跳跃表(Skip list)原理
前言
Redis大家可能都很很熟悉了吧,它有五种数据结构如下:
- String:字符串
- Hash:字典
- List:列表
- Set:集合
- Sorted Set:有序集合
这里我们就讲讲Sorted Set,它是一个 set 保证了内部 value 的唯一性,另一方面又可以给每个 value 赋予一个排序的权重值 score,来达到 排序 的目的。它的内部实现就依赖了一种叫做 「跳跃列表」 的数据结构。
为什么要有跳跃表
我们在实际开发中经常会有在一堆数据中查找一个指定数据的需求,而常用的支持高效查找算法的实现方式有以下几种:
-
有序数组。这种方式的存储结构,优点是支持数据的随机访问,并且可以采用二分查找算法降低查找操作的复杂度。缺点同样很明显,插入和删除数据时,为了保持元素的有序性,需要进行大量的移动数据的操作。
-
二叉查找树。如果需要一个既支持高效的二分查找算法,又能快速的进行插入和删除操作的数据结构,那首先就是二叉查找树莫属了。缺点是在某些极端情况下,二叉查找树有可能变成一个线性链表。
-
平衡二叉树。二叉树表示不服,于是基于二叉查找树的优点,对其缺点进行改进,引入了平衡的概念。根据平衡算法的不同,具体实现有AVL树 /
B树(B-Tree) / B+树(B+Tree) / 红黑树 等等。但是平衡二叉树的实现多数比较复杂,较难理解。 -
跳跃表。同样支持对数据进行高效的查找,插入和删除数据操作也比较简单,最重要的就是实现比较平衡二叉树真是轻量几个数量级。缺点就是存在一定数据冗余。
PS: 网上看到很多文章说B树/B-树 / B+树 的,这是不正确的。没有B-树之说,英文资料中只存在B-Tree和B+Tree,然后翻译到中文,就把B-Tree翻译成了B-树,中间的“-”其实只是一个分隔号,并不是减号。
什么是跳跃表
跳跃表(skiplist)是一个用于有序元素序列快速搜索的随机化的数据结构,由美国计算机科学家William Pugh发明于1989年,论文《Skip lists: a probabilistic alternative to balanced trees》。
它的效率和红黑树以及 AVL 树不相上下,但实现起来比较容易。是一种可以于平衡树媲美的层次化链表结构——查找、删除、添加等操作都可以在对数期望时间下完成
作者William Pugh是这样介绍Skip list的:
Skip lists are a probabilistic data structure that seem likely to supplant balanced trees as the implementation method of choice for many applications. Skip list algorithms have the same asymptotic expected time bounds as balanced trees and are simpler, faster and use less space.
Skip list是一个“概率型”的数据结构,可以在很多应用场景中替代平衡树。Skip list算法与平衡树相比,有相似的渐进期望时间边界,但是它更简单,更快,使用更少的空间。
Skip list是一个分层结构多级链表,最下层是原始的链表,每个层级都是下一个层级的“高速跑道”。
跳跃表(SkipList)是一种可以替代平衡树的数据结构。跳跃表让已排序的数据分布在多层次的链表结构中,默认是将Key值升序排列的,以 0-1 的随机值决定一个数据是否能够攀升到高层次的链表中。它通过容许一定的数据冗余,达到 “以空间换时间” 的目的。
跳跃表的效率和AVL相媲美,查找/添加/插入/删除操作都能够在O(LogN)的复杂度内完成。
讲了那么多,下面就直接进入主题,详细的看一看跳跃表是怎么实现的。
跳跃表的实现
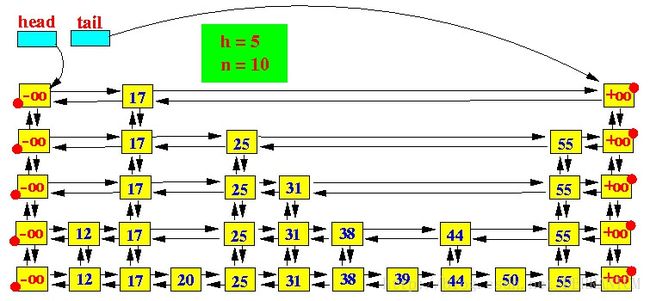
上面这张图就是一个跳跃表的实例,先说一下跳跃表的构造特征:
-
一个跳跃表应该有若干个层(Level)链表组成;
-
跳跃表中最底层的链表包含所有数据; 每一层链表中的数据都是有序的;
-
如果一个元素X出现在第i层,那么编号比 i 小的层都包含元素X;
-
第 i 层的元素通过一个指针指向下一层拥有相同值的元素;
-
在每一层中,-∞ 和 +∞两个元素都出现(分别表示INT_MIN 和 INT_MAX);
-
头指针(head)指向最高一层的第一个元素;
首先,我们需要定义链表中节点的模型

实现Map的基本操作
Map的基本操作:
-
get(String key) : 根据key值查找某个元素
-
put(String key, Integer value) :插入一个新的元素,元素已存在时为修改操作
-
remove(String key): 根据key值删除某个元素
虽然看似是3个不同的操作,但是究其本质,要实现这3个操作,都得先找到某个元素 或是 定位到一个元素,好在下一个位子插入新元素。那么,我们就先把这个findEntry的方法实现吧。

