MXNET深度学习框架-21-使用gluon的NiN(Network in Network)
我们通常所使用的卷积神经网络,它的结构一般是这样的【左图】(卷积工作做完了之后直接全连接),而另一个更自然的想法是这样的【右图】(卷积+全连接,之后又跟上卷积+全连接,俗称“网中网”):
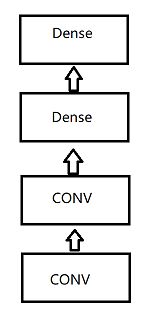
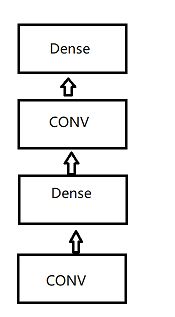
不过这里可能会遇到一个难题,卷积是4D矩阵,全连接是2D矩阵,如果把4D转成2D,会导致全连接层有过多的参数,所以NiN提出只对通道层做全连接,并且像素之间共享权重来解决该问题。也就是说,我们使用kernel大小是1×1的卷积。
用一段通俗的话来解释:比如全连接层有1000个神经元输入,有100个神经元输出,那么全连接层的作用就是将1000变为100,而1×1的卷积就是干这件事,它没办法影响卷积尺寸,但它可以影响feature(特征图)的个数,可以把1000个特征图变成100个特征图。
下面实现以下代码:
# conv+dense(conv(1X1))
def mlpconv(channels,kernel_size,padding,strides=1,max_pooling=True):
net=gn.nn.Sequential()
with net.name_scope():
net.add(gn.nn.Conv2D(channels=channels,kernel_size=kernel_size,
strides=strides,padding=padding,activation="relu"),
# 可以简单认为后面接了两个全连接(局部化)
gn.nn.Conv2D(channels=channels,kernel_size=1,strides=1,
padding=padding,activation="relu"),
gn.nn.Conv2D(channels=channels, kernel_size=1, strides=1,
padding=padding, activation="relu")
)
if max_pooling:
net.add(gn.nn.MaxPool2D(pool_size=3,strides=2))
return net
运行一个实例:
# 运行一个实例看看
blk=mlpconv(channels=16,kernel_size=3,padding=0)
blk.initialize()
x=nd.random_normal(shape=(1,3,8,8)) # nchw
print(blk(x).shape)
结果:
![]()
因为NiN是在AlexNet问世不久后提出的。它们的卷积层设定有类似之处。NiN使用卷积窗口形状分别为11×11、5×5和3×3的卷积层,相应的输出通道数也与AlexNet中的一致。
11×11:96;
5×5:256;
3×3:384
除了使用1×1的卷积之外,NiN还使用了全局平均池化,将每个通道里的数值平均成一个标量。
下面我们来定义一下模型:
'''---模型定义---'''
def get_net():
net=gn.nn.Sequential()
with net.name_scope():
net.add(mlpconv(channels=96,kernel_size=11,padding=0,strides=4),
mlpconv(channels=256,kernel_size=5,padding=2),
mlpconv(channels=384,kernel_size=3,padding=1),
gn.nn.Dropout(0.5), # 降低模型复杂度
# 总共10类,所以channel=10,不适用max pool,因为后面使用GAP(全局平均池化)
mlpconv(channels=10,kernel_size=3,padding=1,max_pooling=False),
# 如果输入为224,那么pool_size为5,即batch_sizeX10X5X5
gn.nn.GlobalAvgPool2D(),
# 转成batch_sizeX10
gn.nn.Flatten())
return net
上述参数大部分是按照AlexNet的参数来实施。
接下来放上所有代码:
import mxnet.ndarray as nd
import mxnet.autograd as ag
import mxnet.gluon as gn
import mxnet as mx
import matplotlib.pyplot as plt
import sys
from mxnet import init
import os
# conv+dense(conv(1X1))
def mlpconv(channels,kernel_size,padding,strides=1,max_pooling=True):
net=gn.nn.Sequential()
with net.name_scope():
net.add(gn.nn.Conv2D(channels=channels,kernel_size=kernel_size,
strides=strides,padding=padding,activation="relu"),
# 可以简单认为后面接了两个全连接(局部化)
gn.nn.Conv2D(channels=channels,kernel_size=1,strides=1,
padding=0,activation="relu"),
gn.nn.Conv2D(channels=channels, kernel_size=1, strides=1,
padding=0, activation="relu")
)
if max_pooling:
net.add(gn.nn.MaxPool2D(pool_size=3,strides=2))
return net
