【Golang】源码学习:runtime/chan.go:了解channel背后的实现原理
一、概述
Go通过channel在独立工作的Goroutine之间实现了通信,其背后是Go的CSP并发模型,其理念被概括为:
Do not communicate by sharing memory; instead, share memory by communicating.
不要通过共享内存的方式来通信,相反,要通过通信来共享内存。
这一策略在Go中的实现,就是将channel即管道作为一等公民,就像现实中的“管道”一样沟通独立的协程,发送方协程将信息放入管道,由接受方协程从管道中取出,以此来达到通信的目的,这种模式与Linux中的管道有些类似,主要特点有:
- 协程间安全(goroutine-safe)
- 跨协程存储和传输信息(store and pass values between goroutines)
- 提供FIFO机制(provide FIFO semantics)
- 具备阻塞和恢复协程的能力(can cause goroutines to block and unblock)
在实际使用中,channel在并发场景下发挥了巨大的作用,是GoLang并发编程的支柱之一,而其背后的实现机制是什么样、Go团队是如何通过700多行代码实现了如此强大的功能,将是本文要探究的主要内容。
本文主要学习了有关协程调度和通道机制的热门文章,结合源码和大佬的PPThttps://speakerdeck.com/kavya719/understanding-channels (需要科学上网),分析和学习Go channel的实现机制。
二、hchan的结构和初始化
结构体hchan描述了一个管道的主要组成结构,代码如下:
type hchan struct {
//对于有缓冲的channel,hchan维护一个缓冲区来储存缓冲内容
qcount uint // channel已缓存数据数量
dataqsiz uint // channel容量
buf unsafe.Pointer // 带缓冲的channel的缓冲区,环形数组
sendx uint // 缓冲区中待发送位置索引
recvx uint // 缓冲区中待接收位置索引
//channel存储元素相关信息
elemsize uint16 // 存储元素大小
closed uint32 //是否被关闭标记
elemtype *_type // 储存元素类型
//储存channel连接两端Goroutine的抽象信息
recvq waitq // 接收者信息队列(双向链表)
sendq waitq // 发送者信息队列(双向链表)
//对channel中上述所有域的保护锁
lock mutex
}可以看到,除互斥锁外,一个hchan结构主要包含了三大部分:
- 带缓冲区管道特有的一个环形缓冲区及其维护信息。
- 关于本管道目标传输数据的类型信息。
- 用于阻塞和恢复管道两端Goroutine的两个队列。
使用make语句初始化一个channel时,将在当前程序堆上为一个hchan申请空间,并返回指向这个空间的指针,因此,一个channel在被创建时,就已经已指针的形势存在,不需要再用指向channel的指针来传递channel

对于带缓冲管道,势必需要包含一个缓冲区来完成数据缓冲工作,示意如下:

通过hchan的主要结构可知,在初始化hchan时,主要完成了两大工作:
1、分情况初始化缓冲区buf相关参数
switch {
case mem == 0:
//不带有缓冲区,直接初始化,将不为buf分配内存
c = (*hchan)(mallocgc(hchanSize, nil, true))
c.buf = c.raceaddr()
case elem.ptrdata == 0:
//传输非指针类型的带缓冲通道,将buf指向分配内存的首地址
c = (*hchan)(mallocgc(hchanSize+mem, nil, true))
c.buf = add(unsafe.Pointer(c), hchanSize)
default:
// 处理带缓冲且元素类型为指针的情况
c = new(hchan)
c.buf = mallocgc(mem, elem, true)
}2、保存channel传输元素的类型信息
c.elemsize = uint16(elem.size)
c.elemtype = elem
c.dataqsiz = uint(size)
三、无阻塞情况下的简单通信
当channel带有缓冲区且缓冲区未满/未空时,将不存在阻塞的情况,发送方将数据拷贝到hcan.buf中当前sendx索引的位置,接收方直接从hchan.buf中取出当前recvx索引位置的数据。
当然,对hchan内部字段的操作都应该在互斥锁的并发保护下进行。
1、发送方操作:

if c.qcount < c.dataqsiz {
// Space is available in the channel buffer. Enqueue the element to send.
qp := chanbuf(c, c.sendx)
if raceenabled {
raceacquire(qp)
racerelease(qp)
}
typedmemmove(c.elemtype, qp, ep)
c.sendx++
if c.sendx == c.dataqsiz {
c.sendx = 0
}
c.qcount++
unlock(&c.lock)
return true
}2、接收方操作:

