Django框架之美多商城项目
后续技术类文档更新到微信公众号-------->>喜欢的扫码关注
美多商城
1. 项目的准备
- 分析商业模式:B2C
- 开发流程
- 项目的架构
- 创建工程
- 配置
2. 登录模块
2.1 注册
- 用户模型类:AbstractUser
Django默认提供的认证系统中,用户的认证机制依赖Session机制,我们在本项目中将引入JWT认证机制,将用户的身份凭据存放在Token中,然后对接Django的认证系统
用户的数据模型
用户密码的加密与验证
用户的权限系统
Django提供了django.contrib.auth.models.AbstractUser用户抽象模型类允许我们继承
不支持手机号验证登录: 所以我们需要进行user模型类添加mobile字段;还要继承abstractuser然后再重写类方法加上手机号等
2.2 图片验证码
- 借助第三方工具包:captcha
- 图片验证码保存在Redis中:
key:UUID
value:图片验证码的内容
2.3 短信验证码
- 使用的是云通讯发送短信验证码
- 由于发送短信比较耗时,所以i使用Celery异步任务发送短息验证码
celery的组成:
- 任务队列:broker; 任务队列存储在redis数据库中
- 处理器:worker; 从任务队列里面拿任务进行处理
- celery可以进行跨机部署;可独立运行存在
- 使用delay方法发送异步任务
- 运行异步任务的方法: celery -A celery_tasks.main worker -l info
- 短信验证码存储在redis中:
- key: 手机号
- value:短信验证码的内容
- 发送短信验证码的必要条件是图形验证码必须正确!
- 在redis数据库里面会对已经发送并且存储的验证码进行标记:flag
- 如果在60s内已经发送过将不允许再次发送
-注册成功之后的返回值:username;user_id;token
2.4 JWT, token
jwt相比session的优点:不用开辟空间节省服务器空间降低压力;不需要cookie
-JWT的组成:
- header; 一般没有什么东西
- payload;可以存放任何东西;一般是username;user_id......
- signature;用来做校验的
- 如何使用JWT生成token
```
from rest_framework_jwt.settings import api_settings
jwt_payload_handler = api_settings.JWT_PAYLOAD_HANDLER
jwt_encode_handler = api_settings.JWT_ENCODE_HANDLER
payload = jwt_payload_handler(user)
token = jwt_encode_handler(payload)
```
- 自定义生成token的方法:itsdangerous
2.5 登录
- 传统登录:
obtain_jwt_token能够直接实现登录逻辑:from rest_framework_jwt.views import obtain_jwt_token
但是默认的返回值仅有token,我们还需在返回值中增加username和user_id;
所以自定制返回值支持手机号和用户名登录
- QQ登录 :
- 1. 前端调用接口向服务器发送请求;
- 服务器拼接QQ服务器的url地址返回给前端;
- 前端拿着返回的url地址请求QQ服务器弹出登录的二维码;
- 2. 用户进行扫码登录
- 3. 跳到回调地址页,并且携带两个参数:code编码;state(记录用户请求登录之前的地址)
- 4. 调用接口浏览器携带code编去换取QQ服务器端的access_token
- 5. 拿到access_token之后再次去QQ端用access_token换openid
- 5.1 拿到openid以后QQ端服务器的工作就算做完了
- 6. 查询openid 是否已经绑定:分两种情况;
- 6.1 已经绑定:直接返回token;用户登录成功
- 6.2 未绑定:也可以分两种情况:
- 6.2.1 未绑定但是数据库里面有用户的注册账号个人信息;此时绑定即可;用户登录成功
- 6.2.2 未绑定是一个全新的用户;则返回access_token;提交表单;执行绑定操作
3. 用户中心
3.1 展示用户的基本信息
- 拿到用户的基本信息可以使用:request.user
- permission_classes = [IsAuthenticated] 添加认证;必须要求用户已经通过认证才有权限访问视图
3.2 保存邮箱并发送激活链接
- 首先User用户模型类里面添加字段email_active用来表示邮箱是否激活
- 发送邮件:
- 发送邮件使用@163邮箱:发送邮件需要使用SMTP服务器
- Django中内置了邮件发送功能:from django.core.mail import send_mail
- 发送邮件同样比较耗时,所以采用celery异步任务
- 邮件发送成功之后生成激活链接;链接的url中携带的用户信息:access_token;user_id;email地址
- 用户点击激活链接完成激活;激活的时候会校验:access_token;如果激活成功会修改数据库中user模型下的email_active字段值为1
3.3 收获地址的管理
- 省市区地址查询实现三级来联动---新建地址管理表
- 继承:ViewSet 实现收获地址的增删查改
- 省市区的数据是经常被用户查询使用的,而且数据基本不变化,所以我们可以将省市区数据进行缓存处理,**减少数据库的查询次数。**
- 在Django REST framework中使用缓存,可以通过drf-extensions扩展来实现。
- 缓存方法:直接添加装饰器:@cache_response(timeout=60*60, cache='default')
- drf-extensions扩展对于缓存提供了三个扩展类:
ListCacheResponseMixin
用于缓存返回列表数据的视图,与ListModelMixin扩展类配合使用,实际是为list方法添加了cache_response装饰器
RetrieveCacheResponseMixin
用于缓存返回单一数据的视图,与RetrieveModelMixin扩展类配合使用,实际是为retrieve方法添加了cache_response装饰器
CacheResponseMixin
为视图集同时补充List和Retrieve两种缓存,与ListModelMixin和RetrieveModelMixin一起配合使用
- 所以我们直接使用CacheResponseMixin;两种的结合
timeout 缓存时间
cache 缓存使用的Django缓存后端(即CACHES配置中的键名称
4. 商品部分
4.1 商品部分表的设计:一共是11张表:2张广告表;9张商品表
商品的名称等与同类别商品相同的使用SPU来表示
商品的具体规格比如颜色外观与样子等使用SKU来表示
4.2 docker&FastDFS
tracker:调度服务器-----可以创建集群
storage:存储服务器-----也可以分为多个组
FastDFS 架构包括 Tracker server 和 Storage server
客户端请求 Tracker server 进行文 件上传、下载,通过 Tracker server 调度最终由 Storage server 完成文件上传和下载
商品部分就是需要给用户展示的具体商品的图片与样子;所以需要大量的图片存储同时还要保证加载速度;所以采用-FastDFS分布式文件系统----我们可以自定义一个文件存储系统
保存文件时候里面传入的文件的name;和文件的内容:content
上传文件的方法是通过富文本编辑器:将CKEditor 通过配置;在admin后台管理界面的CKEditor富文本编辑页面上传图片
为了实现Fast DFS能够高效便捷的使用---我们采用虚拟化技术 dockor一种容器技术
dockor由两部分组成: 镜像;容器
镜 像是Docker生命周期中的构建或者打包阶段,而容器则是启动或者执行阶段。 容器基于 镜像启动,一旦容器启动完成后,我们就可以登录到容器中安装自己需要的软件或者服务。
简单来说镜像就是我们用的系统 只有系统启动以后我们就可以在对应的容器中进行工作
4.3 页面静态化
首页页面静态化:事先将带有数据的静态化页面准备好;当用户浏览的额时候才能提高浏览效率和体验度
步骤:1. 从数据库中查询数据
2. 渲染模板
3. 写入文件
包括详情页静态化:
两者都是静态化但是时机和方式不同
首页的时机: 采用定时任任务:crontab 每隔5分钟刷新页面一次 时间可以自定义
详情页使用celery异步任务监听后台管理站点admin保存操作;当数据发生改变的时候生成静态页面的html
在测试环境中 我们可以使用脚本进行详情页面的静态化生成
4.4 浏览的历史记录
浏览历史记录以列表的list的形式保存在redis中
保存的字段:sku_id
4.5 商品的列表页
主要实现的功能是: 分页 排序
分页采用: DRF自带的分页功能
排序: 采用DRF 自带大的 Orderfilter
4.6 商品的搜素
引入搜索引擎来实现全文检索。全文检索即在指定的任意字段中进行检索查询
搜索引擎的原理
- 通过搜索引擎进行数据查询时,搜索引擎并不是直接在数据库中进行查询,而是搜索引擎会对数据库中的数据进行一遍预处理,单独建立起一份索引结构数据。
- 搜索引擎将关键字在索引数据中进行快速对比查找,进而找到数据的真实存储位置。
使用第三方工具 : ElasticSearch 采用索引的方法实现快速高效的查询
1. 开源的 Elasticsearch 是目前全文搜索引擎的首选。
2. 它可以快速地储存、搜索和分析海量数据。维基百科、Stack Overflow、Github 都采用它。
3. Elasticsearch 的底层是开源库 Lucene。但是,你没法直接用 Lucene,必须自己写代码去调用它的接口。
4. Elastic 是 Lucene 的封装,提供了 REST API 的操作接口,开箱即用。
5. Elasticsearch 是用Java实现的。
6. Elasticsearch 不支持对中文进行分词建立索引,需要配合扩展elasticsearch-analysis-ik来实现中文分词处理。
使用Docker安装Elasticsearch及其扩展
haystack:使用haystack对接Elasticsearch
1. Haystack为Django提供了模块化的搜索。它的特点是统一的,熟悉的API,可以让你在不修改代码的情况下使用不同的搜 索后端(比如 Solr, Elasticsearch, Whoosh, Xapian 等等)。
2. 在django中可以通过使用haystack来调用Elasticsearch搜索引擎。
定义索引类
创建索引类
通过创建索引类,来指明让搜索引擎对哪些字段建立索引,也就是可以通过哪些字段的关键字来检索数据。
在goods应用中新建search_indexes.py文件,用于存放索引类
from haystack import indexes
from .models import SKU
class SKUIndex(indexes.SearchIndex, indexes.Indexable):
"""
SKU索引数据模型类
"""
text = indexes.CharField(document=True, use_template=True)
id = indexes.IntegerField(model_attr='id')
name = indexes.CharField(model_attr='name')
price = indexes.DecimalField(model_attr='price')
default_image_url = indexes.CharField(model_attr='default_image_url')
comments = indexes.IntegerField(model_attr='comments')
def get_model(self):
"""返回建立索引的模型类"""
return SKU
def index_queryset(self, using=None):
"""返回要建立索引的数据查询集"""
return self.get_model().objects.filter(is_launched=True)
在SKUIndex建立的字段,都可以借助haystack由elasticsearch搜索引擎查询。
复合字段text
其中text字段我们声明为document=True,表名该字段是主要进行关键字查询的字段, 该字段的索引值可以由多个数据库模型类字段组成,具体由哪些模型类字段组成,我们用use_template=True表示后续通过模板来指明。其他字段都是通过model_attr选项指明引用数据库模型类的特定字段。
在REST framework中,索引类的字段会作为查询结果返回数据的来源。
在templates目录中创建text字段使用的模板文件
具体在templates/search/indexes/goods/sku_text.txt文件中定义
{{ object.name }}
{{ object.caption }}
{{ object.id }}
手动生成初始索引:
调用命令生成索引
python manage.py rebuild_index
创建序列化器
在goods/serializers.py中创建haystack序列化器
from drf_haystack.serializers import HaystackSerializer
class SKUIndexSerializer(HaystackSerializer):
"""
SKU索引结果数据序列化器
"""
class Meta:
index_classes = [SKUIndex]
fields = ('text', 'id', 'name', 'price', 'default_image_url', 'comments')
创建视图
在goods/views.py中创建视图
from drf_haystack.viewsets import HaystackViewSet
class SKUSearchViewSet(HaystackViewSet):
"""
SKU搜索
"""
index_models = [SKU]
serializer_class = SKUIndexSerializer
购物车部分
业务需求分析
在用户登录与未登录状态下,都可以保存用户的购物车数据
用户可以对购物车数据进行增、删、改、查
用户对于购物车数据的勾选也要保存,在订单结算页面会使用勾选数据
用户登录时,合并cookie中的购物车数据到redis中
技术实现
对于未登录的用户,购物车数据使用浏览器cookie保存
对于已登录的用户,购物车数据在后端使用Redis保存
购物车数据存储设计
- Redis保存已经登录的数据

- 因为对每个用户要保存多个商品的sku_id与其数量的对应关系,所以选择Reids的哈希类型来保存
- 对于购物车勾选的保存,只需保存勾选状态,所以可以保存勾选了的商品sku_id(此处未保存的那些在哈希数据中的商品就是未勾选的商品),对于商品的勾选需要去重,但不需要保存商品的加入顺序,所以可以选择Redis的Set类型来保存数据
- 所以在配置中需要增加一条用于保存购物车的redis的配置建立链接
使用Cookie保存未登录的用户的购物车数据
{
sku_id: {
"count": xxx, // 数量
"selected": True // 是否勾选
},
sku_id: {
"count": xxx,
"selected": False
},
...
}
在cookie中只能保存字符串数据,所以将上述数据使用pickle进行序列化转换 ,并使用base64编码为字符串,保存到cookie中。
pickle模块的使用
pickle模块是python的标准模块,提供了对于python数据的序列化操作,可以将数据转换为bytes类型,其序列化速度比json模块要高。
pickle.dumps() 将python数据序列化为bytes类型
pickle.loads() 将bytes类型数据反序列化为python的数据类型
>>> import pickle
>>> d = {'1': {'count': 10, 'selected': True}, '2': {'count': 20, 'selected': False}}
>>> s = pickle.dumps(d)
>>> s
b'\x80\x03}q\x00(X\x01\x00\x00\x001q\x01}q\x02(X\x05\x00\x00\x00countq\x03K\nX\x08\x00\x00\x00selectedq\x04\x88uX\x01\x00\x00\x002q\x05}q\x06(h\x03K\x14h\x04\x89uu.'
>>> pickle.loads(s)
{'1': {'count': 10, 'selected': True}, '2': {'count': 20, 'selected': False}}
base64模块的使用
Base64是一种基于64个可打印字符来表示二进制数据的表示方法。由于2^6=64,所以每6个比特为一个单元,对应某个可打印字符。3个字节有24个比特,对应于4个Base64单元,即3个字节可由4个可打印字符来表示。在Base64中的可打印字符包括字母A-Z、a-z、数字0-9,这样共有62个字符,此外两个可打印符号在不同的系统中而不同。
Base64常用于在通常处理文本数据的场合,表示、传输、存储一些二进制数据,包括MIME的电子邮件及XML的一些复杂数据。
python标准库中提供了base64模块,用来进行转换
base64.b64encode() 将bytes类型数据进行base64编码,返回编码后的bytes类型
base64.b64deocde() 将base64编码的bytes类型进行解码,返回解码后的bytes类型
>>> import base64
>>> s
b'\x80\x03}q\x00(X\x01\x00\x00\x001q\x01}q\x02(X\x05\x00\x00\x00countq\x03K\nX\x08\x00\x00\x00selectedq\x04\x88uX\x01\x00\x00\x002q\x05}q\x06(h\x03K\x14h\x04\x89uu.'