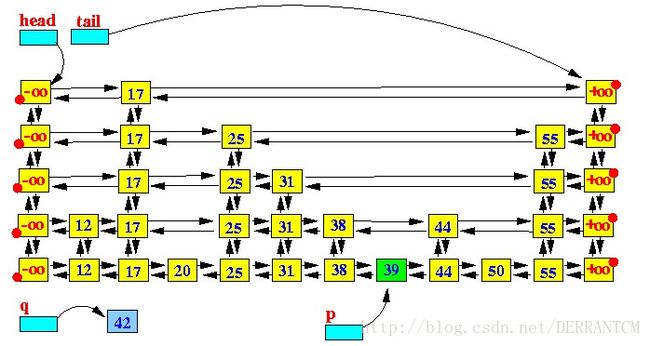
上面的图示使用紫色的箭头画出了在一个SkipList中查找key值50的过程。简述如下:
-
从head出发,因为head指向最顶层(top level)链表的开始节点,相当于从顶层开始查找;
-
移动到当前节点的右指针(right)指向的节点,直到右节点的key值大于要查找的key值时停止;
-
如果还有更低层次的链表,则移动到当前节点的下一层节点(down),如果已经处于最底层,则退出;
-
重复第2步 和 第3步,直到查找到key值所在的节点,或者不存在而退出查找;
Java代码实现如下:
private SkipListEntry findEntry(String key) {
SkipListEntry p;
// 从head头节点开始查找
p = head;
while(true) {
// 从左向右查找,直到右节点的key值大于要查找的key值
while(p.right.key != SkipListEntry.posInf
&& p.right.key.compareTo(key) <= 0) {
p = p.right;
}
// 如果有更低层的节点,则向低层移动
if(p.down != null) {
p = p.down;
} else {
break;
}
}
// 返回p,!注意这里p的key值是小于等于传入key的值的(p.key <= key)
return p;
}注意以下几点:
-
如果传入的key值在跳跃表中存在,则findEntry返回该对象的底层节点;
-
如果传入的key值在跳跃表中不存在,则findEntry返回跳跃表中key值小于key,并且key值相差最小的底层节点;
示例,在跳跃表中查找key=42的元素节点,将返回key=39的节点。如下图所示:
基于findEntry方法,我们就能很容易的实现前面所说的一些操作了。
实现get方法
public Integer get(String key) {
SkipListEntry p;
p = findEntry(key);
if(p.key.equals(key)) {
return p.value;
} else {
return null;
}
}
实现put方法
put方法有一些需要注意的步骤:
-
如果put的key值在跳跃表中存在,则进行修改操作;
-
如果put的key值在跳跃表中不存在,则需要进行新增节点的操作,并且需要由random随机数决定新加入的节点的高度(最大level);
-
当新添加的节点高度达到跳跃表的最大level,需要添加一个空白层(除了-oo和+oo没有别的节点)
下面我们一步一步的通过图示看一下插入节点的过程:

第一步,查找适合插入的位子
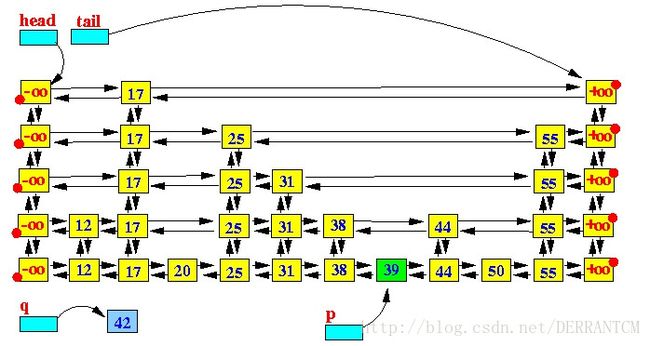
第二步,在查找到的p节点后面插入新增的节点q

第三步,重复下面的操作,使用随机数决定新增节点的高度
从p节点开始,向左移动,直到找到含有更高level节点的节点;
将p指针向上移动一个level;
创建一个和q节点data一样的节点,插入位子在跳跃表中p的右方和q的上方;
直到随机数不满足向上攀升的条件为止;
图示如下:

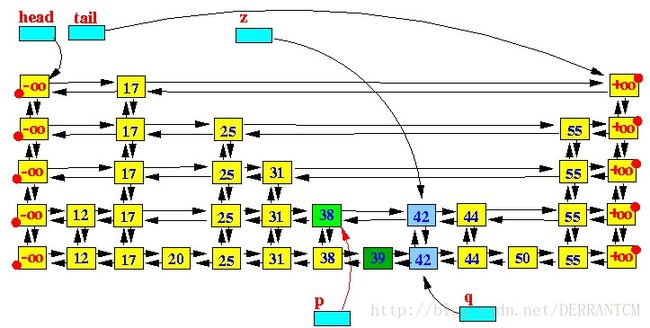

只要随机数满足条件,key=42的节点就会一直向上攀升,直到它的level等于跳跃表的高度(height)。这个时候我们需要在跳跃表的最顶层添加一个空白层,同时跳跃表的height+1,以满足下一次新增节点的操作。

参考
https://blog.csdn.net/DERRANTCM/article/details/79063312
https://www.wmyskxz.com/2020/02/29/redis-2-tiao-yue-biao/