NIO和Concurrent
大数据学习历程
- NIO
- IO分类
- BIO的缺点
- NIO的特点
- NIO的缺点
- BIO和NIO的比较
- 3大组件
- Concurrent
- BlockingQueue 阻塞队列
- ArrayBlockingQueue - 阻塞式顺序队列
- LinkedBlockingQueue - 阻塞式链式队列
- PriorityBlockingQueue - 阻塞式优先级队列
- SynchronousQueue - 同步队列
- BlockingDeque - 阻塞式双向队列
- ConcurrentMap - 并发映射
- ConcurrentHashMap - 并发哈希映射
- ConcurrentNavigableMap - 并发导航映射
- ExecutorService - 执行器服务(线程池)
- Callable
- ScheduledExecutorService
- ForkJoinPool 分叉合并的线程池
- Lock
NIO
IO分类
- BIO:BlockingIO,同步式阻塞式IO,即传统的IO,是Java中最早期的流
- NIO:Non-BlockingIO,又称New IO,同步式非阻塞式IO,是JDK1.4提供的流
- AIO:AsynchronousIO,异步式非阻塞式IO,可以认为是NIO的二代版本,是JDK1.8提供的流
BIO的缺点
- 一对一的连接方式:即每一个连接请求需要对应一个线程,在请求量大的情况下,会导致服务器端的压力非常大从而致使整个服务器的处理效率变低
- 阻塞:当线程在进行read或者write的时候,除非读完或者写完,否则在这个过程中不能发生任何操作
- 单向传输:数据只能从一端传向另一端,如果需要反向传输需要令创建流对象
NIO的特点
- 一对多的连接方式:利用一个或者少量线程处理大量的连接请求,降低服务器端的压力
- 非阻塞:在线程不能进行read或者write方法的时候,立即返回0,等待下一次操作
- 双向传输:利用通道可以实现数据的双向
NIO的缺点
- 在请求量比较大的情况下会出现部分请求的响应时间比较长的现象
- 不适用于长任务场景,不然会导致其他的请求无法处理
BIO和NIO的比较
| BIO | NIO |
|---|---|
| 同步阻塞 | 同步非阻塞 |
| 单向传输数据 | 可以双向传输数据 |
| 一对一的连接方式 | 一对多的连接方式 |
| 面向流操作 | 面向缓冲区操作 |
| 适合于请求少、长连接场景 | 适合于大量请求、短连接的场景 |
3大组件
a. Buffer - 缓冲区 - 用于存储数据
b. Channel - 通道 - 用于传输数据
c. Selector - 多路复用选择器 - 限流
-
Buffer
- 缓冲区,用于存储数据
- 底层依靠数组来存储数据,并且存储的数据是基本类型,但是其中没有针对boolean类型的缓冲区
- 最常使用的是ByteBuffer,底层依靠的是字节数组
- 重要的位置:capacity >= limit >= position >= mark
a. capacity:容量位。用于标记缓冲区的容量
b. limit:限制位。用于限制操作位所能达到的最大下标,默认和capacity一致
c. position:操作位。用于指向要读写的位置,默认为0
d. mark:标记位。一般用于进行标记,表示之前的数据是无错的。mark默认为-1,表示默认不启用 - 重要操作:
a. flip:翻转缓冲区。将limit挪到position,然后将position归零,并且将mark置为-1
b. clear:清空缓冲区。position归零,limit挪到capacity,mark置为-1
c. reset:重置缓冲区。将position挪到mark上
d. rewind:重绕缓冲区。将position归零,将mark置为-1
e.hasRemaining: 判断position 是否小于 limit
f.get: 获取当前position位字节
g.array: 获取当前buffer中所有字节
-
Channel
- 通道,用于进行数据的传输
- 在传输数据的时候,面向缓冲区进行操作的
- File:FileChannel
UDP:Datagra mChannel
TCP:SocketChannel、ServerSocketChannel - 默认是阻塞的,需要手动设置为非阻塞,设置方法: configureBlocking(false);
- 重要操作:
a. connect:客户端发起连接。参数InetSocketAddress继承了SocketAddress
b. bind:服务端绑定端口。
c. configureBlocking:设置为非阻塞
-
Selector
- 多路复用选择器,针对通道进行选择
- 选择器所针对的通道必须是非阻塞的
- 选择器在进行选择时候,选择通道身上的事件来进行处理
- 重要操作:
a. ServerSocketChannel.register:将通道注册到ServerSocketChannel上,参数:(Selector,SelectionKey.OP_ACCEPT)
b. Selector.select:筛选出有用的请求。
c. selectedKeys:获取请求所对应的事件
Concurrent
JDK1.5出现的专门应对高并发的包
主要包含五个内容
BlockingQueue 阻塞队列
-
概述
- BlockqingQueue是阻塞式队列中的顶级接口,需要使用它的实现之一来使用 BlockingQueue
- BlockingQueue是有指定界限的
- 在队列为空的时候进行获取操作会产生阻塞
- 在队列已满的情况下继续存储元素会产生阻塞
- 遵循先进先出(FIFO)的原则
- 适用于生产消费模型,即一个线程生产对象,而另外一个线程消费这些对象的场景
- 无法向一个 BlockingQueue 中插入 null。如果你试图插入 null,BlockingQueue 将会抛出一个 NullPointerException。
-
重要方法
| 发生情景 | 抛出异常 | 返回特殊值 | 阻塞 | 定时阻塞 |
|---|---|---|---|---|
| 队列已满时,添加 | add(o) | offer(o) | put(o) | offer(o, time, unit) |
| 队列为空时,获取 | remove() | poll() | take() | poll(time, unit) |
| 检索队列头元素 | element() | peek() |
ArrayBlockingQueue - 阻塞式顺序队列
1. 在使用的时候需要指定容量/界限,且容量指定之后不可改变
2. 容量在指定之后不能改动
3. 遵循先进先出(FIFO)的原则
//创建时指定容量为5,队列中最大允许存储5个元素,且使用过程中不允许改变容量界限
ArrayBlockingQueue<String> queue = new ArrayBlockingQueue<>(5);
LinkedBlockingQueue - 阻塞式链式队列
1. 在使用的时候可以指定容量也可以不指定容量
2. 如果不指定容量,则容量默认为Integer.MAX_VALUE -> 2的31次方-1,此时人为认定容量是无限的
3. 如果指定容量,则容量指定之后不可变
4. 底层基于节点(链表)来存储数据
5. 遵循先进先出(FIFO)的原则
PriorityBlockingQueue - 阻塞式优先级队列
1. 在使用的时候可以指定容量也可以不指定
2. 如果不指定容量,则容量默认为11
3. 如果指定容量,则容量指定之后不可改变
4. 在指定容量的时候,最大不能超过Integer.MAX_VALUE-8
5. PriorityBlockingQueue要求存储的元素对应的类必须实现Comparable接口,重写其中的compareTo方法来指定比较规则
6. PriorityBlockingQueue在存储元素的时候会根据指定的比较规则对元素进行排序
7. PriorityBlockingQueue在迭代的时候不保证元素的排序顺序
示例
public class PriorityBlockingQueueDemo {
public static void main(String[] args) throws Exception {
// 创建队列
PriorityBlockingQueue<Student> queue = new PriorityBlockingQueue<>();
// 添加元素
queue.put(new Student("Amy", 16));
queue.put(new Student("Bob", 25));
queue.put(new Student("Cathy", 20));
queue.put(new Student("David", 13));
// 遍历队列
// 需要注意的是,如果想要拿到排序的结果,不能以迭代的方法获取
for (int i = 0; i < 4; i++) {
System.out.println(queue.take());
}
}
}
class Student implements Comparable<Student> {
private String name;
private int age;
public Student(String name, int age) {
super();
this.name = name;
this.age = age;
}
@Override
public String toString() {
return "Student [name=" + name + ", age=" + age + "]";
}
// 在这个方法中指定比较规则
// 根据学生的年龄进行升序排序
@Override
public int compareTo(Student o) {
return this.age - o.age;
}
}
SynchronousQueue - 同步队列
1. 容量默认为1,并且只能为1,因此只能存储1个元素
2. 如果该队列已有一个元素,则试图向队列中新添一个新元素的线程将会阻塞,直到另一个线程将该元素从队列中抽走