>>> b = base64.b64encode(s)
>>> b
b'gAN9cQAoWAEAAAAxcQF9cQIoWAUAAABjb3VudHEDSwpYCAAAAHNlbGVjdGVkcQSIdVgBAAAAMnEFfXEGKGgDSxRoBIl1dS4='
>>> base64.b64decode(b)
b'\x80\x03}q\x00(X\x01\x00\x00\x001q\x01}q\x02(X\x05\x00\x00\x00countq\x03K\nX\x08\x00\x00\x00selectedq\x04\x88uX\x01\x00\x00\x002q\x05}q\x06(h\x03K\x14h\x04\x89uu.'
添加到购物车
添加到购物车需要对用户进行登录状态的判断;分为两种情况;存储的状态也不一样;
访问接口时,无论用户是否登录,前端请求都需携带请求头Authorization,由后端判断是否登录
解决跨域请求:
因为前端可能携带cookie,为了保证跨域请求中,允许后端使用cookie,确保在配置文件有如下设置
CORS_ALLOW_CREDENTIALS = True
创建购物的序列化器:
class CartSerializer(serializers.Serializer):
"""
购物车数据序列化器
"""
sku_id = serializers.IntegerField(label='sku id ', min_value=1)
count = serializers.IntegerField(label='数量', min_value=1)
selected = serializers.BooleanField(label='是否勾选', default=True)
def validate(self, data):
try:
sku = SKU.objects.get(id=data['sku_id'])
except SKU.DoesNotExist:
raise serializers.ValidationError('商品不存在')
if data['count'] > sku.stock:
raise serializers.ValidationError('商品库存不足')
return data
解决Authorization请求头验证抛出错误:
因为前端请求时携带了Authorization请求头(主要是JWT),而如果用户未登录,此请求头的JWT无意义(没有值),为了防止REST framework框架在验证此无意义的JWT时抛出401异常,在视图中需要做两个处理
重写perform_authentication()方法,此方法是REST framework检查用户身份的方法
在获取request.user属性时捕获异常,REST framework在返回user时,会检查Authorization请求头,无效的Authorization请求头会导致抛出异常
在购物车视图中:
class CartView(APIView):
"""
购物车
"""
def perform_authentication(self, request):
"""
重写父类的用户验证方法,不在进入视图前就检查JWT
"""
pass
定义购物车数据在Cookie中保存的时间:
在carts中新建constants.py 常量文件
#购物车cookie的有效期
CART_COOKIE_EXPIRES = 365 * 24 * 60 * 60
查询购物车的数据
在carts/serializers.py中创建序列化器
class CartSKUSerializer(serializers.ModelSerializer):
"""
购物车商品数据序列化器
"""
count = serializers.IntegerField(label='数量')
selected = serializers.BooleanField(label='是否勾选')
class Meta:
model = SKU
fields = ('id', 'count', 'name', 'default_image_url', 'price', 'selected')
在carts/views.py 中修改视图,增加get方法
class CartView(APIView):
...
def get(self, request):
"""
获取购物车
"""
try:
user = request.user
except Exception:
user = None
if user is not None and user.is_authenticated:
# 用户已登录,从redis中读取
redis_conn = get_redis_connection('cart')
redis_cart = redis_conn.hgetall('cart_%s' % user.id)
redis_cart_selected = redis_conn.smembers('cart_selected_%s' % user.id)
cart = {}
for sku_id, count in redis_cart.items():
cart[int(sku_id)] = {
'count': int(count),
'selected': sku_id in redis_cart_selected
}
else:
# 用户未登录,从cookie中读取
cart = request.COOKIES.get('cart')
if cart is not None:
cart = pickle.loads(base64.b64decode(cart.encode()))
else:
cart = {}
# 遍历处理购物车数据
skus = SKU.objects.filter(id__in=cart.keys())
for sku in skus:
sku.count = cart[sku.id]['count']
sku.selected = cart[sku.id]['selected']
serializer = CartSKUSerializer(skus, many=True)
return Response(serializer.data)
修改购物车的数据
在carts/views.py中修改视图,添加put方法
class CartView(APIView):
...
def put(self, request):
"""
修改购物车数据
"""
serializer = CartSerializer(data=request.data)
serializer.is_valid(raise_exception=True)
sku_id = serializer.validated_data.get('sku_id')
count = serializer.validated_data.get('count')
selected = serializer.validated_data.get('selected')
# 尝试对请求的用户进行验证
try:
user = request.user
except Exception:
# 验证失败,用户未登录
user = None
if user is not None and user.is_authenticated:
# 用户已登录,在redis中保存
redis_conn = get_redis_connection('cart')
pl = redis_conn.pipeline()
pl.hset('cart_%s' % user.id, sku_id, count)
if selected:
pl.sadd('cart_selected_%s' % user.id, sku_id)
else:
pl.srem('cart_selected_%s' % user.id, sku_id)
pl.execute()
return Response(serializer.data)
else:
# 用户未登录,在cookie中保存
# 使用pickle序列化购物车数据,pickle操作的是bytes类型
cart = request.COOKIES.get('cart')
if cart is not None:
cart = pickle.loads(base64.b64decode(cart.encode()))
else:
cart = {}
cart[sku_id] = {
'count': count,
'selected': selected
}
cookie_cart = base64.b64encode(pickle.dumps(cart)).decode()
response = Response(serializer.data)
# 设置购物车的cookie
# 需要设置有效期,否则是临时cookie
response.set_cookie('cart', cookie_cart, max_age=constants.CART_COOKIE_EXPIRES)
return response
删除购物车的数据
在carts/serializers.py 中新建序列化器
class CartDeleteSerializer(serializers.Serializer):
"""
删除购物车数据序列化器
"""
sku_id = serializers.IntegerField(label='商品id', min_value=1)
def validate_sku_id(self, value):
try:
sku = SKU.objects.get(id=value)
except SKU.DoesNotExist:
raise serializers.ValidationError('商品不存在')
return value
在carts/views.py 中修改视图,增加delete方法
class CartView(APIView):
...
