mysql-索引
这里写自定义目录标题
- 索引
- B-Tree索引
- hash索引
- 前缀索引和索引选择性
- 聚簇索引
- 压缩前缀索引
- 事务
- 事务日志
- 多版本并发控制(MVCC)
- 存储引擎
- 查询路径
索引
B-Tree索引
假设建立组合索引a,b,c三个列
存储时,当a和a相等时,才会根据b排序,紧接着根据c
所以不是根据最左列,无法索引,
同理,无法根据%结尾查询
不能跳过索引列,如跳过b,则只能根据a索引
有某个列范围查询,则右边列无法使用索引(因为需要遍历,所以用不上)
hash索引
memory,NDB引擎支持,产生hash冲突,链表存储
hash索引数据结构

hash索引只包含hash值和行指针,而不存储字段值,所以不能使用索引中的值来避免读取行,
hash索引无序,所以无法排序
不支持部分索引列匹配查找,如在A,B列建立hash索引,只查询A,则无法索引.
只支持等值比较查询,如=,IN(),<=>
hash冲突越多,查询和删除,都需要遍历链表,所以代价越大
创建自定义hash索引
在B-tree上将某个列转成hash值存储,然后据此定位,避免冲突where带入hash值以及对应列值即可.
中型表,索引优化
大型表,元数据信息表优化,也就是新建一个表记录所需数据位置
参与运算,无法索引
前缀索引和索引选择性
索引过长字符列
模拟hash索引
前缀索引
无法order by和group by,无法使用索引覆盖扫描
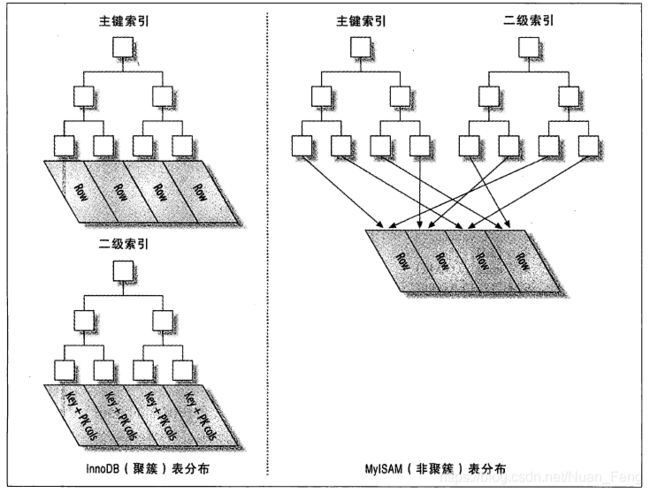
聚簇索引
聚簇:表示数据行和相邻键值紧凑存储在一起.
innodb,根节点存储主键,事务ID,MVCC的回滚指针以及剩余列,当没设置主键,则默认唯一非空索引代替,如何没有则隐式定义一个主键作为聚簇索引.
二级索引,存储索引+主键,当innodb移动行时,无效修改二级索引
myISAM存储的是主键和行指针,二级索引+行指针
覆盖索引
只访问有存储索引列,
压缩前缀索引

事务
死锁场景
A线程修改userId=4
A线程修改userId=3
B线程修改userId=3
B线程修改userId=4
Innodb将持有最少行级排它锁的事务回滚,解决死锁问题.
事务日志
预写式日志:存储引擎在修改表的数据时,修改其内存拷贝,再把修改行位记录到持久在硬盘的事务日志中,而不用每次修改数据持久磁盘.
事务日志采用追加方式,所以写日志的操作是磁盘上一小块区域内的顺序IO,而不像随机IO需要在磁盘多个地方移动磁头.事务日志持久化后,内存中被修改的数据在后台可慢慢刷回磁盘.
多版本并发控制(MVCC)
乐观并发控制
悲观并发控制
innodb的MVCC,在每行记录后保存2个隐藏列,一个保存行创建时间,一个保存行过期时间(或删除时间).不是具体时间,而是版本号.
每开启事务,系统版本号都会自动递增.事务开始时刻的系统版本号会作为事务的版本号.用来和查询到的每行记录的版本号进行对比.

MVCC只在REPEATABLE READ和READ COMMITED2个隔离级别下工作.
存储引擎
创表,会在数据库子目录下创建和表同名的.frm文件保存表的定义
show table status显示表信息
查询路径

mysql客户端服务端通讯协议
半双工.发送和接收不能同一时刻进行.
另一端接受完整消息,才能响应.