3. 如果该队列为空,则试图从队列中抽取一个元素的线程将会阻塞,直到另一个线程向队列中添加了一个新的元素
4. 一般会将同步队列称之为是数据的汇合点
BlockingDeque - 阻塞式双向队列
1. BlockingDeque继承了BlockingQueue
2. 在使用的时候,需要指定容量的
3. 该队列称之为双向队列,即队列的两端都可以添加元素,也可以从队列的两端获取元素
4. 因为双向,所以添加或获取时方法需要添加后缀: addFirst:从头元素添加,addLast:从尾元素添加
ConcurrentMap - 并发映射
- 概述
- 该映射是JDK1.5提供的用于多并发场景下的映射接口
- 该映射的实现类往往是异步式线程安全的 ConcurrentHashMap
ConcurrentHashMap - 并发哈希映射
1. 异步式线程安全的映射
2. 底层是依靠数组+链表结构来存储,数组的默认初始容量是16,默认加载因子是0.75,可指定
3. 采取了分段(桶)锁机制:当不同线程访问不同的桶的时候,这个线程会锁住当前的桶而不是整个映射。在后续版本中,为了提高并发性,在分段锁的基础上,引入了读写锁机制:
a. 读锁:允许多个线程读,不允许写
b. 写锁:只允许一个线程写,不允许读
4. 在JDK1.8中,引入了CAS(Compare And Swap , 比较和交换)无锁算法
==**可参考 作者和大黄-CAS原理分析**==
[https://blog.csdn.net/HEYUTAO007/article/details/19975665](https://blog.csdn.net/HEYUTAO007/article/details/19975665)
5. 从JDK1.8开始,在ConcurrentHashMap/HashMap中引入了红黑树机制。如果当桶中的元素超过8个时候,会将这个链表扭转成一棵红黑树;如果红黑树中的节点个数不足7个,则会将红黑树扭转回链表==>红黑树扭转的前提为桶的个数不少于64,否则扩容
6. 扩展:红黑树
红黑树参考资料-作者:v_JULY_v-教你初步了解红黑树
a. 红黑树本身是一棵自平衡二叉树
b. 红黑树的查询时间复杂度:O(logn)
c. 二叉树的特点:
i. 左子树和右子树都是二叉树
ii. 左子树小于根节点
iii. 右子树大于根据点
d. 红黑树的特点:
i. 所有的节点非红即黑
ii. 根节点必须是黑色
iii. 红节点的子节点必须是黑色,黑节点的子节点可以是红色也可以是黑色
iv. 所有叶子节点都是黑色的空节点
v. 从根节点到任意一个叶子节点所经历的黑节点个数是相同的,即黑色节点高度/深度一致
vi. 如果新添子节点,那么子节点必须是红色
e. 红黑树的修正:
+ 涂色:当前节点为红父节点为红,并且叔父节点为红,将父节点以及叔父节点涂黑,将祖父节点涂红
+ 左旋:当前节点为红父节点为红,并且叔父节点为黑,当前节点是右子叶,以当前节点为轴进行左旋
+ 右旋:当前节点为红父节点为红,并且叔父节点为黑,当前节点是左子叶,以父节点为轴进行右旋

+ 修正案例:

ConcurrentNavigableMap - 并发导航映射
- 提供了截取自映射的方法,如图
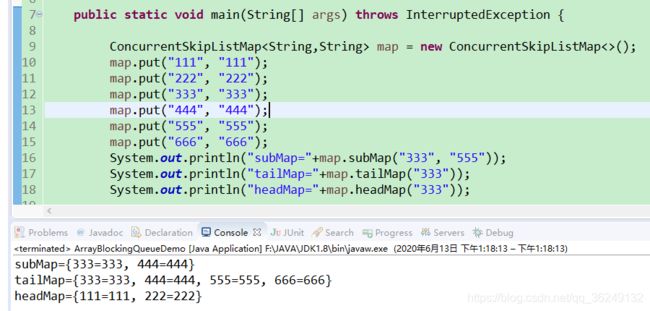
- 常用的实现类是ConcurrentSkipListMap,该实现类是基于跳跃表实现的
参考资料-作者:Single_YAM-基于跳跃表的 ConcurrentSkipListMap 内部实现
ExecutorService - 执行器服务(线程池)
-
概述
- 本质上是一个线程池
- 线程池定义的目的是为了减少线程的创建和销毁以减少内存的消耗和资源的占用
- 线程池中包含了四个部分:核心线程、临时线程、工作队列、拒绝执行助手
- 线程池在刚创建的时候没有任何的线程,每接收一个新的请求就会创建一个核心线程来处理该请求
- 需要注意的是,在核心线程创建达到数量之前,即使有核心线程被空出,有新请求过来都会创建一个新的核心线程
- 当所有线程都被占用之后,再来的请求会被放入工作队列
- 工作队列本质上是一个阻塞式队列
- 当工作队列被占用满之后,后来的请求会被交给临时线程来处理
- 临时线程在处理完请求之后会再存活指定的时间,如果在指定时间内有请求过来则利用临时线程处理;如果没有请求,则时间倒了之后将临时线程销毁
- 当临时线程也被占满,则再来的请求会被交给拒绝执行助手处理
-
示例
public class ExecutorServiceDemo {
@Test
public void test() {
// 创建线程池
// corePoolSize:核心线程数量 5
// maximumPoolSize:最大线程数量,实际上是核心线程+临时线程 10
// keepAliveTime:临时线程存活时间 5000
// unit:时间单位 毫秒
// workQueue:工作队列 阻塞式顺序队列
// handler:拒绝执行助手,该参数可以定义也可以不定义