if c.qcount > 0 {
// Receive directly from queue
qp := chanbuf(c, c.recvx)
if raceenabled {
raceacquire(qp)
racerelease(qp)
}
if ep != nil {
typedmemmove(c.elemtype, ep, qp)
}
typedmemclr(c.elemtype, qp)
c.recvx++
if c.recvx == c.dataqsiz {
c.recvx = 0
}
c.qcount--
unlock(&c.lock)
return true, true
}从上述过程可以看出,在无阻塞情况下,Goroutine之间通过channel进行通信,是通过一个带有互斥锁的缓冲区实现的,但这并不是在共享内存,因为无论是发送方还是接受方,都是在以复制的方式放入或拿出数据。
四、发送方先被阻塞
当channel不携带缓冲区或当前缓冲区已满,若接收者等待队列recvq为空,根据设计需求,本次发送协程需要被阻塞,等待有接收方取出要发送的数据,结束阻塞。

阻塞过程涉及到Go协程实现模型MPG,其原理可以参考:
https://i6448038.github.io/2017/12/04/golang-concurrency-principle/
http://lessisbetter.site/2019/04/04/golang-scheduler-3-principle-with-graph/
简单来说,G是指Goroutine,即Go特有的协程;M是Go语言定义出来在用户层面描述系统线程的对象 ,每个M代表一个系统线程,而P是一个逻辑处理器(Processor),包含了运行Goroutine时所需的资源(又称上下文、Context),每个P维护了一个G等待队列,Go程序运行后期间,一个M需要与一个P绑定,获取P的队列中的G进而运行。

当一个G将要被阻塞时,将断开与当前运行自己的M、P的连接,而此时M、P可以获取队列中的下一个G继续运行,因此,在Go中,阻塞将仅仅是协程G的阻塞,而实际工作线程M将继续其他工作,这大大提高了并发效率。
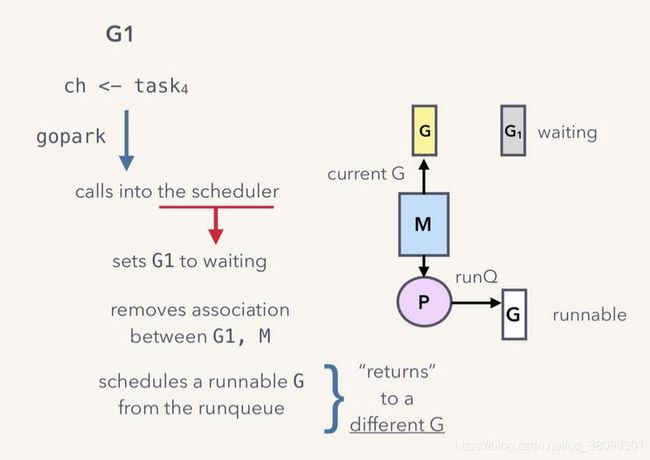
如上图,这一阻塞过程将使用gopark函数调用scheduler实现。
func gopark(unlockf func(*g, unsafe.Pointer) bool, lock unsafe.Pointer, reason waitReason, traceEv byte, traceskip int) {
if reason != waitReasonSleep {
checkTimeouts() // timeouts may expire while two goroutines keep the scheduler busy
}
mp := acquirem()
gp := mp.curg
status := readgstatus(gp)
if status != _Grunning && status != _Gscanrunning {
throw("gopark: bad g status")
}
mp.waitlock = lock
mp.waitunlockf = unlockf
gp.waitreason = reason
mp.waittraceev = traceEv
mp.waittraceskip = traceskip
releasem(mp)
// can't do anything that might move the G between Ms here.
mcall(park_m)
}在计算机系统进程切换中,除了阻塞当前进程、换入新进程外,还有一个必需的操作是保存当前进程运行信息,这样才能顺利恢复原进程,而Goroutine的阻塞与恢复理应也需要这一设计。与系统进程和线程相比,Go协程更加轻量化,因此更容易被抽象出轻量的运行状态。
回看hchan结构可以找到两个类型为waitq的队列sendq/recvq,分别用于存储被阻塞的发送协程和接收协程。
一个被阻塞的协程和其要发送/接受的数据被使用一个sudog结构封装,结构如下:
type sudog struct {
// The following fields are protected by the hchan.lock of the
// channel this sudog is blocking on. shrinkstack depends on
// this for sudogs involved in channel ops.
g *g
// isSelect indicates g is participating in a select, so
// g.selectDone must be CAS'd to win the wake-up race.
isSelect bool
next *sudog
prev *sudog
elem unsafe.Pointer // data element (may point to stack)
// The following fields are never accessed concurrently.
// For channels, waitlink is only accessed by g.
// For semaphores, all fields (including the ones above)
// are only accessed when holding a semaRoot lock.
acquiretime int64
releasetime int64
ticket uint32
parent *sudog // semaRoot binary tree
waitlink *sudog // g.waiting list or semaRoot
waittail *sudog // semaRoot
c *hchan // channel
}当一个发送协程被阻塞,就将被抽象成一个sudog结构储存在hchan的sendq队列中,如图示:

具体场景:
1、发送方向无缓冲或缓冲已满的channel发送数据
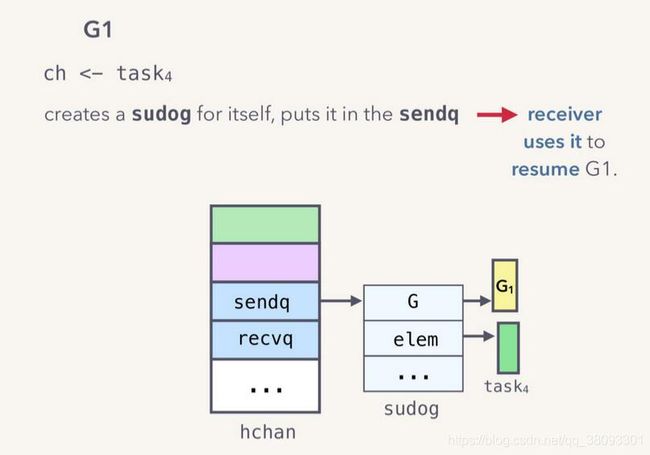
G1对于已满的缓冲区ch,执行发送操作:
G1:
ch<-task4- 调用hansend函数操作ch,判断缓冲区已满。
- 将G1运行信息和待发送数据task封装为一个sudog实例,存放在sendq队列中。
- 调用gopark函数,使用scheduler将G1阻塞,让出当前M和Q
//对发送协程创建sudog并保存相关信息
gp := getg()
mysg := acquireSudog()
mysg.releasetime = 0
if t0 != 0 {
mysg.releasetime = -1
}
// No stack splits between assigning elem and enqueuing mysg
// on gp.waiting where copystack can find it.
mysg.elem = ep
mysg.waitlink = nil
mysg.g = gp
mysg.isSelect = false
mysg.c = c
gp.waiting = mysg
gp.param = nil
c.sendq.enqueue(mysg)
//使用scheduler阻塞当前协程
goparkunlock(&c.lock, waitReasonChanSend, traceEvGoBlockSend, 3)上述操作结束后,hchan状态如下:
2、接收方接收数据,释放阻塞的发送方
接受方G2尝试从ch中获取一个数据:
G2:
task<-ch
chanrecv函数将首先判断sendq队列非空,调用recv函数处理。
if sg := c.sendq.dequeue(); sg != nil {
// Found a waiting sender. If buffer is size 0, receive value
// directly from sender. Otherwise, receive from head of queue
// and add sender's value to the tail of the queue (both map to
// the same buffer slot because the queue is full).
recv(c, sg, ep, func() { unlock(&c.lock) }, 3)
return true, true
}
recv函数首先判断本channel是否有缓冲区。
若无缓冲区,直接将sendq队首的sudog取出,数据拷贝到接收者数据地址上。
func recvDirect(t *_type, sg *sudog, dst unsafe.Pointer) {
// dst is on our stack or the heap, src is on another stack.
// The channel is locked, so src will not move during this
// operation.
src := sg.elem
typeBitsBulkBarrier(t, uintptr(dst), uintptr(src), t.size)
memmove(dst, src, t.size)
}若存在缓冲区,先取出缓冲区recvx索引的数据,作为本次读取的值。

