汇编语言实验五完整代码
汇编语言实验五完整代码
建议先自己思考问题的答案,不懂则返回看书
(1)、【代码略,书上有,自己运行代码,单步执行,多加体会】
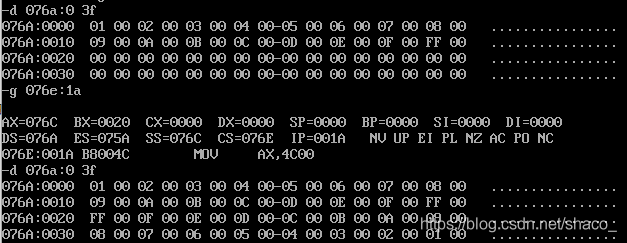
① CPU执行程序,程序返回前,data段中的数据并未改变,仍是原始数据。
② CPU执行程序,程序返回前,CS=076C,SS=076B,DS=076A。
③ 进一步可以发现,若code段的段地址为X,则data段的段地址为X-2,stack段的段地址为X-1。
(2)、【偷懒就不誊代码了,自己运行】
① CPU执行程序,程序返回前,data段中的数据并未改变,仍是原始数据。
② CPU执行程序,程序返回前,CS=076C,SS=076B,DS=076A
③ 程序加载后,若code段的段地址为X,则data段的段地址为X-2,stack段的段地址为X-1。
④ 如果name段中的数据占N个字节,则实际占有的空间为 ((N-1)/16+1)*16, 或者 ((N/16)向下取整)*16。(式子本质一样,表述不同而已。)
解析:比较(1)和(2)的段中定义的数据,虽然我们定义的数据在数量上不同,但是在DOS中段占有的字节数却相同。即只定义了两个字数据的数据段和两个字型数据当栈空间,但实际上在内存分配上还是给它们16个字节的空间,所以它是以16字节为一个单元分配的,不足16字节按16字节处理。 所以很容易得到此公式
(3)、【与前两题不一样的地方主要是此题的data和stack段在code段之后,本质没变,思路相同】
① CPU执行程序,程序返回前,data段中的数据为 23 01 56 04
② CPU执行程序,程序返回前,CS=076A,SS=076E,DS=076D。
③ 程序加载后,code段的段地址为X,则data段的段地址为X+3,stack段的段地址为X+4。
(4)、如果将(1)(2)(3)题中的最后一条伪指令“end start”改为“end”(也就是说,不指明程序的入口),则哪个程序仍然可以正确执行?请说明原因。
解析 : 将最后一条伪指令“end start”改为“end”,即没有指明程序入口,此时程序就会从加载进内存的第一个单元起开始执行。在(1)(2)题中,都是数据先加载进内存,不能保证最终被正确执行;而(3)题则是代码段先被加载进内存,因而可以被正确执行。
(5)、编写code段中的代码,将a、b段数据的依次相加放入c段
(这些代码是刚开始时自学时写的,代码格式不好,大家写代码时要养成良好的代码风格)
assume cs:code
a segment
db 1,2,3,4,5,6,7,8
a ends
b segment
db 1,2,3,4,5,6,7,8
b ends
c segment
db 0,0,0,0,0,0,0,0
c ends
code segment
start:
mov bx,a
mov es,bx
mov bx,b
mov ss,bx
mov bx,c
mov ds,bx
mov bx,0
mov cx,8
s:
mov ax,0
mov al,es:[bx]
add al,ss:[bx]
mov ds:[bx],al
inc bx
loop s
mov ax,4c00h
int 21h
code ends
end start
此代码在DOSBox下的运行结果:
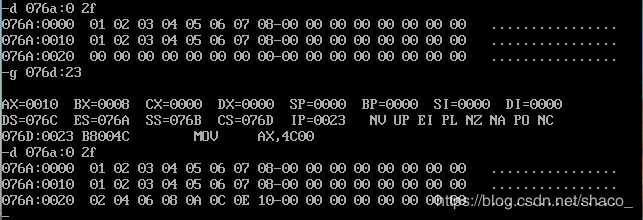
(6)、程序如下,编写code段中代码,用PUSH指令将A段中的前8个字型数据,逆序存储到B段中。
assume cs:code
a segment
dw 1,2,3,4,5,6,7,8,9,0ah,0bh,0ch,0dh,0eh,0fh,0ffh
a ends
b segment
dw 0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0
b ends
code segment
start:
mov ax,a
mov ds,ax
mov ax,b
mov ss,ax
mov sp,20h
mov bx,0
mov cx,16
s:
push [bx]
add bx,2
loop s
mov ax,4c00h
int 21h
code ends
end start
此代码在DOSBox下的运行结果: