深度学习系列5:卷积神经网络(CNN),图像识别的利器
引言
近年来,图像识别和人脸识别已经逐步进入我们的生活。今天我们就来聊聊图像识别的技术–卷积神经网络(CNN)
一、图像识别
图像识别是指让计算机通过学习识别出图像的内容或者内容所属种类,比如识别图像中有没有汽车,识别图像中的人是谁等等。

1.1 图像的计算机表示
图像是通过一个个像素组成的,图像有宽和高,比如宽度 200 像素,高度 100 像素。
每个像素都有颜色,如果是灰色图像,只需要描述其灰色深度即可,比如 233,我们说用一个通道来表示。
如果是彩色图像,一般用 RGB 三元组颜色,也就是每个像素的颜色表述为 R,G,B 三种不同的深度,比如 {R: 100, G: 200, B: 80},我们说需要三个通道来表示。
所以表示一张图像需要三个信息:
- 宽:W
- 高:H
- 通道:C
通道的理解:彩色图像可以想象成三张同样宽和高但颜色分别为 R,G,B 的图像的层叠,所以通道是 3,而灰度图像只需要一个灰度通道。
1.2 图像识别的难点
我们已经学过深度神经网络(DNN), 那是否可以用深度神经网络识别图像呢?理论上是可以的,但是运算速度慢,效果不太理想,主要是图像识别有一些难点。
- 难点一:数据维度过多,内存压力大
- 一张宽和高都是 64 个像素的小图像维度数:64*64*3 = 12288
- 一张宽和高都是 1000 个像素的小图像维度数:1000*1000*3 = 3000000
- 如果隐藏层有 1000 个节点,那么 W 矩阵的维度就是(1000, 3000000)
- 要学习的参数太多,计算机内存压力太大
- 难点二:如何快速识别图像描述的特征
- 人眼看图像可以很容易看到图像内容的线条、轮廓并过滤无关信息
- 如何让计算机有目的的识别线条和轮廓并过滤无关信息
二、卷积神经网络
面对图像识别的困难, 科学家们经过不懈努力。研究出了有效解决图像识别这两个难点的算法–卷积神经网络(CNN)
卷积神经网络的核心有个:卷积 和 池化。
其中卷积解决识别线条、轮廓和局部特征的问题,池化解决图像维度过多的问题。
2.1 卷积:识别图像局部特征
卷积运算是将图像通过卷积核运算识别出另一张图像的过程。
卷积层可以有目的的学习线条、轮廓和局部特征, 解决难题二。
2.1.1 卷积核与卷积运算

- 卷积核(kernal): 一个 (f*f) 的矩阵,又称为过滤器(filter)
- 卷积核的计算:卷积核每次覆盖图像的一个区域,对应元素相乘再加和作为输出,卷积核依次遍历图像的每个区域生成的输出组成一张新的图像
如果原图像大小为 (n, n), 卷积核大小为 (f, f), 则卷积后图像大小为 (n-f+1, n-f+1)
( n , n ) ∗ ( f , f ) = ( n − f + 1 , n − f + 1 ) (n,n) * (f,f) = (n-f+1,n-f+1) (n,n)∗(f,f)=(n−f+1,n−f+1)
2.1.2 Padding
我们发现,卷积之后图像变小了,如果想保持图像不变,可以像下图那样在原始图像周围填充 0,每侧扩充 p = f − 1 2 p = \frac{f-1}{2} p=2f−1 个像素,可以使图像大小保持不变。
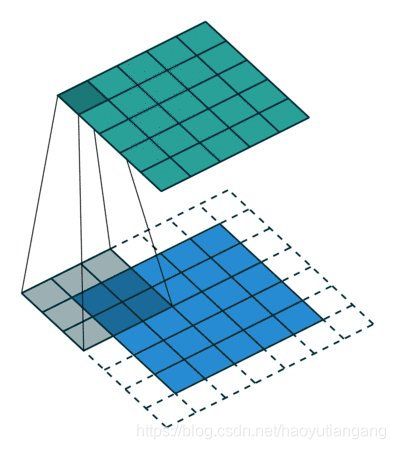
Padiing 的两种方式
- Valid: 没有 Padding
- ( n , n ) ∗ ( f , f ) = ( n − f + 1 , n − f + 1 ) (n,n) * (f,f) = (n-f+1,n-f+1) (n,n)∗(f,f)=(n−f+1,n−f+1)
- Same: 保持图像大小不变的 Padding
- ( n , n ) ∗ ( f , f ) = ( n + 2 p − f + 1 , n + 2 p − f + 1 ) (n,n) * (f,f) = (n+2p-f+1,n+2p-f+1) (n,n)∗(f,f)=(n+2p−f+1,n+2p−f+1)
- 由于图像大小不变: n + 2 p − f + 1 = n n+2p-f+1 = n n+2p−f+1=n, 所以 p = f − 1 2 p = \frac{f-1}{2} p=2f−1
其中
- n: 原始图像的宽/高
- f: filter 的宽/高
- p: 每侧填充的大小
2.1.3 Stride
卷积运算中,还可以对遍历的步长进行限制,默认每次走一个像素,可以设置为每次走 s 个像素。
下图中 s = 2。