ExecutorService es = new ThreadPoolExecutor(5, 10, 5000, TimeUnit.MILLISECONDS,
new ArrayBlockingQueue<Runnable>(5), new RejectedExecutionHandler() {
@Override
public void rejectedExecution(Runnable r, ThreadPoolExecutor executor) {
System.out.println("拒绝处理线程" + new Thread(r).getName());
}
});
// 执行提交的任务
// 该方法只能执行Runnable线程
es.execute(new EsDemo());
// 关闭线程池
es.shutdown();
}
}
class EsDemo implements Runnable {
@Override
public void run() {
System.out.println("hello~~~");
}
}
- 预定义线程池
java中提供了一个工具类Executors来帮助我们简单快速创建一个线程池
// 特点:
// 1. 没有核心线程全部都是临时线程
// 2. 临时线程的数量可以认为是无限的
// 3. 每一个临时线程都可以存活1min
// 4. 工作队列为同步队列
// 大池子小队列
// 适用场景:
// 适合于高并发的短任务 - 即时通讯
// 不适合于长任务场景
ExecutorService es = Executors.newCachedThreadPool();
// 特点:
// 1. 全部都是核心线程没有临时线程
// 2. 工作队列是阻塞式链式队列,容量默认是Integer.MAX_VALUE
// 意味着工作队列足够大
// 小池子大队列
// 适用场景:
// 适合于长任务场景 - 下载
// 不适合于短任务场景
ExecutorService es = Executors.newFixedThreadPool(5);
而Executors提供了两种之星线程的方式
- execute():只能执行Runnable线程
- submit():可以执行Runnable也可以执行Callable线程,且存在返回值,由Future封装
Callable
-
概述
- JDK1.5提供的一种新的定义线程的方式
- 泛型表示返回值的类型
- 需要重写call方法,将要执行的逻辑放在该方法中
-
示例
public class CallableDemo {
public static void main(String[] args) throws InterruptedException, ExecutionException {
// 创建线程池
ExecutorService es = Executors.newCachedThreadPool();
// 创建Callable线程
CDemo c = new CDemo();
// 执行Callable线程
// 该方法既可以执行Callable线程也可以执行Runnable线程
// 该方法会将返回值封装成一个Future对象
Future<String> f = es.submit(c);
// 关闭线程池
es.shutdown();
// 从Future对象中解析结果
System.out.println(f.get());
}
}
class CDemo implements Callable<String> {
@Override
public String call() throws Exception {
return "SUCCESS";
}
}
三、Runnable和Callable的对比
| 对比项 | Runnable | Callable |
|---|---|---|
| 返回值 | 无,返回值类型为void | 有,类型用户指定 |
| 方法 | run | call |
| 启动方式 | 1. 传入Thread中通过Thread启动 只能通过线程池启动 | 2. 通过线程池启动 |
| 容错机制 | 无,出现异常必须在run方法中使用try-catch进行捕获处理 | 有,call方法允许抛出异常,所以在出现异常之后可以利用全局方式进行异常的处理 |
ScheduledExecutorService
- 概述
- 该接口继承了ExecutorService
- 该接口能够将提交的任务延后执行或者间隔固定的时间执行
- 利用该接口可以实现定时执行的效果
- 示例
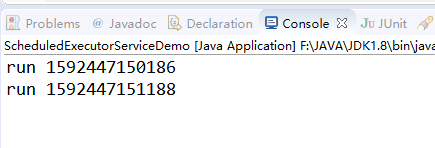
- schedule 推迟指定的时间再启动执行线程,这里推迟了1000毫秒才执行线程
public static void main(String[] args)
{
ScheduledExecutorService ses = Executors.newScheduledThreadPool(5);
System.out.println("run " + System.currentTimeMillis());