def delete(self, request):
"""
删除购物车数据
"""
serializer = CartDeleteSerializer(data=request.data)
serializer.is_valid(raise_exception=True)
sku_id = serializer.validated_data['sku_id']
try:
user = request.user
except Exception:
# 验证失败,用户未登录
user = None
if user is not None and user.is_authenticated:
# 用户已登录,在redis中保存
redis_conn = get_redis_connection('cart')
pl = redis_conn.pipeline()
pl.hdel('cart_%s' % user.id, sku_id)
pl.srem('cart_selected_%s' % user.id, sku_id)
pl.execute()
return Response(status=status.HTTP_204_NO_CONTENT)
else:
# 用户未登录,在cookie中保存
response = Response(status=status.HTTP_204_NO_CONTENT)
# 使用pickle序列化购物车数据,pickle操作的是bytes类型
cart = request.COOKIES.get('cart')
if cart is not None:
cart = pickle.loads(base64.b64decode(cart.encode()))
if sku_id in cart:
del cart[sku_id]
cookie_cart = base64.b64encode(pickle.dumps(cart)).decode()
# 设置购物车的cookie
# 需要设置有效期,否则是临时cookie
response.set_cookie('cart', cookie_cart, max_age=constants.CART_COOKIE_EXPIRES)
return response
购物车全选
在carts/serializers.py中新建序列化器
class CartSelectAllSerializer(serializers.Serializer):
"""
购物车全选
"""
selected = serializers.BooleanField(label='全选')
在carts/views.py中新建视图
class CartSelectAllView(APIView):
"""
购物车全选
"""
def perform_authentication(self, request):
"""
重写父类的用户验证方法,不在进入视图前就检查JWT
"""
pass
def put(self, request):
serializer = CartSelectAllSerializer(data=request.data)
serializer.is_valid(raise_exception=True)
selected = serializer.validated_data['selected']
try:
user = request.user
except Exception:
# 验证失败,用户未登录
user = None
if user is not None and user.is_authenticated:
# 用户已登录,在redis中保存
redis_conn = get_redis_connection('cart')
cart = redis_conn.hgetall('cart_%s' % user.id)
sku_id_list = cart.keys()
if selected:
# 全选
redis_conn.sadd('cart_selected_%s' % user.id, *sku_id_list)
else:
# 取消全选
redis_conn.srem('cart_selected_%s' % user.id, *sku_id_list)
return Response({'message': 'OK'})
else:
# cookie
cart = request.COOKIES.get('cart')
response = Response({'message': 'OK'})
if cart is not None:
cart = pickle.loads(base64.b64decode(cart.encode()))
for sku_id in cart:
cart[sku_id]['selected'] = selected
cookie_cart = base64.b64encode(pickle.dumps(cart)).decode()
# 设置购物车的cookie
# 需要设置有效期,否则是临时cookie
response.set_cookie('cart', cookie_cart, max_age=constants.CART_COOKIE_EXPIRES)
return response
合并购物车
在用户登录时,将cookie中的购物车数据合并到redis中,并清除cookie中的购物车数据。
普通登录和QQ登录都要合并,所以将合并逻辑放到公共函数里实现。
在carts/utils.py中创建merge_cart_cookie_to_redis方法
略。。。。。。。。
修改登录视图
rest_framework_jwt提供的obtain_jwt_token视图,实际从rest_framework_jwt.views.ObtainJSONWebToken类视图而来,我们可以重写此类视图里的post方法来添加合并逻辑
from rest_framework_jwt.views import ObtainJSONWebToken
class UserAuthorizeView(ObtainJSONWebToken):
"""
用户认证
"""
def post(self, request, *args, **kwargs):
# 调用父类的方法,获取drf jwt扩展默认的认证用户处理结果
response = super().post(request, *args, **kwargs)
# 仿照drf jwt扩展对于用户登录的认证方式,判断用户是否认证登录成功
# 如果用户登录认证成功,则合并购物车
serializer = self.get_serializer(data=request.data)
if serializer.is_valid():
user = serializer.validated_data.get('user')
response = merge_cart_cookie_to_redis(request, user, response)
return response
修改QQ登录视图
修改oauth/serializers.py中的序列化器
**class OAuthQQUserSerializer(serializers.ModelSerializer):
...
def create(self, validated_data):
...
# 向视图对象中补充user对象属性,以便在视图中使用user
self.context['view'].user = user
return user**
订单部分
订单部分需要对数据库进行设计
分为两张表:
一张是订单的基本信息
另一张是订单商品
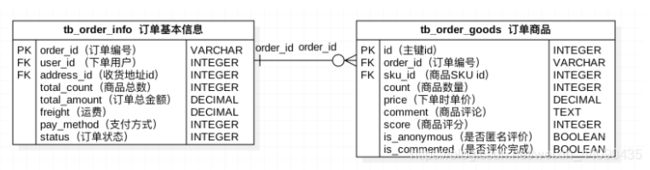
订单号不再采用数据库自增主键,而是由后端生成创建。
创建订单应用orders,编辑模型类models.py
from django.db import models
from meiduo_mall.utils.models import BaseModel
from users.models import User, Address
from goods.models import SKU
# Create your models here.
class OrderInfo(BaseModel):
"""
订单信息
"""
PAY_METHODS_ENUM = {
"CASH": 1,
"ALIPAY": 2
}
PAY_METHOD_CHOICES = (
(1, "货到付款"),
(2, "支付宝"),
)
ORDER_STATUS_ENUM = {
"UNPAID": 1,
"UNSEND": 2,
"UNRECEIVED": 3,
"UNCOMMENT": 4,
"FINISHED": 5
}
ORDER_STATUS_CHOICES = (
(1, "待支付"),
(2, "待发货"),
(3, "待收货"),
(4, "待评价"),
(5, "已完成"),
(6, "已取消"),
)
order_id = models.CharField(max_length=64, primary_key=True, verbose_name="订单号")
user = models.ForeignKey(User, on_delete=models.PROTECT, verbose_name="下单用户")
address = models.ForeignKey(Address, on_delete=models.PROTECT, verbose_name="收获地址")
total_count = models.IntegerField(default=1, verbose_name="商品总数")
total_amount = models.DecimalField(max_digits=10, decimal_places=2, verbose_name="商品总金额")
freight = models.DecimalField(max_digits=10, decimal_places=2, verbose_name="运费")
pay_method = models.SmallIntegerField(choices=PAY_METHOD_CHOICES, default=1, verbose_name="支付方式")
status = models.SmallIntegerField(choices=ORDER_STATUS_CHOICES, default=1, verbose_name="订单状态")
class Meta:
db_table = "tb_order_info"
verbose_name = '订单基本信息'
verbose_name_plural = verbose_name
class OrderGoods(BaseModel):
"""
订单商品
"""
SCORE_CHOICES = (
(0, '0分'),
(1, '20分'),
(2, '40分'),
(3, '60分'),
(4, '80分'),
(5, '100分'),
)
order = models.ForeignKey(OrderInfo, related_name='skus', on_delete=models.CASCADE, verbose_name="订单")
sku = models.ForeignKey(SKU, on_delete=models.PROTECT, verbose_name="订单商品")
count = models.IntegerField(default=1, verbose_name="数量")
price = models.DecimalField(max_digits=10, decimal_places=2, verbose_name="单价")
comment = models.TextField(default="", verbose_name="评价信息")
score = models.SmallIntegerField(choices=SCORE_CHOICES, default=5, verbose_name='满意度评分')
is_anonymous = models.BooleanField(default=False, verbose_name='是否匿名评价')
is_commented = models.BooleanField(default=False, verbose_name='是否评价了')
class Meta:
db_table = "tb_order_goods"
verbose_name = '订单商品'
verbose_name_plural = verbose_name
订单的结算
订单结算页面所需的数据从购物车中勾选而来。
在orders/serialziers.py中创建序列化器
class CartSKUSerializer(serializers.ModelSerializer):
"""
购物车商品数据序列化器
"""
count = serializers.IntegerField(label='数量')
class Meta:
model = SKU
fields = ('id', 'name', 'default_image_url', 'price', 'count')
class OrderSettlementSerializer(serializers.Serializer):
"""
订单结算数据序列化器
"""
freight = serializers.DecimalField(label='运费', max_digits=10, decimal_places=2)
skus = CartSKUSerializer(many=True)
在orders/views.py中编写视图
class OrderSettlementView(APIView):
"""
订单结算
"""
permission_classes = [IsAuthenticated]
def get(self, request):
"""
获取
"""
user = request.user
# 从购物车中获取用户勾选要结算的商品信息
redis_conn = get_redis_connection('cart')
redis_cart = redis_conn.hgetall('cart_%s' % user.id)
cart_selected = redis_conn.smembers('cart_selected_%s' % user.id)
cart = {}
for sku_id in cart_selected:
cart[int(sku_id)] = int(redis_cart[sku_id])
# 查询商品信息
skus = SKU.objects.filter(id__in=cart.keys())
for sku in skus:
sku.count = cart[sku.id]
# 运费
freight = Decimal('10.00')
serializer = OrderSettlementSerializer({'freight': freight, 'skus': skus})
return Response(serializer.data)
保存订单
在orders/views.py中创建视图
class SaveOrderView(CreateAPIView):
"""
保存订单
"""
permission_classes = [IsAuthenticated]
serializer_class = SaveOrderSerializer
在orders/serializers.py中创建序列化器
class SaveOrderSerializer(serializers.ModelSerializer):
"""
下单数据序列化器
"""
class Meta:
model = OrderInfo
fields = ('order_id', 'address', 'pay_method')
read_only_fields = ('order_id',)
extra_kwargs = {
'address': {
'write_only': True,
'required': True,
},
'pay_method': {
'write_only': True,
'required': True
}
}
def create(self, validated_data):
"""保存订单"""
pass
保存订单的思路
def create(self, validated_data):
# 获取当前下单用户
# 生成订单编号
# 保存订单基本信息数据 OrderInfo
# 从redis中获取购物车结算商品数据
# 遍历结算商品:
# 判断商品库存是否充足
# 减少商品库存,增加商品销量
# 保存订单商品数据
# 在redis购物车中删除已计算商品数据
数据库事务
在保存订单数据中,涉及到多张表(OrderInfo、OrderGoods、SKU)的数据修改,对这些数据的修改应该是一个整体事务,即要么一起成功,要么一起失败。
Django中对于数据库的事务,默认每执行一句数据库操作,便会自动提交。我们需要在保存订单中自己控制数据库事务的执行流程
在Django中可以通过django.db.transaction模块提供的atomic来定义一个事务,atomic提供两种用法
装饰器用法
from django.db import transaction
@transaction.atomic
def viewfunc(request):
# 这些代码会在一个事务中执行
...
with语句用法
from django.db import transaction
def viewfunc(request):
# 这部分代码不在事务中,会被Django自动提交
...
with transaction.atomic():
# 这部分代码会在事务中执行
...
在Django中,还提供了保存点的支持,可以在事务中创建保存点来记录数据的特定状态,数据库出现错误时,可以恢复到数据保存点的状态
from django.db import transaction
# 创建保存点
save_id = transaction.savepoint()
# 回滚到保存点
transaction.savepoint_rollback(save_id)
# 提交从保存点到当前状态的所有数据库事务操作
transaction.savepoint_commit(save_id)
保存订单数据create方法实现
def create(self, validated_data):
"""
保存订单
"""
# 获取当前下单用户
user = self.context['request'].user
# 组织订单编号 20170903153611+user.id
# timezone.now() -> datetime
order_id = timezone.now().strftime('%Y%m%d%H%M%S') + ('%09d' % user.id)
address = validated_data['address']
pay_method = validated_data['pay_method']
# 生成订单
with transaction.atomic():
# 创建一个保存点
save_id = transaction.savepoint()
try:
# 创建订单信息
order = OrderInfo.objects.create(
order_id=order_id,
user=user,
address=address,
total_count=0,
total_amount=Decimal(0),
freight=Decimal(10),
pay_method=pay_method,
status=OrderInfo.ORDER_STATUS_ENUM['UNSEND'] if pay_method == OrderInfo.PAY_METHODS_ENUM['CASH'] else OrderInfo.ORDER_STATUS_ENUM['UNPAID']
)
# 获取购物车信息
redis_conn = get_redis_connection("cart")
redis_cart = redis_conn.hgetall("cart_%s" % user.id)
cart_selected = redis_conn.smembers('cart_selected_%s' % user.id)
# 将bytes类型转换为int类型
cart = {}
for sku_id in cart_selected:
cart[int(sku_id)] = int(redis_cart[sku_id])
# 一次查询出所有商品数据
skus = SKU.objects.filter(id__in=cart.keys())
# 处理订单商品
for sku in skus:
sku_count = cart[sku.id]
# 判断库存
origin_stock = sku.stock # 原始库存
origin_sales = sku.sales # 原始销量
if sku_count > origin_stock:
transaction.savepoint_rollback(save_id)
raise serializers.ValidationError('商品库存不足')
# 用于演示并发下单
# import time
# time.sleep(5)
# 减少库存
new_stock = origin_stock - sku_count
new_sales = origin_sales + sku_count
sku.stock = new_stock
sku.sales = new_sales
sku.save()
# 累计商品的SPU 销量信息
sku.goods.sales += sku_count
sku.goods.save()
# 累计订单基本信息的数据
order.total_count += sku_count # 累计总金额
order.total_amount += (sku.price * sku_count) # 累计总额
# 保存订单商品
OrderGoods.objects.create(
order=order,
sku=sku,
count=sku_count,
price=sku.price,
)
# 更新订单的金额数量信息
order.total_amount += order.freight
order.save()
except ValidationError:
raise
except Exception as e:
logger.error(e)
transaction.savepoint_rollback(save_id)
raise
# 提交事务
transaction.savepoint_commit(save_id)
# 更新redis中保存的购物车数据
pl = redis_conn.pipeline()
pl.hdel('cart_%s' % user.id, *cart_selected)
pl.srem('cart_selected_%s' % user.id, *cart_selected)
pl.execute()
return order
并发处理
在多个用户同时发起对同一个商品的下单请求时,先查询商品库存,再修改商品库存,会出现资源竞争问题,导致库存的最终结果出现异常。

解决办法:
悲观锁
当查询某条记录时,即让数据库为该记录加锁,锁住记录后别人无法操作,使用类似如下语法
select stock from tb_sku where id=1 for update;
SKU.objects.select_for_update().get(id=1)
悲观锁类似于我们在多线程资源竞争时添加的互斥锁,容易出现死锁现象,采用不多。
乐观锁
乐观锁并不是真实存在的锁,而是在更新的时候判断此时的库存是否是之前查询出的库存,如果相同,表示没人修改,可以更新库存,否则表示别人抢过资源,不再执行库存更新。类似如下操作
update tb_sku set stock=2 where id=1 and stock=7;
SKU.objects.filter(id=1, stock=7).update(stock=2)
任务队列
将下单的逻辑放到任务队列中(如celery),将并行转为串行,所有人排队下单。比如开启只有一个进程的Celery,一个订单一个订单的处理。
需要修改MySQL的事务隔离级别
事务隔离级别指的是在处理同一个数据的多个事务中,一个事务修改数据后,其他事务何时能看到修改后的结果。
MySQL数据库事务隔离级别主要有四种:
Serializable 串行化,一个事务一个事务的执行
Repeatable read 可重复读,无论其他事务是否修改并提交了数据,在这个事务中看到的数据值始终不受其他事务影响
Read committed 读取已提交,其他事务提交了对数据的修改后,本事务就能读取到修改后的数据值
Read uncommitted 读取为提交,其他事务只要修改了数据,即使未提交,本事务也能看到修改后的数据值。
MySQL数据库默认使用可重复读( Repeatable read),而使用乐观锁的时候,如果一个事务修改了库存并提交了事务,那其他的事务应该可以读取到修改后的数据值,所以不能使用可重复读的隔离级别,应该修改为读取已提交Read committed。
在配置文件中进行修改
transaction-isolation=READ-COMMITTED
支付宝支付
创建数据库模型类
from django.db import models
from meiduo_mall.utils.models import BaseModel
from orders.models import OrderInfo
# Create your models here.
class Payment(BaseModel):
"""
支付信息
"""
order = models.ForeignKey(OrderInfo, on_delete=models.CASCADE, verbose_name='订单')
trade_id = models.CharField(max_length=100, unique=True, null=True, blank=True, verbose_name="支付编号")
class Meta:
db_table = 'tb_payment'
verbose_name = '支付信息'
verbose_name_plural = verbose_name
接入支付宝
支付宝开发平台登录
https://open.alipay.com/platform/home.htm
沙箱环境
是支付宝提供给开发者的模拟支付的环境
跟真实环境是分开的
沙箱应用:https://docs.open.alipay.com/200/105311
沙箱账号:https://openhome.alipay.com/platform/appDaily.htm?tab=account
支付宝开发者文档
文档主页:https://openhome.alipay.com/developmentDocument.htm
产品介绍:https://docs.open.alipay.com/270
快速接入:https://docs.open.alipay.com/270/105899/
SDK:https://docs.open.alipay.com/270/106291/
python对接支付宝SDK:https://github.com/fzlee/alipay/blob/master/README.zh-hans.md
python对接支付宝SDK安装:pip install python-alipay-sdk --upgrade
API列表:https://docs.open.alipay.com/270/105900/
电脑网站支付流程
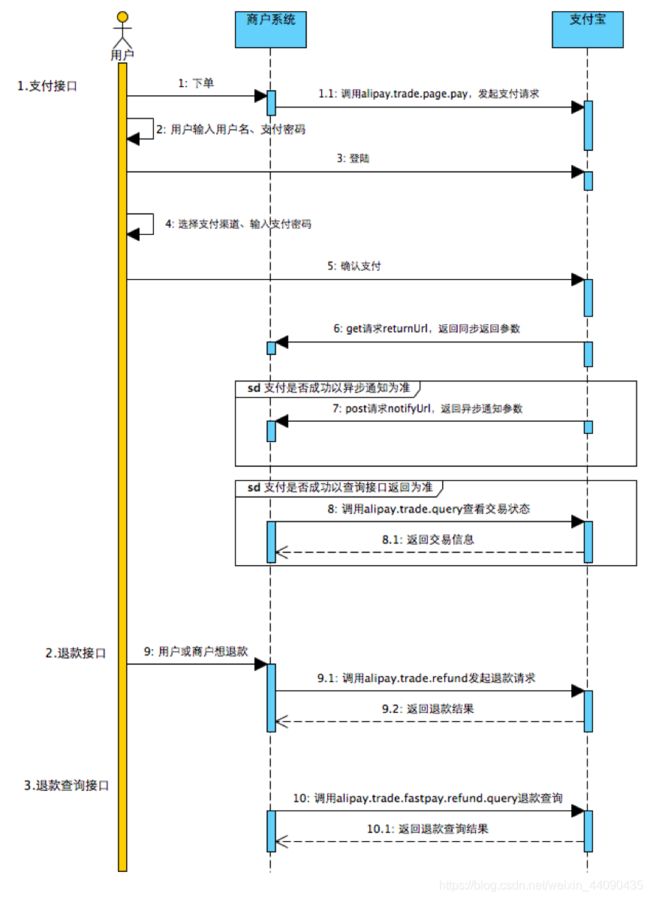
接入步骤
创建应用
配置密钥
搭建和配置开发环境
接口调用
配置秘钥
- 生成应用的私钥和公钥
openssl
OpenSSL> genrsa -out app_private_key.pem 2048 # 私钥RSA2
OpenSSL> rsa -in app_private_key.pem -pubout -out app_public_key.pem # 导出公钥
OpenSSL> exit
- 保存应用私钥文件
在payment应用中新建keys目录,用来保存秘钥文件。
将应用私钥文件app_private_key.pem复制到payment/keys目录下。
-
将公钥内容复制给支付宝
-
保存支付宝公钥
在payment/keys目录下新建alipay_public_key.pem文件,用于保存支付宝的公钥文件。
将支付宝的公钥内容复制到alipay_public_key.pem文件中
注意,还需要在公钥文件中补充开始与结束标志
-----BEGIN PUBLIC KEY-----
此处是公钥内容
-----END PUBLIC KEY-----
发起支付
在payment/views.py中创建视图
class PaymentView(APIView):
"""
支付
"""
permission_classes = (IsAuthenticated,)
def get(self, request, order_id):
"""
获取支付链接
"""
# 判断订单信息是否正确
try:
order = OrderInfo.objects.get(order_id=order_id, user=request.user,
pay_method=OrderInfo.PAY_METHODS_ENUM["ALIPAY"],
status=OrderInfo.ORDER_STATUS_ENUM["UNPAID"])
except OrderInfo.DoesNotExist:
return Response({'message': '订单信息有误'}, status=status.HTTP_400_BAD_REQUEST)
# 构造支付宝支付链接地址
alipay = AliPay(
appid=settings.ALIPAY_APPID,
app_notify_url=None, # 默认回调url
app_private_key_path=os.path.join(os.path.dirname(os.path.abspath(__file__)), "keys/app_private_key.pem"),
alipay_public_key_path=os.path.join(os.path.dirname(os.path.abspath(__file__)), "keys/alipay_public_key.pem"), # 支付宝的公钥,验证支付宝回传消息使用,不是你自己的公钥,
sign_type="RSA2", # RSA 或者 RSA2
debug=settings.ALIPAY_DEBUG # 默认False
)
order_string = alipay.api_alipay_trade_page_pay(
out_trade_no=order_id,
total_amount=str(order.total_amount),
subject="美多商城%s" % order_id,
return_url="http://www.meiduo.site:8080/pay_success.html",
)
# 需要跳转到https://openapi.alipay.com/gateway.do? + order_string
# 拼接链接返回前端
alipay_url = settings.ALIPAY_URL + "?" + order_string
return Response({'alipay_url': alipay_url})
在配置文件中编辑支付宝的配置信息
# 支付宝
ALIPAY_APPID = "2016081600258081"
ALIPAY_URL = "https://openapi.alipaydev.com/gateway.do"
ALIPAY_DEBUG = True
保存支付结果
用户支付成功后,支付宝会将用户重定向到http://www.meiduo.site:8080/pay_success.html,并携带支付结果数据
前端页面将此数据发送给后端,后端检验并保存支付结果
在payment/views.py中创建视图
class PaymentStatusView(APIView):
"""
支付结果
"""
def put(self, request):
data = request.query_params.dict()
signature = data.pop("sign")
alipay = AliPay(
appid=settings.ALIPAY_APPID,
app_notify_url=None, # 默认回调url
app_private_key_path=os.path.join(os.path.dirname(os.path.abspath(__file__)), "keys/app_private_key.pem"),
alipay_public_key_path=os.path.join(os.path.dirname(os.path.abspath(__file__)),
"keys/alipay_public_key.pem"), # 支付宝的公钥,验证支付宝回传消息使用,不是你自己的公钥,
sign_type="RSA2", # RSA 或者 RSA2
debug=settings.ALIPAY_DEBUG # 默认False
)
success = alipay.verify(data, signature)
if success:
# 订单编号
order_id = data.get('out_trade_no')
# 支付宝支付流水号
trade_id = data.get('trade_no')
Payment.objects.create(
order_id=order_id,
trade_id=trade_id
)
OrderInfo.objects.filter(order_id=order_id, status=OrderInfo.ORDER_STATUS_ENUM['UNPAID']).update(status=OrderInfo.ORDER_STATUS_ENUM["UNCOMMENT"])