当 (n,n) 的图像用 (f,f) 的卷积核,Padding 为 p, Stride 为 s 的情况下,新图像的大小为
( ⌊ n + 2 p − f s + 1 ⌋ , ⌊ n + 2 p − f s + 1 ⌋ ) (\lfloor \frac{n+2p-f}{s}+1 \rfloor,\lfloor \frac{n+2p-f}{s}+1\rfloor) (⌊sn+2p−f+1⌋,⌊sn+2p−f+1⌋)
卷积核窗口落在图像外面时,不再进行操作,所以最终维度向下取整。
2.1.4 立体卷积核
卷积核可以是立体的,对于彩色图像,有 RGB 三个通道,此时卷积核也需要有三个通道,也就是说卷积核是个 (f,f,3) 的立体卷积核,求和时立体对应部分加和即可。
如果原图像有 c 个通道,则卷积核为 (f,f,c), 始终与原图像通道数保持一致。
立体卷积核每次覆盖 (f,f,c) 后输出一个值,按照宽和高进行遍历后的新图像仍然只有一个通道。
2.1.5 多核卷积
由于不论是平面卷积核还是立体卷积核,计算输出的图像都只有一个通道,如果想要生成多个通道的图像,可以使用多个维度相同的卷积核,然后把每个卷积核的输出层叠起来,构成多个通道的输出图像。
一个卷积核输出一个通道,多个卷积核输出层叠可以得到多个通道
如果之前有 c 个通道,想要输出 c’ 个通道,可以使用 c’个立体卷积核。
( n , n , c ) ∗ ( f , f , c ) = ( n + f − 1 , n + f − 1 , c ′ ) (n,n,c) * (f,f,c) = (n+f-1,n+f-1,c') (n,n,c)∗(f,f,c)=(n+f−1,n+f−1,c′)
2.1.6 卷积层的激活函数
之前我们深度学习中: Z = W X + b Z = WX+b Z=WX+b, A = r e l u ( Z ) A = relu(Z) A=relu(Z)
在卷积层中,卷积核 (f,f) 相当于 W W W, 只是此时 WX 变成每一个卷积区域的乘积再加和。
在卷积层中也有激活函数,通常也是 relu。
2.2 池化:图像降维
池化通过把图像一个小区域 (f,f) 的像素综合成一个像素来达到降维的目的。
池化层可以迅速减少图像的维度,解决难题一。
2.2.1 池化层的超参数
池化的超参数:和卷积一样
- f: filter
- s: stride
- p: padding,几乎很少使用 Padding
2.2.2 池化层的种类
常用的池化方式有两种:MAX, AVG。
- MAX: 输出区域内像素最大值
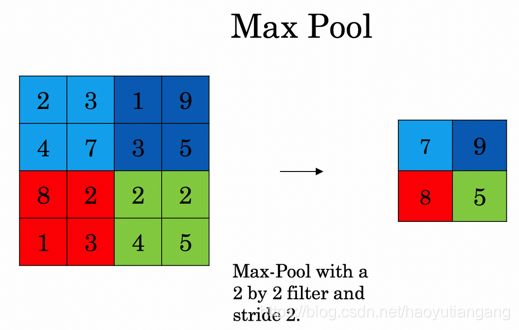
- AVG: 输出区域内像素平均值

池化层每个通道单独池化,没有立体池化,也就是输出图像的通道数和原始图像通道数一致。
池化层只是一个静态层,没有激活函数,也不需要学习。
2.3 完整的卷积神经网络
完整的卷积神经网络通常先通过几个卷积层(conv) 和池化层(pool) 处理,然后再由几个全连接层(fc) 进行处理。
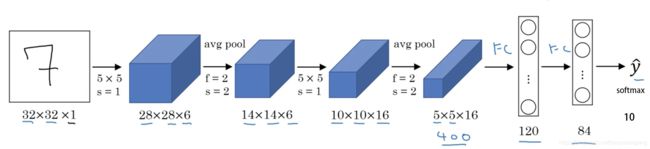
后记
卷积神经网络(CNN) 先聊到这里。工作中一般很少手写卷积神经网络的反向传播,因为稍微有些复杂,不过我还是想和大家一起聊一下,毕竟理解了终归是好的,我们下次见。
欢迎关注本人公众号《大数据茶馆》,用大白话畅聊大数据。
来的都是客,欢迎您常来坐坐~