// 推迟指定的时间再启动执行线程
ses.schedule(new Runnable()
{
@Override
public void run()
{
System.out.println("run " + System.currentTimeMillis());
}
}, 1000, TimeUnit.MILLISECONDS);
}
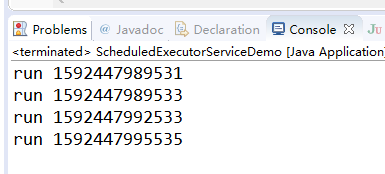
- scheduleAtFixedRate 表示每间隔指定的时间就执行一次
特点
: 从上一次开始时间来计算下一次的启动时间
: 当线程运行时间大于间隔时间时,按照线程实际运行时间间隔运行
public static void main(String[] args)
{
ScheduledExecutorService ses = Executors.newScheduledThreadPool(5);
System.out.println("run " + System.currentTimeMillis());
// 表示每间隔指定的时间就执行一次
// 从上一次开始时间来计算下一次的启动时间
ses.scheduleAtFixedRate(new Runnable()
{
@Override
public void run()
{
System.out.println("run " + System.currentTimeMillis());
try
{
Thread.sleep(2000);
}
catch (InterruptedException e)
{
e.printStackTrace();
}
}
}, 0, 3000, TimeUnit.MILLISECONDS);
}
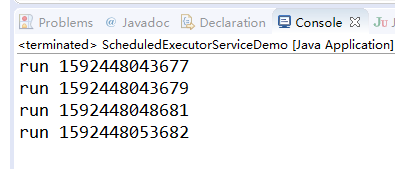
- scheduleWithFixedDelay 表示每间隔指定的时间就执行一次
特点
: 以上一次线程的结束时间开始计算下一次线程的启动时间(即线程间隔时间为线程执行时间+设置的间隔时间=两次线程开始执行的间隔时间)
public static void main(String[] args)
{
ScheduledExecutorService ses = Executors.newScheduledThreadPool(5);
System.out.println("run " + System.currentTimeMillis());
// 表示每间隔指定的时间就执行一次
// 从上一次开始时间来计算下一次的启动时间
ses.scheduleWithFixedDelay(new Runnable()
{
@Override
public void run()
{
System.out.println("run " + System.currentTimeMillis());
try
{
Thread.sleep(2000);
}
catch (InterruptedException e)
{
e.printStackTrace();
}
}
}, 0, 3000, TimeUnit.MILLISECONDS);
}
ForkJoinPool 分叉合并的线程池
-
概述
- 该线程池是一个用于分叉合并的线程池
- 分叉:将一个大的任务拆分成多个小的任务的过程
- 合并:将所有的小的任务的结果进行汇总的过程
- 分叉合并的目的是为了提高CPU的利用率
- 为了避免出现慢任务而导致效率降低,该线程池采取的是work-stealing(工作窃取)策略:即当当前CPU核在执行完所有的任务之后不会空闲而是会去扫描其他的CPU核,随机的从某一个CPU核上“偷”一个任务回来执行
-
示例 计算1-100000000000的和
public class ForkJoinPoolDemo {
public static void main(String[] args) throws InterruptedException, ExecutionException {
// 创建分叉合并线程池
ForkJoinPool pool = new ForkJoinPool();
// 提交任务获取执行结果
Future<Long> f = pool.submit(new Sum(1, 100000000000L));
// 关闭线程池
pool.shutdown();
// 打印结果
System.out.println(f.get());
}
}
// 如果分叉合并完成之后需要计算结果,则继承RecursiveTask
// 如果分叉合并完成之后需要不计算结果,则继承RecursiveAction
class Sum extends RecursiveTask<Long> {
private static final long serialVersionUID = -2919639359420237069L;
private long start; // 起始数字
private long end; // 末尾数字
