Mask R-CNN 训练自己的数据集(balloon过程+报错解释)
因项目需要,识别带有多边形标注的图像,舍弃了速度快精度高的yolov3,使用Mask R-CNN网络。作为一名深度学习小白,在摸爬滚打中查找资料修改代码以及不断地调整训练集,途中踩了不少坑,终于达到预期的效果。
一、配置说明
以下是本人跑Mask R-CNN的配置说明:
- Python 3.52
- tensorflow 1.12.0
- keras 2.2.4
- Jupyter Notebook
- 一块gpu
二、标注训练集、验证集
使用的是VIA,标记了三百张,训练集和验证集的比例是8:2。对于VIA,使用感受如下:
优点是:网络版、不用下载,标注比较快,可直接生成1个json文件
缺点是:网速不好就标记不上,电脑死机就全没了,有时候崩得特别厉害标注不上
VIA网站:http://www.robots.ox.ac.uk/~vgg/software/via/via.html
VIA的使用教程:https://blog.csdn.net/heiheiya/article/details/81530952
新建datasets文件夹,在里面再新建两个文件夹“tarin”,和“val”,将训练集的图片及对应json放入train文件夹,验证集的图片及对应json放入val文件夹。
这个datasets文件夹放在根目录下(和sample,mrcnn文件夹同目录)。
三、代码修改
下载mask R-CNN的代码包:https://github.com/matterport/Mask_RCNN
本文使用的是balloon文件夹下的。之后训练使用的是balloon.py的,且主要也是在balloon.py里修改。网上有很多对于训练多类的代码,不过都有一些问题,主要是从json取信息出错,不知道是版本问题还是VIA输出问题。
主要修改以下三段:
首先是Config的修改,可以不用在config.py中修改,直接在balloon.py中修改就行。不过如果是为了对比另外几个训练效果的话,还是建议在config.py中修改如下数值。
class BalloonConfig(Config):
"""
从基本Config中修改一些数值
"""
# 命名配置
NAME = "balloon"
# 如果显卡显存不大,建议填1
IMAGES_PER_GPU = 1
# 类别数量(包括背景),因本项目又6类
NUM_CLASSES = 1 + 6 # 背景+类别数
# 每个epoch训练的步数
# 在每个epoch的最后也会更新验证的状态,这会花费一些时间
# 本项目设置的是1000,建议如果显存不够的朋友们设置小一点
# 但不建议太小,不要低于验证的步数
STEPS_PER_EPOCH = 1000
#在每个训练epoch的结尾进行验证的步数。
#用的是验证集里的图片和数据
VALIDATION_STEPS = 50
#图片最大像素及最小像素,不要求图片固定大小
IMAGE_MIN_DIM = 448
IMAGE_MAX_DIM = 640
# 忽略置信度小于0.9的检测
DETECTION_MIN_CONFIDENCE = 0.9
在Dataset中增加类别,和改变对json的识别。如果是用矩形标注的图像也可以使用,但是需要修改代码。
class BalloonDataset(utils.Dataset):
def load_balloon(self, dataset_dir, subset):
"""Load a subset of the Balloon dataset.
dataset_dir: Root directory of the dataset.
subset: Subset to load: train or val """
# 添加你需要增加的类别,前面双引号里的是配置命名,然后是编号,最后是类名
self.add_class("balloon", 1, "xxxx")
self.add_class("balloon", 2, "xxxx")
self.add_class("balloon", 3, "xxxx")
self.add_class("balloon", 4, "xxxx")
self.add_class("balloon", 5, "xxxx")
self.add_class("balloon", 6, "xxxx")
assert subset in ["train", "val"]
dataset_dir = os.path.join(dataset_dir, subset)
# 载入json文件
annotations = json.load(open(os.path.join(dataset_dir, "via_region_data.json")))
annotations = list(annotations.values())
# don't need the dict keys
# VIA工具将图像保存在JSON中
# 跳过没有标注的图片
annotations = [a for a in annotations if a['regions']]
for a in annotations:
# 从中获得多边形的数据和类别名称
polygons = [r['shape_attributes'] for r in a['regions']]
name = [r['region_attributes']['type'] for r in a['regions']]
# 序列字典
name_dict = {"xxx":1,"xxx":2,"xxx":3,"xxx":4,"xxx":5,"xxx":6}
name_id = [name_dict[a] for a in name]
image_path = os.path.join(dataset_dir, a['filename'])
image = skimage.io.imread(image_path)
height, width = image.shape[:2]
# for i,j in enumerate(polygons):
self.add_image(
"balloon",
image_id=a['filename'],
# image_id='{}_{}'.format(a['filename'],i),
# use file name as a unique image id
path=image_path,
class_id=name_id,
width=width, height=height,
polygons=polygons)
修改load_mask函数
def load_mask(self, image_id):
"""Generate instance masks for an image.
