CVPR2020-HRank:Filter Pruning using High-Rank Feature Map
1. 介绍
滤波器修剪的核心在于滤波器的选择,滤波器的选择应以最高的压缩比和最低的精度折衷。基于过滤器评价函数的设计,作者根据经验将过滤器剪枝分为两种大类。
属性的重要性(Property Importance):基于CNNs的固有属性对滤波器进行修剪。这些修剪方法不会弥补网络训练损失。剪枝后,通过微调提高模型性能。在这些方法中:
Network trimming: A data-driven neuron pruning approach towards efficient deep architectures利用大型网络中输出的稀疏性,去除零激活率较高的滤波器(APOZ方法)。Pruning filters for efficient convnets.基于“1-范数”的剪枝,假设具有较小范数的参数或特征信息量较少,因此应首先剪枝。Pruning convolutional neural networks for resource efficient inference提出考虑了一阶梯度来评价滤波器的重要性,去掉了最不重要的滤波器。Nisp: Pruning networks using neuron importance score propagation对最终响应的重要性评分被传播到网络中的每个过滤器,并通过删除重要性最低的一个来修剪CNNs。Filter pruning via geometric median for deep convolutional neural networks acceleration.计算图层中的几何中值,并修剪最接近该中值的过滤器。
大多数滤波器评价函数的设计都是自设计的,这带来了时间复杂度低的优点,但也限制了加速比和压缩比。
适应性属性:方法将剪枝要求嵌入到网络训练损失中,通过联合再训练优化生成自适应剪枝决策。
Learning efficient convolutional networks through network slimming.和Variational convolutional neural network pruning.对BN层的尺度因子施加了稀疏约束,使得具有较低尺度因子的通道被认为是不重要的。Data-driven sparse structure selection for deep neural networks.和Towards optimal structured cnn pruning via generative adversarial learning引入了新的比例因子参数(也称为掩码)来学习稀疏结构修剪,其中删除了与比例因子为零对应的过滤器。
与基于属性重要性的滤波剪枝方法相比,基于自适应重要性的方法由于其联合优化,通常可以获得更好的压缩和加速效果。然而,由于损失发生了变化,所需的再培训步骤在机器时间和人力上都很繁重,通常需要另一轮超参数调整。
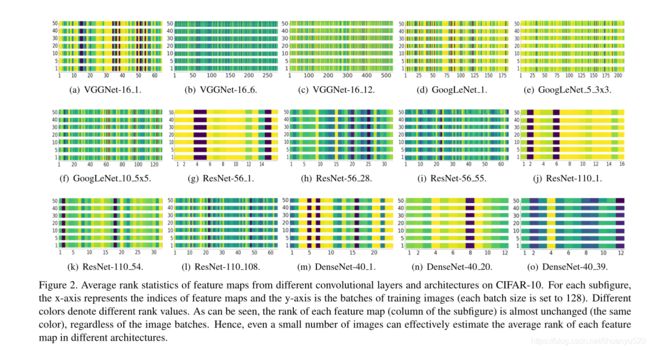
在这个论文中,提出了一种有效且高效的滤波器剪枝方法,该方法探索每一层特征图的高矩阵秩(HRank)。它是一种基于属性的修剪方法(不用重重新训练,简化了剪枝的复杂性)。作者通过观察发现,无论CNN看到多少数据,单个过滤器生成的feature map的平均秩总是相同的。这表明,只使用输入图像的一小部分就可以准确地估计深度cnn中特征图的秩,从而达到高效的目的。基于这一思想,用数学方法证明了秩越低的特征映射对精度的贡献越小。因此,可以首先删除生成这些特征映射的过滤器。
作者使用VGGNet、GoogLeNet、ResNet和DenseNet等许多具有代表性的大型CNN模型,在CIFAR-10和ImageNet这两个基准测试上进行了广泛的实验。结果表明HRank的性能优于现有的过滤剪枝方法,包括基于属性重要性的方法和最新的基于自适应重要性的模型。实验还表明,即使在剪枝后的微调过程中冻结了一部分高阶特征映射的滤波器,模型仍然保持了较高的精度,验证了我们的假设。
贡献有:
- 在大量统计验证的基础上,证明了单个滤波器生成的特征图的平均秩几乎没有变化。
- 从数学上证明,具有较低秩特征图的过滤器信息量较小,因此对保持准确性不太重要,可以首先删除这些准确性。
- 广泛的实验证明了HRank模型压缩和加速在各种最新技术状态下的效率和效果。
2. 方法
一个预先训练的模型有K层, C i C^i Ci是第 i i i个卷积层,滤波器可以用 W C i = { w 1 i , w 2 i , … , w n i } ∈ R n i × n i − 1 × k i × k i \mathcal{W}_{\mathcal{C}^{i}}=\left\{\mathbf{w}_{1}^{i}, \mathbf{w}_{2}^{i}, \ldots, \mathbf{w}_{n}^{i}\right\} \in \mathbb{R}^{n_{i} \times n_{i-1} \times k_{i} \times k_{i}} WCi={w1i,w2i,…,wni}∈Rni×ni−1×ki×ki表示,其中第 j j j个滤波器为 w j i ∈ R n i − 1 × k i × k i \mathbf{w}_{j}^{i} \in \mathbb{R}^{n_{i-1} \times k_{i} \times k_{i}} wji∈Rni−1×ki×ki。对于特征图我们定义为 O i = { o 1 i , o 2 i , … , o n i i } ∈ R n i × g × h i × w i \mathcal{O}^{i}=\left\{\mathbf{o}_{1}^{i}, \mathbf{o}_{2}^{i}, \ldots, \mathbf{o}_{n_{i}}^{i}\right\} \in \mathbb{R}^{n_{i} \times g \times h_{i} \times w_{i}} Oi={o1i,o2i,…,onii}∈Rni×g×hi×wi,其中第 j j j个特征图 o j i ∈ R g × h i × w i \mathbf{o}_{j}^{i} \in \mathbb{R}^{g \times h_{i} \times w_{i}} oji∈Rg×hi×wi是由 w j i \mathbf{w}_{j}^{i} wji生成。g是特征图的大小, h i h_i hi和 w i w_i wi是特征图的高和宽。过滤器的剪枝可以将分为 W C i \mathcal{W}_{C^{i}} WCi分为两组,保留的子集 I C i = { w I 1 i i , w I 2 i i , … , w I n i 1 i i } \mathcal{I}_{\mathcal{C}^{i}}=\left\{\mathbf{w}_{\mathcal{I}_{1}^{i}}^{i}, \mathbf{w}_{\mathcal{I}_{2}^{i}}^{i}, \ldots, \mathbf{w}_{\mathcal{I}_{n_{i} 1}^{i}}^{i}\right\} ICi={wI1ii,wI2ii,…,wIni1ii}和一个不重要将要被裁剪的子集 U C i = { w U 1 i i , w U 2 i i , … , w U n i i i } \mathcal{U}_{\mathcal{C}^{i}}=\left\{\mathbf{w}_{\mathcal{U}_{1}^{i}}^{i}, \mathbf{w}_{\mathcal{U}_{2}^{i}}^{i}, \ldots, \mathbf{w}_{\mathcal{U}_{n i}^{i}}^{i}\right\} UCi={wU1ii,wU2ii,…,wUniii},其中 I j i \mathcal{I}_{j}^{i} Iji and U j i \mathcal{U}_{j}^{i} Uji分别是第 j j j个重要的过滤器个不重要的过滤器。 n i 1 n_{i 1} ni1 and n i 2 n_{i 2} ni2是重要和不重要滤波器的数量,于是有: I C i ∩ U C i = ∅ , I C i ∪ U C i = W C i \mathcal{I}_{\mathcal{C}^{i}} \cap \mathcal{U}_{\mathcal{C}^{i}}=\varnothing, \mathcal{I}_{\mathcal{C}^{i}} \cup \mathcal{U}_{\mathcal{C}^{i}}=\mathcal{W}_{\mathcal{C}^{i}} ICi∩UCi=∅,ICi∪UCi=WCi and n i 1 + n i 2 = n i n_{i 1}+n_{i 2}=n_{i} ni1+ni2=ni。
滤波器修剪的目的是找到不重要的滤波器并删除他们,这可以表示为一个优化问题。
min δ i j ∑ i = 1 K ∑ j = 1 n i δ i j L ( w j i ) s.t. ∑ j = 1 n i δ i j = n i 2 \begin{array}{l} \min _{\delta_{i j}} \sum_{i=1}^{K} \sum_{j=1}^{n_{i}} \delta_{i j} \mathcal{L}\left(\mathbf{w}_{j}^{i}\right) \\ \text { s.t. } \sum_{j=1}^{n_{i}} \delta_{i j}=n_{i 2} \end{array} minδij∑i=1K∑j=1niδijL(wji) s.t. ∑j=1niδij=ni2