return Response({'trade_id': trade_id})
else:
return Response({'message': '非法请求'}, status=status.HTTP_403_FORBIDDEN)
Xadmin
xadmin是Django的第三方扩展,可是使Django的admin站点使用更方便。
- 安装
通过如下命令安装xadmin的最新版
pip install https://github.com/sshwsfc/xadmin/tarball/master
在配置文件中注册如下应用
INSTALLED_APPS = [
…
‘xadmin’,
‘crispy_forms’,
‘reversion’,
…
]
xadmin有建立自己的数据库模型类,需要进行数据库迁移
python manage.py makemigrations
python manage.py migrate
在总路由中添加xadmin的路由信息
import xadmin
urlpatterns = [
# url(r’^admin/’, admin.site.urls),
url(r’xadmin/’, include(xadmin.site.urls)),
…
]
2. 使用
xadmin不再使用Django的admin.py,而是需要编写代码在adminx.py文件中。
xadmin的站点管理类不用继承admin.ModelAdmin,而是直接继承object即可。
在goods应用中创建adminx.py文件。
站点的全局配置
import xadmin
from xadmin import views
from . import models
class BaseSetting(object):
"""xadmin的基本配置"""
enable_themes = True # 开启主题切换功能
use_bootswatch = True
xadmin.site.register(views.BaseAdminView, BaseSetting)
class GlobalSettings(object):
"""xadmin的全局配置"""
site_title = "美多商城运营管理系统" # 设置站点标题
site_footer = "美多商城集团有限公司" # 设置站点的页脚
menu_style = "accordion" # 设置菜单折叠
xadmin.site.register(views.CommAdminView, GlobalSettings)
站点Model管理
xadmin可以使用的页面样式控制基本与Django原生的admin一直。
list_display 控制列表展示的字段
search_fields 控制可以通过搜索框搜索的字段名称,xadmin使用的是模糊查询
list_filter 可以进行过滤操作的列
ordering 默认排序的字段
readonly_fields 在编辑页面的只读字段
exclude 在编辑页面隐藏的字段
list_editable 在列表页可以快速直接编辑的字段
show_detail_fileds 在列表页提供快速显示详情信息
refresh_times 指定列表页的定时刷新
list_export 控制列表页导出数据的可选格式
show_bookmarks 控制是否显示书签功能
data_charts 控制显示图标的样式
model_icon 控制菜单的图标
自定义用户管理
xadmin会自动为admin站点添加用户User的管理配置
xadmin使用xadmin.plugins.auth.UserAdmin来配置
如果需要自定义User配置的话,需要先unregister(User),在添加自己的User配置并注册
import xadmin
# Register your models here.
from .models import User
from xadmin.plugins import auth
class UserAdmin(auth.UserAdmin):
list_display = ['id', 'username', 'mobile', 'email', 'date_joined']
readonly_fields = ['last_login', 'date_joined']
search_fields = ('username', 'first_name', 'last_name', 'email', 'mobile')
style_fields = {'user_permissions': 'm2m_transfer', 'groups': 'm2m_transfer'}
def get_model_form(self, **kwargs):
if self.org_obj is None:
self.fields = ['username', 'mobile', 'is_staff']
return super().get_model_form(**kwargs)
xadmin.site.unregister(User)
xadmin.site.register(User, UserAdmin)
用户权限控制
在产品运营平台中,是需要对用户进行权限控制的。Django实现了用户权限的控制
消费者用户与公司内部运营用户使用一个用户数据库来存储
通过is_staff 来区分是运营用户还是消费者用户
对于运营用户通过is_superuser 来区分是运营平台的管理员还是运营平台的普通用户
对于运营平台的普通用户,通过权限、组和组外权限来控制这个用户在平台上可以操作的数据。
对于权限,Django会为每个数据库表提供增、删、改、查四种权限
用户最终的权限为 组权限 + 用户特有权限
数据库读写分离
MySQL主从同步
- 主从同步的定义
主从同步使得数据可以从一个数据库服务器复制到其他服务器上,在复制数据时,一个服务器充当主服务器(master),其余的服务器充当从服务器(slave)。因为复制是异步进行的,所以从服务器不需要一直连接着主服务器,从服务器甚至可以通过拨号断断续续地连接主服务器。通过配置文件,可以指定复制所有的数据库,某个数据库,甚至是某个数据库上的某个表。
使用主从同步的好处:
(1) 通过增加从服务器来提高数据库的性能,在主服务器上执行写入和更新,在从服务器上向外提供读功能,可以动态地调整从服务器的数量,从而调整整个数据库的性能。
(2) 提高数据安全,因为数据已复制到从服务器,从服务器可以终止复制进程,所以,可以在从服务器上备份而不破坏主服务器相应数据
(3) 在主服务器上生成实时数据,而在从服务器上分析这些数据,从而提高主服务器的性能
- 主从同步的机制
Mysql服务器之间的主从同步是基于二进制日志机制,主服务器使用二进制日志来记录数据库的变动情况,从服务器通过读取和执行该日志文件来保持和主服务器的数据一致。
在使用二进制日志时,主服务器的所有操作都会被记录下来,然后从服务器会接收到该日志的一个副本。从服务器可以指定执行该日志中的哪一类事件(譬如只插入数据或者只更新数据),默认会执行日志中的所有语句。
每一个从服务器会记录关于二进制日志的信息:文件名和已经处理过的语句,这样意味着不同的从服务器可以分别执行同一个二进制日志的不同部分,并且从服务器可以随时连接或者中断和服务器的连接。
主服务器和每一个从服务器都必须配置一个唯一的ID号(在my.cnf文件的[mysqld]模块下有一个server-id配置项),另外,每一个从服务器还需要通过CHANGE MASTER TO语句来配置它要连接的主服务器的ip地址,日志文件名称和该日志里面的位置(这些信息存储在主服务器的数据库里)
- 配置主从同步的基本步骤
有很多种配置主从同步的方法,可以总结为如下的步骤:
(1) 在主服务器上,必须开启二进制日志机制和配置一个独立的ID
(2) 在每一个从服务器上,配置一个唯一的ID,创建一个用来专门复制主服务器数据的账号
(3) 在开始复制进程前,在主服务器上记录二进制文件的位置信息
(4) 如果在开始复制之前,数据库中已经有数据,就必须先创建一个数据快照(可以使用mysqldump导出数据库,或者直接复制数据文件)
(5) 配置从服务器要连接的主服务器的IP地址和登陆授权,二进制日志文件名和位置
- 详细配置主从同步的方法
1)安装mysql
我们在ubuntu中已经有安装一台mysql了,现在使用docker安装另外一台mysql
获取mysql的镜像,主从同步尽量保证多台mysql的版本相同,我们的ubuntu中存在的mysql是5.7.22版本,所以获取5.7.22版本的镜像
docker image pull mysql:5.7.22
或
docker load -i mysql_docker_5722.tar
运行mysql docker镜像,需要在宿主机中建立文件目录用于mysql容器保存数据和读取配置文件。
在家目录中(/home/python)中创建目录,将mysql的配置文件放到此目录中
cd ~
mkdir mysql_slave
cd mysql_slave
mkdir data
cp -r /etc/mysql/mysql.conf.d ./
我们要将docker运行的mysql作为slave来运行,开启前需要修改配置文件。