private static final long THRESHOLD = 1000; // 分叉的阈值
public Sum(long start, long end) {
this.start = start;
this.end = end;
}
@Override
protected Long compute() {
// 判断数字范围是否在阈值范围内
if (end - start <= THRESHOLD) {
long sum = 0;
for (long i = start; i <= end; i++)
sum += i;
return sum;
} else {
long mid = (start + end) / 2;
Sum left = new Sum(start, mid);
Sum right = new Sum(mid + 1, end);
// 分叉
left.fork();
right.fork();
// 合并
return left.join() + right.join();
}
}
}
Lock
-
概述
- Lock是JDK1.5提供的一个表示锁的新接口
- 提供了用于加锁的方法lock()以及解锁的方法unlock()
- 相对传统的synchronized而言,Lock的方式更加灵活和精细
- 读写锁:接口ReadWriteLock - 实现类ReentrantReadWriteLock
-
公平和非公平策略
- 公平策略:加锁前检查是否有排队等待的线程,优先排队等待的线程,先来先得
- 非公平策略:加锁时不考虑排队等待问题,直接尝试获取锁,获取不到自动到队尾等待
- 相对而言,非公平策略的效率更高
- synchronized是非公平策略
- Lock默认是非公平策略,可以手动设置为公平策略
-
读写锁
- 读写锁分为读锁和写锁
- 读锁:允许多个线程读取,但是不允许线程写入
- 写锁:允许一个线程写入,但是不允许线程读取
-
其他锁
- CountDownLatch:闭锁/线程递减锁,可以对线程进行计数。当计数归零的时候就会放开阻塞 - 当所有的线程到达一个位置之后,开启另外的任务
package cn.tedu.lock;
import java.util.concurrent.CountDownLatch;
public class CountDownLatchDemo {
public static void main(String[] args) throws InterruptedException {
CountDownLatch cdl = new CountDownLatch(4);
new Thread(new Teacher(cdl)).start();
new Thread(new Student(cdl)).start();
new Thread(new Student(cdl)).start();
new Thread(new Student(cdl)).start();
// 使当前线程陷入阻塞,直到计数归零才会放开阻塞
cdl.await();
System.out.println("开始考试~~~");
}
}
class Teacher implements Runnable {
private CountDownLatch cdl;
public Teacher(CountDownLatch cdl) {
this.cdl = cdl;
}
@Override
public void run() {
try
{
Thread.sleep(5000);
}
catch (InterruptedException e)
{
e.printStackTrace();
}
System.out.println("监考老师到达考场");
// 计数减少1个
cdl.countDown();
}
}
class Student implements Runnable {
private CountDownLatch cdl;
public Student(CountDownLatch cdl) {
this.cdl = cdl;
}
@Override
public void run() {
System.out.println("考生达到考场");
cdl.countDown();
}
}
当考生和老师全部到达考场的时候才会进行考试

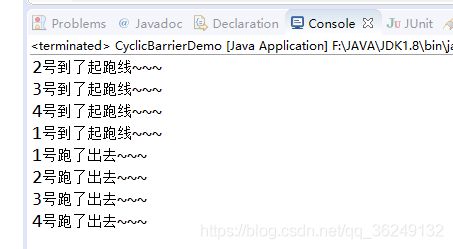
3. CyclicBarrier:栅栏。也是对线程计数的。当计数归零的时候就会放开阻塞。所有线程到达同一个点之后再分别继续往下执行
package cn.tedu.lock;
import java.util.concurrent.CyclicBarrier;
public class CyclicBarrierDemo {
public static void main(String[] args) {
CyclicBarrier cb = new CyclicBarrier(4);
new Thread(new Runner(cb), "1号").start();
new Thread(new Runner(cb), "2号").start();
new Thread(new Runner(cb), "3号").start();
new Thread(new Runner(cb), "4号").start();
}
}
class Runner implements Runnable {
private CyclicBarrier cb;
public Runner(CyclicBarrier cb) {
this.cb = cb;
}
public void run() {
String name = Thread.currentThread().getName();
System.out.println(name + "到了起跑线~~~");
try {
// 让当前线程陷入阻塞,并且同时减少一个计数
cb.await();
} catch (Exception e) {
e.printStackTrace();
}
System.out.println(name + "跑了出去~~~");
}
}
运动员全部到了起跑线再统一开跑
| 锁 | 区别:阻塞位置不同 |
|---|---|
| CountDownLatch | 当线程全部运行完成后,计数归零,开启其他线程执行剩余任务 |
| CyclicBarrier | 当线程到达阻塞点,等待计数归零后,在继续线程剩余的任务 |
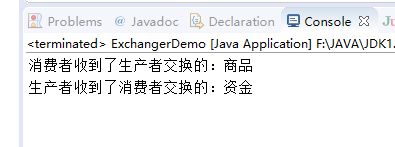
5. Exchanger:交换机。用于交换两个线程之间的信息,泛型表示要交换的信息类型
package cn.tedu.lock;
import java.util.concurrent.Exchanger;
public class ExchangerDemo {
public static void main(String[] args) {
Exchanger<String> ex = new Exchanger<>();
new Thread(new Producer(ex)).start();
new Thread(new Consumer(ex)).start();
}
}
class Producer implements Runnable {
private Exchanger<String> ex;
public Producer(Exchanger<String> ex) {
this.ex = ex;
}
@Override
public void run() {
try {
// 从另一端手中获取到交换的信息
String info = ex.exchange("商品");
System.out.println("生产者收到了消费者交换的:" + info);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
class Consumer implements Runnable {
private Exchanger<String> ex;
public Consumer(Exchanger<String> ex) {
this.ex = ex;
}
@Override
public void run() {
try {
String info = ex.exchange("资金");
System.out.println("消费者收到了生产者交换的:" + info);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
6. Semaphore:信号量。表示允许一段逻辑或者对象同时最多有指定个线程可以进入使用,在代码中用于限流
package cn.tedu.lock;
import java.util.concurrent.Semaphore;
public class SemaphoreDemo {
public static void main(String[] args) {
Semaphore s = new Semaphore(3);
for (int i = 0; i < 5; i++) {
new Thread(new Table(s)).start();
}
}
}
class Table implements Runnable {
private Semaphore s;
public Table(Semaphore s) {
this.s = s;
}
@Override
public void run() {
try {
// 获取到了一个信号,信号量减一
s.acquire();
System.out.println("一张桌子被占用~~~");
Thread.sleep((long) (10000 * Math.random()));
// 释放一个信号,信号量加一
s.release();
System.out.println("一张桌子被空出~~~");
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}
桌子被全部占用后,只有当桌子空出,才会重新被占用