其中 δ i j \delta_{i j} δij,如果 w j i \mathbf{w}_{j}^{i} wji被分组到 U C i \mathcal{U}_{C^{i}} UCi,则 δ i j \delta_{i j} δij是指示符1,或者如果 w j i \mathbf{w}_{j}^{i} wji被分组到 I C i \mathcal{I}_{C^{i}} ICi,则为0。L(·)衡量过滤输入对CNN的重要性。因此,最小化上公式等于移除 C i C^i Ci中的 n i 2 n_{i 2} ni2个最不重要的滤波器。
作者认为, L L L在滤波器上的特别设计忽略了输入图像和输出标签的分布,这可能是基于属性重要性的方法表现出次优性能的原因。相反,在本文中,作者建议在特征映射上定义 L L L。其基本原理在于,特征映射是既能反映滤波器属性又能反映输入图像的中间步骤,所以
min δ i j ∑ i = 1 K ∑ j = 1 n i δ i j E I ∼ P ( I ) [ L ^ ( o j i ( I , : , : ) ) ] s.t. ∑ j = 1 n i δ i j = n i 2 \begin{array}{c} \min _{\delta_{i j}} \sum_{i=1}^{K} \sum_{j=1}^{n_{i}} \delta_{i j} \mathbb{E}_{I \sim P(I)}\left[\hat{\mathcal{L}}\left(\mathbf{o}_{j}^{i}(I,:,:)\right)\right] \\ \text { s.t. } \sum_{j=1}^{n_{i}} \delta_{i j}=n_{i 2} \end{array} minδij∑i=1K∑j=1niδijEI∼P(I)[L^(oji(I,:,:))] s.t. ∑j=1niδij=ni2
其中 L ^ ( ⋅ ) \hat{\mathcal{L}}(\cdot) L^(⋅)用于评估由 w j i \mathbf{w}_{j}^{i} wji生成的特征图 o j i ( I , : , : ) \mathbf{o}_{j}^{i}(I,:,:) oji(I,:,:)信息。特征图包含的信息越多,相应的滤波器就也越重要。作者利用了特征图的秩,它不仅被证明是一种有效的信息度量,而且在P(I)上也是一种稳定的表示。首先将我们的信息度量定义为:
L ^ ( o j i ( I , : , : ) ) = R ank ( o j i ( I , : , ; ) ) \hat{L}\left(\mathbf{o}_{j}^{i}(I,:,:)\right)=\mathbf{R} \operatorname{ank}\left(\mathbf{o}_{j}^{i}(I,:, ;)\right) L^(oji(I,:,:))=Rank(oji(I,:,;))
