小白学习机器学习---第七章:贝叶斯分类器
1.贝叶斯决策论(Bayesian decision theory)
贝叶斯决策论是概率框架下实施决策的基本方法。对分类任务来说,在所有相关概率都已知的理想情形下,它考虑如何基于这些概率和误判损失来选择最优的类别标记。
如:设有N种可能的标记,即Y=C1,C2,……Cn,则基于后验概率P(Ci|X)可获得将样本X分类为Ci所产生的期望损失(expected loss)也称为样本X上的"条件风险"(Conditional risk):

其中λ ij是将一个真实标记为Cj标记成为Ci产生的损失。
我们的目的是寻找一个方法使得条件风险最小化。为最小化总体风险,只需要在每个样本上选择哪个能使得条件风险R(C|X)最小化的类别标记,即:

此时,h*称为贝叶斯最优分类器(Bayes optimal classifier ),与之对应的总体风险R(h*)称为贝叶斯风险(Bayes risk).这就是贝叶斯判定准则(Bayes Decision Rule)
若目标是最小化分类错误率,则误判损失λ ij可写为:

此时条件风险为:

所以,最小化分类错误率的贝叶斯最优分类器为:
![]() (1.11)
(1.11)
也就是对每个样本,选择能使后验概率P(c|X)最大的类别标记。
通常情况下P(c|X)很难直接获得,根据我们已知的条件概率知识对(1)公式进行化简得:
 (1.2)
(1.2)
其中P(c)为先验概率,P(X|c)为样本x关于类别c的条件概率。这就是后验概率最大化准则。
这样一来,根据期望风险最小化原则就可以得到后验概率最大化准则。
某些情况下,可假定Y中每个假设有相同的先验概率,这样(1.2)式就可以进一步简化如下: (1.3)
(1.3)
综合以上讨论,当前求最小化分类错误率的问题转化成了求解先验概率P(c)和条件概率(也称似然概率)P(x|c)P(x|c)的估计问题。对于先验概率P(c)表达了样本空间中各类样本所占的比例,根据大数定理,当训练集包含充足的独立同分布样本时,P(c)可以通过各类样本出现的频率进行估计。整个问题就变成了求解条件概率P(x|c)
2. 极大似然估计
极大似然轨迹源自于频率学派,他们认为参数虽然未知,但却是客观存在的规定值,因此,可以通过优化似然函数等准则确定参数数值。本节使用极大似然估计对条件概率进行估计。
令DcDc表示训练集D中第c类样本组成的集合,假设这些样本是独立同分布的,则参数θθ(θθ是唯一确定条件概率P(x|c)P(x|c)的参数向量)对数据集DcDc的似然函数是
对2.1求对数似然函数
因此求得 θθ 的极大似然估计 θ̂ θ^ 为
使用极大似然估计方法估计参数虽然简单,但是其结果的准确性严重依赖于每个问题所假设的概率分布形式是否符合潜在的真实数据分布,可能会产生误导性的结果
3. 朴素贝叶斯分类器
从前面的介绍可知,使用贝叶斯公式来估计后验概率最大的困难是难以从现有的训练样本中准确的估计出条件概率P(x|c)P(x|c)的概率分布。朴素贝叶斯分类器为了避开这个障碍,朴素贝叶斯方法对条件概率分布作了条件独立性的假设。具体地,条件独立性假设是
公式3.2就是著名的朴素贝叶斯的表达式。
下面对先验概率P(c)和条件概率 P(xi|c)P(xi|c) 进行极大似然估计求得后验概率。
令 DcDc 表示训练集D中第c类样本组成的集合,先验概率的似然估计为
对于离散属性而言,令 Dc,xiDc,xi 表示 DcDc 中在第i个属性上取值为 xixi 的样本组成的集合,则条件概率 P(x|c)P(x|c) 的似然估计为
而对于连续属性需要考虑其密度函数,假定服从正太分布,则计算出均值与方差,带入求解概率即可。
朴素贝叶斯分类算法主要分成如下三步:
- 计算先验概率P(c)和条件概率P(x|c)
- 计算后验概率P(c|x)=P(c)∏di=1P(xi|c)P(c|x)=P(c)∏i=1dP(xi|c)
- 确定实例x的类h∗(x)=argmaxc∈YP(c)∏di=1P(xi|c)h∗(x)=argmaxc∈YP(c)∏i=1dP(xi|c)
拉普拉斯平滑:使用极大似然估计可能会出现所要估计的概率值为0的情况,这样会影响到后验概率的结果,最终使得推荐分类产生偏差。使用贝叶斯估计而已解决这一问题。具体地,条件概率的贝叶斯估计是
当 λ=1λ=1 时称为拉普拉斯平滑(Laplace smoothing)。
同样先验概率的贝叶斯轨迹为
显然,拉普拉斯平滑修正了因训练集样本不充分造成的概率为0的问题,并且在训练集变大时,估计值也逐渐趋向于实际的概率值。
如果有些迷糊,让我们从一个例子开始讲起,你会看到贝叶斯分类器很好懂,一点都不难。
某个医院早上来了六个门诊的病人,他们的情况如下表所示:
| 症状 | 职业 | 疾病 |
|---|---|---|
| 打喷嚏 | 护士 | 感冒 |
| 打喷嚏 | 农夫 | 过敏 |
| 头痛 | 建筑工人 | 脑震荡 |
| 头痛 | 建筑工人 | 感冒 |
| 打喷嚏 | 教师 | 感冒 |
| 头痛 | 教师 | 脑震荡 |
现在又来了第七个病人,是一个打喷嚏的建筑工人。请问他患上感冒的概率有多大?
根据贝叶斯定理:

可得:

根据朴素贝叶斯条件独立性的假设可知,”打喷嚏”和”建筑工人”这两个特征是独立的,因此,上面的等式就变成了

这里可以计算:
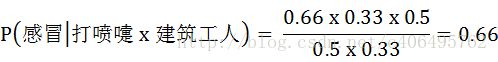
因此,这个打喷嚏的建筑工人,有66%的概率是得了感冒。同理,可以计算这个病人患上过敏或脑震荡的概率。比较这几个概率,就可以知道他最可能得什么病。
这就是贝叶斯分类器的基本方法:在统计资料的基础上,依据某些特征,计算各个类别的概率,从而实现分类。
同样,在编程的时候,如果不需要求出所属类别的具体概率,P(打喷嚏) = 0.5和P(建筑工人) = 0.33的概率是可以不用求的。