# # 运行一个实例看看
# blk=mlpconv(channels=16,kernel_size=3,padding=0)
# blk.initialize()
# x=nd.random_normal(shape=(1,3,8,8)) # nchw
# print(blk(x).shape)
ctx=mx.gpu()
'''---模型定义---'''
def get_net():
net=gn.nn.Sequential()
with net.name_scope():
net.add(mlpconv(channels=96,kernel_size=11,padding=0,strides=4),
mlpconv(channels=256,kernel_size=5,padding=2),
mlpconv(channels=384,kernel_size=3,padding=1),
gn.nn.Dropout(0.5), # 降低模型复杂度
# 总共10类,所以channel=10,不适用max pool,因为后面使用GAP(全局平均池化)
mlpconv(channels=10,kernel_size=3,padding=1,max_pooling=False),
# 如果输入为224,那么pool_size为5,即batch_sizeX10X5X5
gn.nn.GlobalAvgPool2D(),
# 转成batch_sizeX10
gn.nn.Flatten())
return net
net=get_net()
net.initialize(ctx=ctx,init=init.Xavier())
# X = nd.random.uniform(shape=(1, 1, 224, 224),ctx=ctx)
# for layer in net:
# X = layer(X)
# print(layer.name, 'output shape:\t', X.shape)
'''---读取数据和预处理---'''
def load_data_fashion_mnist(batch_size, resize=None):
transformer = []
if resize:
transformer += [gn.data.vision.transforms.Resize(resize)]
transformer += [gn.data.vision.transforms.ToTensor()]
transformer = gn.data.vision.transforms.Compose(transformer)
mnist_train = gn.data.vision.FashionMNIST(train=True)
mnist_test = gn.data.vision.FashionMNIST(train=False)
train_iter = gn.data.DataLoader(
mnist_train.transform_first(transformer), batch_size, shuffle=True)
test_iter = gn.data.DataLoader(
mnist_test.transform_first(transformer), batch_size, shuffle=False)
return train_iter, test_iter
batch_size=128
train_iter,test_iter=load_data_fashion_mnist(batch_size,resize=112)
# 定义准确率
def accuracy(output,label):
return nd.mean(output.argmax(axis=1)==label).asscalar()
def evaluate_accuracy(data_iter,net):# 定义测试集准确率
acc=0
for data,label in data_iter:
data, label = data.as_in_context(ctx), label.as_in_context(ctx)
label = label.astype('float32')
output=net(data)
acc+=accuracy(output,label)
return acc/len(data_iter)
# softmax和交叉熵分开的话数值可能会不稳定
cross_loss=gn.loss.SoftmaxCrossEntropyLoss()
# 优化
train_step=gn.Trainer(net.collect_params(),'sgd',{"learning_rate":0.2})
# 训练
lr=0.1
epochs=20
for epoch in range(epochs):
n=0
train_loss=0
train_acc=0
for image,y in train_iter:
image, y = image.as_in_context(ctx), y.as_in_context(ctx)
y = y.astype('float32')
with ag.record():
output = net(image)
loss = cross_loss(output, y)
loss.backward()
train_step.step(batch_size)
train_loss += nd.mean(loss).asscalar()
train_acc += accuracy(output, y)
test_acc = evaluate_accuracy(test_iter, net)
print("Epoch %d, Loss:%f, Train acc:%f, Test acc:%f"
%(epoch,train_loss/len(train_iter),train_acc/len(train_iter),test_acc))
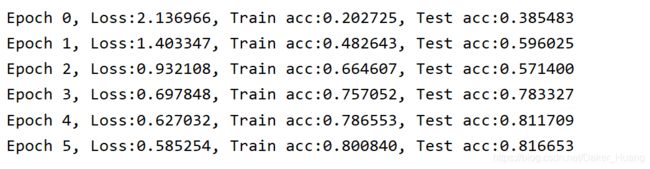
训练结果: