从零开始java数据权限篇:数据权限
目录
一:数据权限的产生
二:数据权限的数据切割
1.数据对应的层级图
2.用户数据查询
3.用户流程管理
4.部门-岗位-公司查询拓扑图
三.说明
一:数据权限的产生
在一个后管系统中,由2个最重要的权限划分。第一个访问权限,通过控制访问路径、请求来控制访问的权限,第二个是数据权限,通过一系列的分割策略来对用户进行管理。
访问权限,可以这么说访问权限可以通过集成框架(比如shiro或者Spring seurity或者oauth2)来控制。所以严格意义上来说访问权限是一个技术框架。
数据权限,数据权限用来对用户信息进行管理包括但是不限于用户列表查询、子母公司数据划分以及工作流等的一系列。但是一个比较尴尬的问题就是,数据权限实则是一个业务层,它是由具体的公司业务来决定的。当然,凡是可以抽象出来的我们都可以抽象出来。目前主流的的数据权限控制以 部门-岗位-上级-本级 这样一个递减结构来做通用式的管理。
也翻看了一些所谓的数据级权限中间件比如目前介绍较多的Ralasafe,实则上就是在访问Sql上做一些侵入式Sql限制。基于此,我们完全可以在项目中使用AOP做。但是很尴尬的是目前这个数据级的中间件已经停止维护。
二:数据权限的数据切割
在上面,我们谈到一般都是以 部门-岗位-上级-本级 的结构来做数据权限控制。但是一般项目中会把上级-本级合并产生一个简单的结构:部门-岗位-用户 来维护数据权限。
1.数据对应的层级图
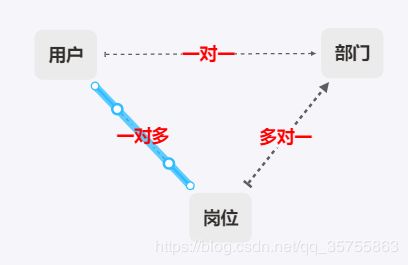
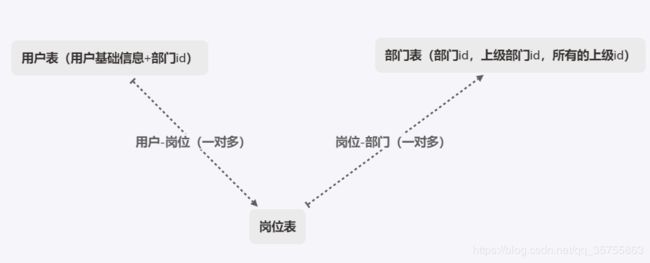
首先:部门对于用户而言,是用户固有的一个属性,只能是一对一关系。
岗位对于用户而言 ,是由上级或者管理员分配的一个属性,可以是一对多(即一个用户被指向多个部门的负责人,但是
他本身只有某一个部门的属性)。
部门对岗位而言,同时也是一对多的关系,即一个部门有多个角色。
2.用户数据查询
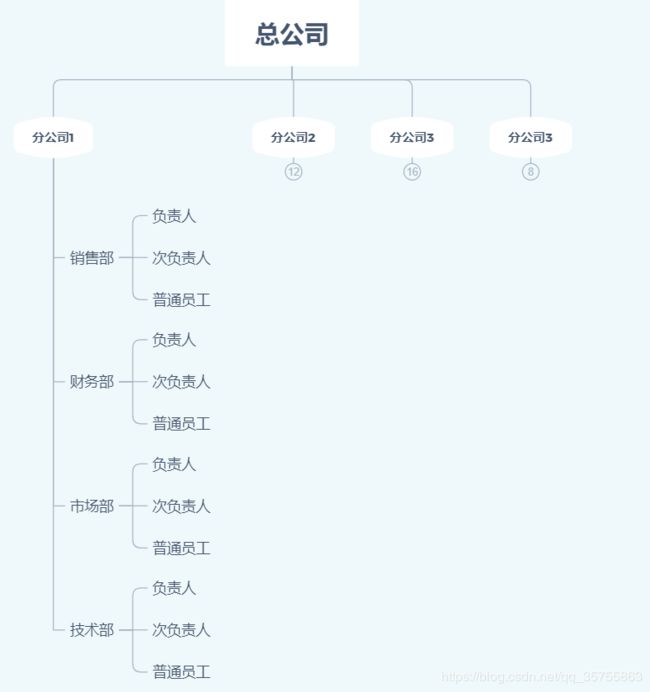