Returns:
masks: A bool array of shape [height, width, instance count] with
one mask per instance.
class_ids: a 1D array of class IDs of the instance masks.
"""
image_info = self.image_info[image_id]
if image_info["source"] != "balloon" :
return super(self.__class__, self).load_mask(image_id)
name_id = image_info["class_id"]
print(name_id)
# 将多边形转换为一个二值mask,[高, 宽, 数目]
info = self.image_info[image_id]
mask = np.zeros([info["height"], info["width"], len(info["polygons"])],
dtype=np.uint8)
class_ids = np.array(name_id, dtype=np.int32)
for i, p in enumerate(info["polygons"]):
# 获取多边形内像素的索引并将其设置为1
rr, cc = skimage.draw.polygon(p['all_points_y'], p['all_points_x'])
mask[rr, cc, i] = 1
return mask.astype(np.bool), class_ids
至此,就可以进行可视化和训练了。
四、模型可视化
同目录下的inspect_balloon_data.ipynb就是模型可视化数据的文件。需要使用jupyter notebook打开。
如果说训练集的图片,和上述代码,以及json都没有出现任何问题的话,是可以正常运行的。
这些数字代表的是类别,并且会将不同类别的物品分别显示在不同框中。
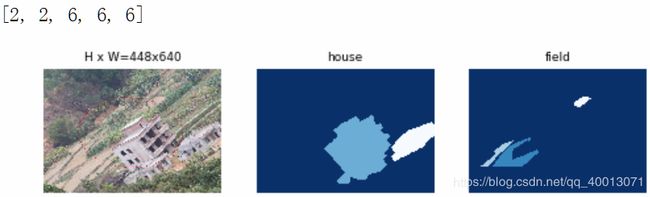
五、模型训练和检测
首先新建一个文件夹logs放在根目录,存放权重文件。
注意,每轮都会生成一个权重文件244M,确保存储空间充足。
直接python balloon.py train --dataset=/datasets --weights=coco
或者是python balloon.py train --dataset=/datasets --weights=last
在jupyter notebook 就是%run 和后面那些
dataset后面的路径请填前面datasets存在的位置。
(其实填错了也没所谓,路径在balloon.py里的train中可以设置)
第一行的意思是以coco数据集的权重进行权重转移
第二行的意思是以上一次训练的数据集的权重继续训练
以及训练过程中,还剩最后一步时突然有很多[1]或者别的,这些都是对验证集中的标注进行修正权重,不用担心。
训练完成,基本上每个步长的loss降到0.2就能有很不错的效果了。
然而对于多类来说,原本的inspect_balloon_model.ipynb并不能很好地把效果展示出来,需要修改代码(只需要把自己的路径填上来就可以啦),新建一个ipynb,放在网络根文件夹所在位置:
import os
import sys
import random
import math
import numpy as np
import skimage.io
import matplotlib
import matplotlib.pyplot as plt
from samples.balloon import balloon
from mrcnn.model import log
# Root directory of the project
ROOT_DIR = " " # 整个网络所在的位置
# Import Mask RCNN
sys.path.append(ROOT_DIR)
from mrcnn import utils
import mrcnn.model as modellib
from mrcnn import visualize
# Import COCO config
sys.path.append(os.path.join(ROOT_DIR, "samples/coco/"))
#import coco
%matplotlib inline
# Directory to save logs and trained model
MODEL_DIR = os.path.join(ROOT_DIR, "logs")
print(MODEL_DIR)
# Local path to trained weights file
MY_MODEL_PATH = os.path.join(ROOT_DIR, " ") # 最后一个训练权重所在位置
print(MY_MODEL_PATH)
COCO_MODEL_PATH = os.path.join(ROOT_DIR, "mask_rcnn_coco.h5")
# Download COCO trained weights from Releases if needed
if not os.path.exists(COCO_MODEL_PATH):
utils.download_trained_weights(COCO_MODEL_PATH)
# Directory of images to run detection on
IMAGE_DIR = os.path.join(ROOT_DIR, "images")
config = balloon.BalloonConfig()
config.display()
BALLOON_DIR = os.path.join(ROOT_DIR, " ") # tarin和val所在位置
print(BALLOON_DIR)
# Create model object in inference mode.
model = modellib.MaskRCNN(mode="inference", model_dir=MODEL_DIR, config=config)
# Load weights trained on MS-COCO
model.load_weights(MY_MODEL_PATH, by_name=True)
# COCO Class names
# Index of the class in the list is its ID. For example, to get ID of
# the teddy bear class, use: class_names.index('teddy bear')
class_names = ['xxx',xxx','xxx'……] # 这里填分的类别
def get_ax(rows=1, cols=1, size=16):
"""Return a Matplotlib Axes array to be used in
all visualizations in the notebook. Provide a
central point to control graph sizes.
Adjust the size attribute to control how big to render images
"""
_, ax = plt.subplots(rows, cols, figsize=(size*cols, size*rows))
return ax
# Load validation dataset
dataset = balloon.BalloonDataset()
dataset.load_balloon(BALLOON_DIR, "val")
# Must call before using the dataset
dataset.prepare()
image_id = random.choice(dataset.image_ids)
image, image_meta, gt_class_id, gt_bbox, gt_mask =\
modellib.load_image_gt(dataset, config, image_id, use_mini_mask=False)
info = dataset.image_info[image_id]
print("image ID: {}.{} ({}) {}".format(info["source"], info["id"], image_id,
dataset.image_reference(image_id)))
# Run object detection
results = model.detect([image], verbose=1)
# Display results
ax = get_ax(1)
r = results[0]
visualize.display_instances(image, r['rois'], r['masks'], r['class_ids'],
dataset.class_names, r['scores'], ax=ax,
title="Predictions")
log("gt_class_id", gt_class_id)
log("gt_bbox", gt_bbox)
log("gt_mask", gt_mask)
然后就可以看到检测效果了:

看得出来效果还是很不错的~
剩下的一些检测训练可视化的东西可以照搬inspect_balloon_model.ipynb后面的来看了。
如果需要看网络中诸多loss的变化曲线,可以使用tensorboard查看,注意logs文件夹中的events开头的文件不要删掉。
在有events文件的目录下进入cd,输入:
tensorboard --logdir=(events文件所在路径)
因为之前已经pip install jupyter-tensorboard
但不知道为什么从jupyter notebook中会出现 Failed to load the set of active dashboards.
改成localhost:6006就行了
好像只能用chrome浏览器才可以访问,这个根据个人的设置情况不同而不同,网上有很多情况解释,可以多查一下。

点击就能看到相应的loss随epoch变化而变化。
六、遇到的报错
代码实现的过程中,遇到的很多错误无非都是以下两点。
因训练集、数据集引起的报错
- keyword:‘type’
意思就是从json里读取type出错,也就是标注文件中有图像是有标注但没设置type的。重新在VIA中检查一下是哪个图像没有按类别标注。 - index 641 is out of bounds for axis 1 with size 640
意思是标注的信息超过了图的大小范围,报错的时候会直接提示是哪张图片,直接在via中检查调整一下点再重新生成json就可以了。
因显存不够引起的报错
- tensorflow:OOM when allocating tensor with shape …
这一条代表显存不够,调steps_per_epoch,关掉别的乱七八糟的软件(直接重启)就行。 - UserWarning: Converting sparse IndexedSlices to a dense Tensor of unknown shape. This may consume a large amount of memory.
这一条是警告,不会影响程序运行,不过需要小心在训练中途会突然报第一个错。不过也没关系,可以衔接最近一次的训练权重继续训练。