编辑 ~/mysql_slave/mysql.conf.d/mysqld.cnf 文件,修改
port = 8306
general_log = 0
server-id = 2
我们让此台mysql运行在8306端口上,且mysql编号为2
创建docker容器
docker run --name mysql-slave -e MYSQL_ROOT_PASSWORD=mysql -d --network=host -v /home/python/mysql_slave/data:/var/lib/mysql -v /home/python/mysql_slave/mysql.conf.d:/etc/mysql/mysql.conf.d mysql:5.7.22
MYSQL_ROOT_PASSWORD 是创建mysql root用户的密码
测试,在ubuntu中使用mysql命令尝试连接docker容器中的mysql
mysql -uroot -pmysql -h 127.0.0.1 --port=8306
2)备份主服务器原有数据到从服务器
如果在设置主从同步前,主服务器上已有大量数据,可以使用mysqldump进行数据备份并还原到从服务器以实现数据的复制。
在主服务器Ubuntu上进行备份,执行命令:
mysqldump -uroot -pmysql --all-databases --lock-all-tables > ~/master_db.sql
-u :用户名
-p :示密码
–all-databases :导出所有数据库
–lock-all-tables :执行操作时锁住所有表,防止操作时有数据修改
~/master_db.sql :导出的备份数据(sql文件)位置,可自己指定
在docker容器中导入数据
mysql -uroot -pmysql -h127.0.0.1 --port=8306 < ~/master_db.sql
3)配置主服务器master(Ubuntu中的MySQL)
编辑设置mysqld的配置文件,设置log_bin和server-id
sudo vim /etc/mysql/mysql.conf.d/mysqld.cnf
重启mysql服务
sudo service mysql restart
登入主服务器Ubuntu中的mysql,创建用于从服务器同步数据使用的帐号
mysql –uroot –pmysql
GRANT REPLICATION SLAVE ON . TO ‘slave’@’%’ identified by ‘slave’;
FLUSH PRIVILEGES;
File为使用的日志文件名字,Position为使用的文件位置,这两个参数须记下,配置从服务器时会用到。
4)配置从服务器slave (docker中的mysql)
进入docker中的mysql
mysql -uroot -pmysql -h 127.0.0.1 --port=8306
执行
change master to master_host=‘127.0.0.1’, master_user=‘slave’, master_password=‘slave’,master_log_file=‘mysql-bin.000006’, master_log_pos=590;
master_host:主服务器Ubuntu的ip地址
master_log_file: 前面查询到的主服务器日志文件名
master_log_pos: 前面查询到的主服务器日志文件位置
启动slave服务器,并查看同步状态
部署

- 静态文件
当Django运行在生产模式时,将不再提供静态文件的支持,需要将静态文件交给静态文件服务器。
我们先收集所有静态文件。项目中的静态文件除了我们使用的front_end_pc中之外,django本身还有自己的静态文件,如果rest_framework、xadmin、admin、ckeditor等。我们需要收集这些静态文件,集中一起放到静态文件服务器中。
我们要将收集的静态文件放到front_end_pc目录下的static目录中,所以先创建目录static。
Django提供了收集静态文件的方法。先在配置文件中配置收集之后存放的目录
STATIC_ROOT = os.path.join(os.path.dirname(os.path.dirname(BASE_DIR)), ‘front_end_pc/static’)
然后执行收集命令
python manage.py collectstatic
我们使用Nginx服务器作为静态文件服务器
打开Nginx的配置文件
sudo vim /usr/local/nginx/conf/nginx.conf
在server部分中配置
server {
listen 80;
server_name www.meiduo.site;
location / {
root /home/python/Desktop/front_end_pc;
index index.html index.htm;
}
# 余下省略
}
重启Nginx服务器
sudo /usr/local/nginx/sbin/nginx -s reload
首次启动nginx服务器
sudo /usr/local/nginx/sbin/nginx
停止nginx服务器
sudo /usr/local/nginx/sbin/nginx -s stop
2. 动态接口
在项目中复制开发配置文件dev.py 到生产配置prod.py
修改配置文件prod.py中
DEBUG = True
ALLOWED_HOSTS = [..., 'www.meiduo.site'] # 添加www.meiduo.site
CORS_ORIGIN_WHITELIST = (
'127.0.0.1:8080',
'localhost:8080',
'www.meiduo.site:8080',
'api.meiduo.site:8000',
'www.meiduo.site', # 添加
)
修改wsgi.py文件
os.environ.setdefault(“DJANGO_SETTINGS_MODULE”, “meiduo_mall.settings.prod”)
django的程序通常使用uwsgi服务器来运行
安装uwsgi
pip install uwsgi
在项目目录/meiduo_mall 下创建uwsgi配置文件 uwsgi.ini
[uwsgi]
#使用nginx连接时使用,Django程序所在服务器地址
socket=10.211.55.2:8001
#直接做web服务器使用,Django程序所在服务器地址
#http=10.211.55.2:8001
#项目目录
chdir=/Users/delron/Desktop/meiduo/meiduo_mall
#项目中wsgi.py文件的目录,相对于项目目录
wsgi-file=meiduo_mall/wsgi.py
进程数
processes=4
线程数
threads=2
uwsgi服务器的角色
master=True
存放进程编号的文件
pidfile=uwsgi.pid
日志文件,因为uwsgi可以脱离终端在后台运行,日志看不见。我们以前的runserver是依赖终端的
daemonize=uwsgi.log
指定依赖的虚拟环境
virtualenv=/Users/delron/.virtualenv/meiduo
启动uwsgi服务器
uwsgi --ini uwsgi.ini
注意如果想要停止服务器,除了可以使用kill命令之外,还可以通过
uwsgi --stop uwsgi.pid
修改Nginx配置文件,让Nginx接收到请求后转发给uwsgi服务器
upstream meiduo {
server 10.211.55.2:8001; # 此处为uwsgi运行的ip地址和端口号
# 如果有多台服务器,可以在此处继续添加服务器地址
}
#gzip on;
server {
listen 8000;
server_name api.meiduo.site;
location / {
include uwsgi_params;
uwsgi_pass meiduo;
}
}
server {
listen 80;
server_name www.meiduo.site;
#charset koi8-r;
#access_log logs/host.access.log main;
location /xadmin {
include uwsgi_params;
uwsgi_pass meiduo;
}
location /ckeditor {
include uwsgi_params;
uwsgi_pass meiduo;
}
location / {
root /home/python/Desktop/front_end_pc;
index index.html index.htm;
}
error_page 500 502 503 504 /50x.html;
location = /50x.html {
root html;
}
}
重启nginx
sudo /usr/local/nginx/sbin/nginx -s reload