将sendq队列中的队首sudog弹出。
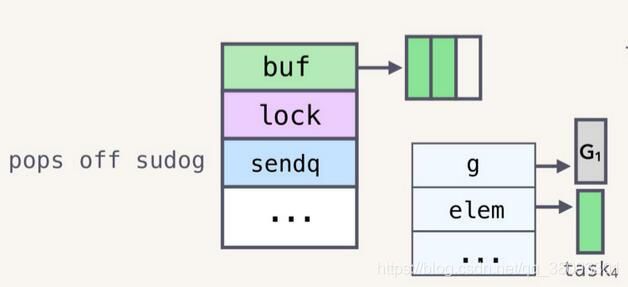
将弹出的sudog的数据存放到缓冲区中,调整sendx和recvx的值。
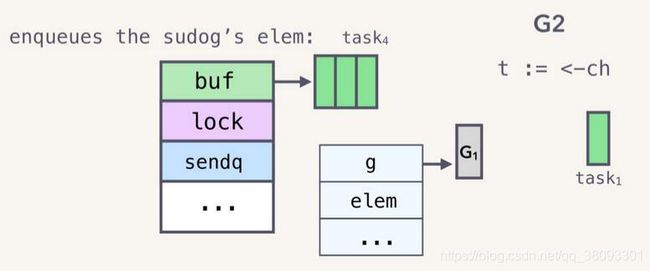
具体代码:
qp := chanbuf(c, c.recvx)
if raceenabled {
raceacquire(qp)
racerelease(qp)
raceacquireg(sg.g, qp)
racereleaseg(sg.g, qp)
}
// copy data from queue to receiver
if ep != nil {
typedmemmove(c.elemtype, ep, qp)
}
// copy data from sender to queue
typedmemmove(c.elemtype, qp, sg.elem)
c.recvx++
if c.recvx == c.dataqsiz {
c.recvx = 0
}
c.sendx = c.recvx // c.sendx = (c.sendx+1) % c.dataqsiz
最终,调用goready,将被阻塞的G1协程唤醒。
sg.elem = nil
gp := sg.g
unlockf()
gp.param = unsafe.Pointer(sg)
if sg.releasetime != 0 {
sg.releasetime = cputicks()
}
goready(gp, skip+1)goready函数将调用scheduler,将G1恢复,添加到P的阻塞队列中,通过Go的调度机制可以知道,恢复的协程将优先回到阻塞前所在的队列等待运行。

五、接收方先被阻塞
1、接收方先尝试读管道
当接受方尝试读取一个空channel中的值是,同样将导致自身阻塞。
G2:
t<-ch
与发送协程阻塞的过程相似,阻塞接收协程需要把该协程抽象为一个sudog实例,此时sudog.elem字段存的将是该协程期望接受数据后存储位置的指针,代码如下:
//初始化sudog结构
gp := getg()
mysg := acquireSudog()
mysg.releasetime = 0
if t0 != 0 {
mysg.releasetime = -1
}
mysg.elem = ep
mysg.waitlink = nil
gp.waiting = mysg
mysg.g = gp
mysg.isSelect = false
mysg.c = c
gp.param = nil
c.recvq.enqueue(mysg)
//阻塞该接收协程
goparkunlock(&c.lock, waitReasonChanReceive, traceEvGoBlockRecv, 3)创建sudog和阻塞协程的过程与发送操作如出一辙,新创建的sudog将被存放在hchan的接收者队列recvq的队尾。
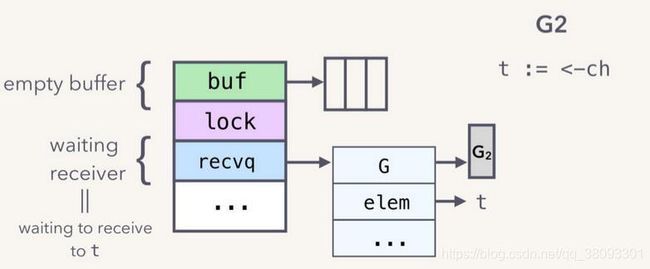
2、发送方发送
G1:
ch<-task可能最自然能想到的设计就是,不论recvq中是否有阻塞协程,发送方都先将数据存放在buf中,再提示recvq中的阻塞协程提取数据。但显然存在一种更好的方案:
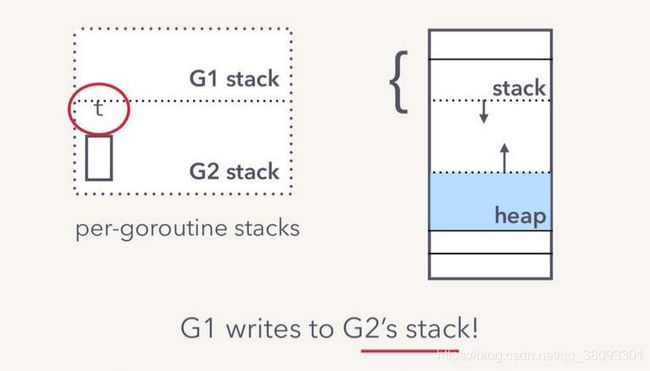
在将发送数据放入缓存区或者阻塞自身之前,发送协程将首先检查是否recvq中存在阻塞,若存在阻塞的接收协程,则直接将数据拷贝到队列最前端的sudog实例的elem指针中。
这种方案与通过buf转移数据的效果并没有任何不同,反而提高了并发通信效率。
if sg := c.recvq.dequeue(); sg != nil {
// Found a waiting receiver. We pass the value we want to send
// directly to the receiver, bypassing the channel buffer (if any).
send(c, sg, ep, func() { unlock(&c.lock) }, 3)
return true
}最终,阻塞的接收协程拿到了自己想要的数据,并被唤醒,该过程与唤醒接收协程一致。
gp := sg.g
unlockf()
gp.param = unsafe.Pointer(sg)
if sg.releasetime != 0 {
sg.releasetime = cputicks()
}
goready(gp, skip+1)六、接收与发送流程总结
发送流程:
- hchan 上锁
- 判断recvq队列中是否有待接收协程,有则直接发送并唤醒对方。
- 判断当前hchan是否带缓冲且空间足够,有则拷贝数据到buf中对应的位置
- 缓冲空间不够或者hchan为不带缓冲channel,根据自身信息抽象为sudog结构并保存在sendq队列中,阻塞自身。
- hchan 解锁
接收流程:
- hchan 上锁
- 判断sendq队列是否有待发送协程
- 存在待发送协程,若缓冲区为空或无缓冲区,直接从待发送协程拷贝数据,唤醒该协程。
- 存在待发送协程,缓冲区不为空,拷贝对应位置数据,将待发送协程数据拷贝到缓冲区,唤醒该协程。
- 不存在待发送协程,缓冲区不存在或为空,根据自身信息抽象为sudog结构并保存在recvq队列中,阻塞自身。
- hchan 解锁
七、其他情况和一些细节
1、关闭的channel
关闭channel函数closechan:
func closechan(c *hchan) {
......
var glist gList
// 释放recvq所有接收协程
for {
sg := c.recvq.dequeue()
......
gp := sg.g
......
glist.push(gp)
}
// 释放sendq队列所有发送协程(将导致panic)
for {
sg := c.sendq.dequeue()
......
gp := sg.g
......
glist.push(gp)
}
unlock(&c.lock)
// Ready all Gs now that we've dropped the channel lock.
for !glist.empty() {
gp := glist.pop()
gp.schedlink = 0
goready(gp, 3)
}
}对于一个已关闭的channel操作,发送数据将导致panic:
if c.closed != 0 {
unlock(&c.lock)
panic(plainError("send on closed channel"))
}接收操作可以正常运行,在缓冲区剩余数据被拷贝完毕后,获取的将是typedmemcir后的零值:
if c.closed != 0 && c.qcount == 0 {
if raceenabled {
raceacquire(c.raceaddr())
}
unlock(&c.lock)
if ep != nil {
typedmemclr(c.elemtype, ep)
}
return true, false
}2、channel为空值(nil)
无论是尝试发送或是读取nil值的channel,都将导致自身被阻塞。
if c == nil {
if !block {
return false
}
gopark(nil, nil, waitReasonChanSendNilChan, traceEvGoStop, 2)
throw("unreachable")
}
3、主动阻塞与被动唤醒
- 协程间通信时,通过gopark和goready函数调用scheduler。
- 阻塞均是协程在尝试读/写管道时自行发起的,是一个主动的操作。
- 唤醒一个阻塞协程,均是由channel另一端的协程来完成,因此是被动唤醒。
- hchan结构保存了因读写而阻塞的所有协程的信息,发挥了巨大作用。
4、数据读写过程
- hchan结构同时被多个Goroutine持有,实际上是共享内存,因此全程被互斥锁保护。
- 不具备缓冲区的channel,实际上通信双方是直接发送数据,channel是一个“登记簿”的身份。
- 具备缓冲区的channel,多了“货物中转站”的身份,有暂存通信数据的功能。
- FIFO的机制:环形缓冲区、双向链表结构的sendq和recvq,均满足了先进先出的设定。
实际上,无论是两端直传,还是利用缓冲区读写数据,对于channel的操作均是通过复制实现的,因此,虽然hchan结构是一个共享内存结构,被传统的互斥锁保护,但在读写操作优良的设计和强大的gc机制支撑下,协程间实际通信的数据内容实际上不存在被共享的内存,是协程间安全的。
这正印证了:
Do not communicate by sharing memory; instead, share memory by communicating.
不要通过共享内存的方式来通信,相反,要通过通信来共享内存。