然后,我们针对组织结构细分:
(1)公司结构以及部门结构:管理层级(具有本部门的最高权限)以及一般员工(只有自我查询权限)
其中总公司的管理层具有整个结构的最高权限。
(2)单个单位中的结构:单个单位内的负责人具有最高单位权限
单个单位的次级负责人具有管理名下的权限。(即上级-下级的管理权限)
单个单位内的普通员工只具有自身的权限
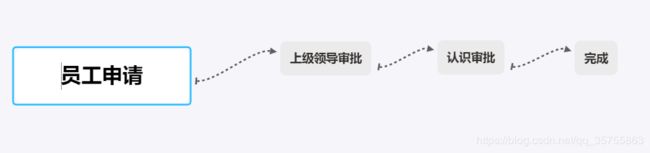
3.用户流程管理
由于后期要整合工作流,因此这里我们将流程梳理清晰。
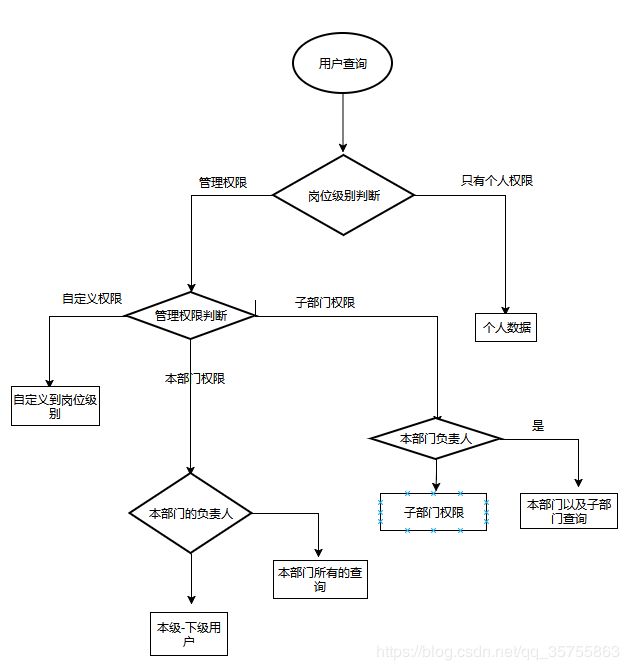
4.部门-岗位-公司查询拓扑图
目前,主要角色分为以下几个:
(1)普通员工(仅能看到自己的信息)
(2)部门管理人(仅能看到本部门)
(3)分公司董事(除了董事会部门的其他分公司所有的部门)
(4)分公司总负责人(看到分公司所有的信息)
(5)总公司董事会(除了总公司董事会之外的所有总,自公司的所有部门)
(6)总董事
部门-岗位-董事表拓扑(比较简单,就不做UML了)
据图查询:
(1)普通员工:这个就不用说了
(2)部门负责人:查询 用户表中 部门id一样的即可
(3)分公司董事会:第一步,根据用户表中的部门id去查询部门表
第二步:根据部门表中的所有上级id,取出公司统一的开头(一般第一位为总公司id,第二位为
分公司id,第三位包括以后是部门层级一级一级玩下的id,以逗号隔开)
第三步:根据公司统一的开头曲模糊查询所有的部门id(这里在程序中控制得当,是完全可以的)
第四步:根据上一步的部门id,同时去掉本身的部门id(即董事会部门的id),然后反查用户表
(4)分公司负责人 :在上一个的第四步,不去掉本身的部门id
(5)总公司董事会:查询所有的,除了自身的部门id
(6)总公司负责人:全查
(7)自定义:选择部门,然后插入 岗位-部门表做联查(对,这个表只在这里用到)
三.说明
上面所描述的是通常情况下,一般都是根据具体业务做管理