图:

4、马尔可夫决策过程的形式化描述:
- 定义一个马尔科夫决策过程: M = ( S , A , P , r , ρ 0 , γ , T ) M=(S,A,P,r,ρ_0,γ,T) M=(S,A,P,r,ρ0,γ,T)其中:
- S S S为状态集
- A A A为动作集
- P ∈ R ∣ S ∣ × ∣ A ∣ × ∣ S ∣ P∈R^{|S|×|A|×|S|} P∈R∣S∣×∣A∣×∣S∣为状态概率转移矩阵
- r ∈ R ∣ S ∣ × ∣ A ∣ r∈R^{|S|×|A|} r∈R∣S∣×∣A∣为回报函数
- γ ∈ [ 0 , 1 ] γ∈[0,1] γ∈[0,1]为折扣因子
- T T T为水平范围(其实就是步数)
- 令 τ = ( s 0 , a 0 , s 1 , a 2 , … , s T , a T ) τ=(s_0,a_0,s_1,a_2,…,s_T,a_T) τ=(s0,a0,s1,a2,…,sT,aT)为一个决策轨迹
- 令一个决策轨迹的累积回报为: R = ∑ t = 0 T γ t r t R=∑_{t=0}^Tγ^t r_t R=t=0∑Tγtrt
- 强化学习的目标是:找到最优策略 π π π,使得该策略下的累积回报期望最大,即: m a x π ∑ τ R ( τ ) P π ( τ ) max_π∑_τR(τ) P_π (τ) maxπτ∑R(τ)Pπ(τ)
5、强化学习算法分类:
- 强化学习算法根据以策略为中心还是以值函数最优为中心可以分为两大类:
- 策略优化方法:又分为进化算法和策略梯度方法
- 动态规划方法:又分为策略迭代算法和值迭代算法
- 强化学习算法根据策略是否是随机的:
- 确定性策略强化学习
- 随机性策略强化学习
- 强化学习算法根据转移概率是否已知可以分为:
- 基于模型的强化学习算法
- 无模型的强化学习算法
- 根据回报函数$r∈R^{|S|×|A|}是否已知可以分为:
- 强化学习
- 逆向强化学习:逆向强化学习是根据专家实例将回报函数学出来
参考连接https://zhuanlan.zhihu.com/p/25498081