其中其中 R a n k ( ⋅ ) Rank(·) Rank(⋅)是输入图像 I I I的featre map的秩。我们对 o j i ( I , : , : ) \mathbf{o}_{j}^{i}(I,:,:) oji(I,:,:)进行奇异值分解(SVD):
o j i ( I , : , : ) = ∑ i = 1 r σ i u i v i T = ∑ i = 1 r ′ σ i u i v i T + ∑ i = r ′ + 1 r σ i u i v i T \begin{aligned} \mathbf{o}_{j}^{i}(I,:,:) &=\sum_{i=1}^{r} \sigma_{i} \mathbf{u}_{i} \mathbf{v}_{i}^{T} =\sum_{i=1}^{r^{\prime}} \sigma_{i} \mathbf{u}_{i} \mathbf{v}_{i}^{T}+\sum_{i=r^{\prime}+1}^{r} \sigma_{i} \mathbf{u}_{i} \mathbf{v}_{i}^{T} \end{aligned} oji(I,:,:)=i=1∑rσiuiviT=i=1∑r′σiuiviT+i=r′+1∑rσiuiviT
在其中 r = Rank ( o j i ( I , : , ; ) ) r=\operatorname{Rank}\left(\mathbf{o}_{j}^{i}(I,:, ;)\right) r=Rank(oji(I,:,;)), r ′ r' r′< r r r,它可以看做将一个秩为 r r r的feature map可以分解为一个低秩( r ′ r' r′)的特征图,即 ∑ i = 1 r ′ σ i u i v i T \sum_{i=1}^{r^{\prime}} \sigma_{i} \mathbf{u}_{i} \mathbf{v}_{i}^{T} ∑i=1r′σiuiviT;和一些额外的信息,即 ∑ i = r ′ + 1 r σ i u i v i T \sum_{i=r^{\prime}+1}^{r} \sigma_{i} \mathbf{u}_{i} \mathbf{v}_{i}^{T} ∑i=r′+1rσiuiviT,因此High-rank的特征图比Low-rank的特征图包含由更多的信息,因此rank可以作为信息丰富的度量。
使用小批量的输入图像来精确地估计特征图秩的期望
E I ∼ P ( I ) [ L ^ ( o j i ( I , : , : ) ) ] ≈ ∑ t = 1 g R ank ( o j i ( t , : ; ; ) ) \mathbb{E}_{I \sim P(I)}\left[\hat{\mathcal{L}}\left(\mathbf{o}_{j}^{i}(I,:,:)\right)\right] \approx \sum_{t=1}^{g} \mathbf{R} \operatorname{ank}\left(\mathbf{o}_{j}^{i}(t,: ; ;)\right) EI∼P(I)[L^(oji(I,:,:))]≈t=1∑gRank(oji(t,:;;))
最终:
min δ i j ∑ i = 1 K ∑ j = 1 n i δ i j ( w j i ) ∑ t = 1 g R ank ( o j i ( t , : , : ) ) s . t . ∑ j = 1 n i δ i j = n i 2 \begin{array}{c} \min _{\delta_{i j}} \sum_{i=1}^{K} \sum_{j=1}^{n_{i}} \delta_{i j}\left(\mathbf{w}_{j}^{i}\right) \sum_{t=1}^{g} \mathbf{R} \operatorname{ank}\left(\mathbf{o}_{j}^{i}(t,:,:)\right) \\ s . t . \sum_{j=1}^{n_{i}} \delta_{i j}=n_{i 2} \end{array} minδij∑i=1K∑j=1niδij(wji)∑t=1gRank(oji(t,:,:))s.t.∑j=1niδij=ni2
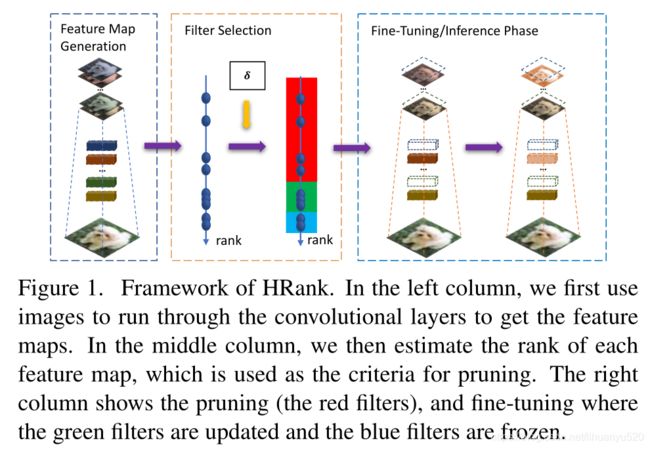
剪枝
举例说明输出的特征图为 32 ∗ 128 ∗ 128 32*128*128 32∗128∗128,滤波器为 32 ∗ 16 ∗ 3 ∗ 3 32*16*3*3 32∗16∗3∗3
- 我们计算16个通道对应特征图秩,并进行从大到小排序。
- 我们决定要保存的滤波器个数 a a a和不重要的的滤波器个数 b b b, a + b = 32 a+b=32 a+b=32
- 然后我们通过索引值删除不重要的过滤器。
- 最终我们在对网络进行微调。
实验
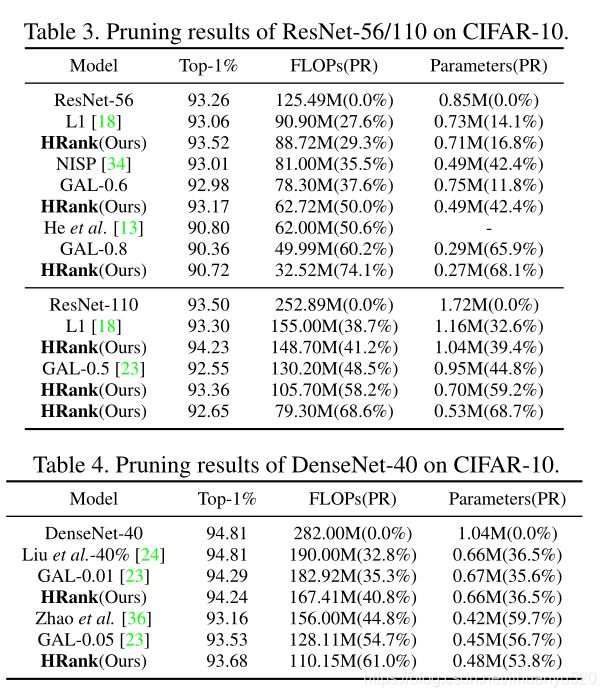
文章在小数据集和大数据集上进行了实验,即CIFAR-10和ImageNet。研究了不同算法在主流CNN模型上的性能,包括VGGNet、GoogLeNet、ResNet和DenseNet。对于所有基准和架构,随机抽样500张图像来估计每个特征图的平均秩。我们将以参数数量和所需浮点运算(表示为FLOP),评估模型大小和计算要求。


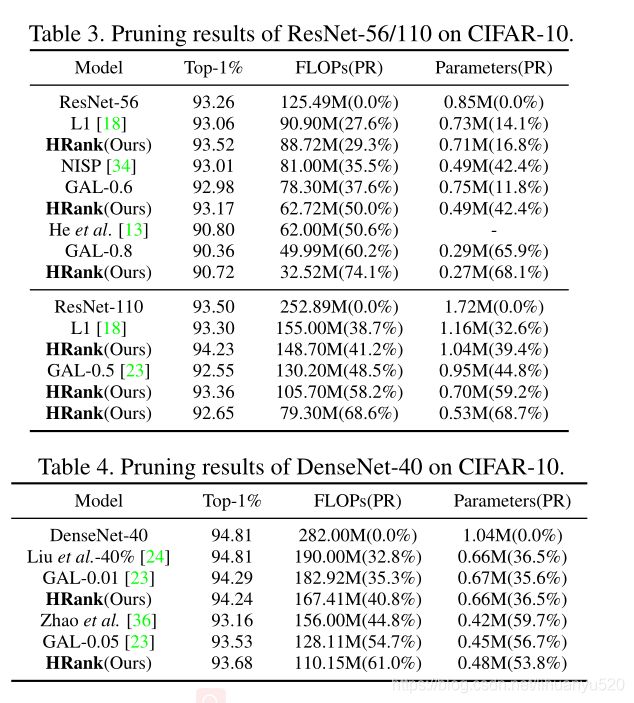
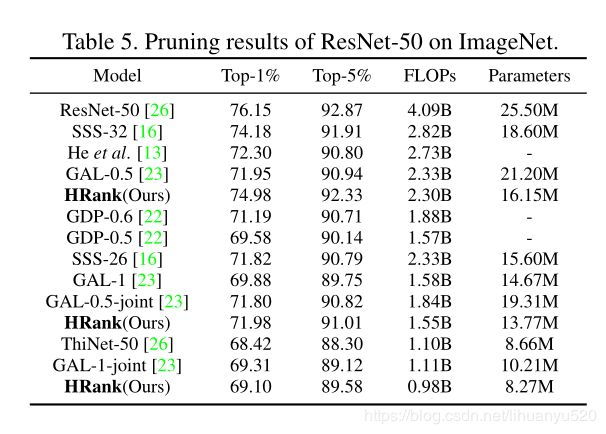
Ablation study 消融实验
为了说明所提方案的合理性,作者又做了Ablation study。
**Variants of HRank.**为了证明high-rank特征图滤波器保存的适当性,提出了三种变体,包括:
- Edge:生成的high-rank和low-rank特征图的滤波器同时被修剪。
- Random:滤波器随意被修剪。
- Reverse:只修剪生成low-rank特征图的滤波器
: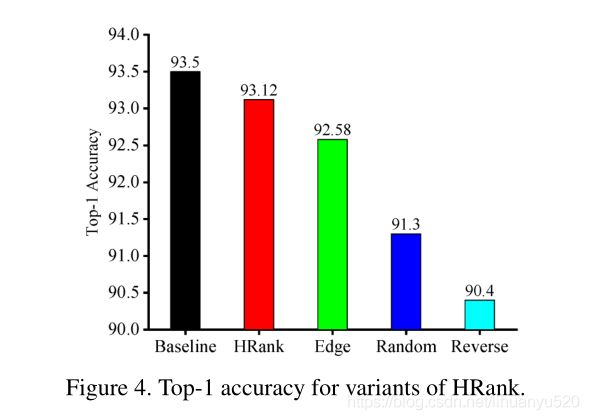
实验结果表明:low-rank特征映射包含的信息量较少,相应的滤波器可以安全地去除。
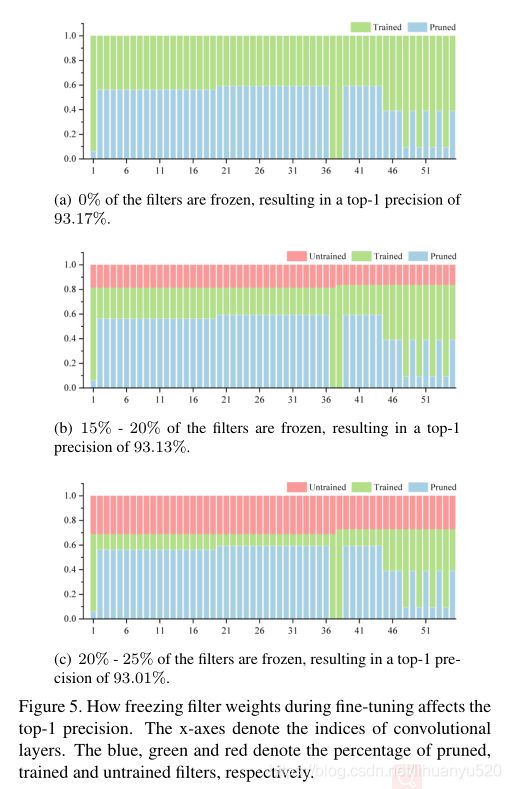
Freezing Filters during Fine-tuning 实验表明:不用High-rank特征映射更新滤波器对模型性能的影响不大。