利用训练好的参数模型对图片进行分类
import numpy as np
deploy=root + 'examples/myMnist/lenet.prototxt' #deploy文件
img=root+'examples/image/img_1.jpg' #随机找的一张待测图片
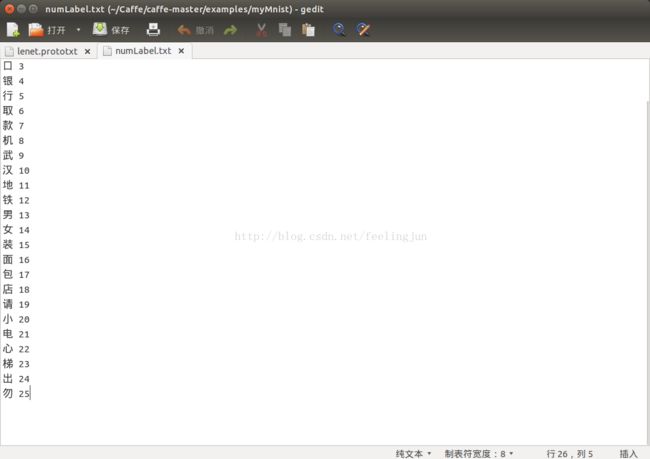
labels_filename = root + 'examples/myMnist/numLabel.txt' #类别名称文件,将数字标签转换回类别名称
net = caffe.Net(deploy,caffe_model,caffe.TEST) #加载model和network
transformer = caffe.io.Transformer({'data': net.blobs['data'].data.shape}) #设定图片的shape格式(1,3,28,28)
transformer.set_transpose('data', (2,0,1)) #改变维度的顺序,由原始图片(28,28,3)变为(3,28,28)
#transformer.set_mean('data', np.load(mean_file).mean(1).mean(1)) #减去均值,前面训练模型时没有减均值,这儿就不用
transformer.set_raw_scale('data', 255) # 缩放到【0,255】之间
transformer.set_channel_swap('data', (2,1,0)) #交换通道,将图片由RGB变为BGR
im=caffe.io.load_image(img) #加载图片
net.blobs['data'].data[...] = transformer.preprocess('data',im) #执行上面设置的图片预处理操作,并将图片载入到blob中
#执行测试
out = net.forward()
labels = np.loadtxt(labels_filename, str, delimiter='\t') #读取类别名称文件
prob= net.blobs['prob'].data[0].flatten()
print prob
order=prob.argsort()[-1] #将概率值排序,取出最大值所在的序号
print 'the class is:',labels[order]
输出结果: