【文献阅读】将知识蒸馏用于视觉问答VQA的紧凑三重交互(T. Do等人,ICCV,2019,有代码)
一、背景
文章题目:《Compact Trilinear Interaction for Visual Question Answering》
ICCV2019的一篇文章。
文章下载地址:http://openaccess.thecvf.com/content_ICCV_2019/papers/Do_Compact_Trilinear_Interaction_for_Visual_Question_Answering_ICCV_2019_paper.pdf
文章引用格式:T. Do, T. Do, H. Tran, E. Tjiputra, Q. D. Tran. "Compact Trilinear Interaction for Visual Question Answering." International Conference on Computer Vision (ICCV), 2019
项目地址:https://github.com/aioz-ai/ICCV19_VQA-CTI
二、文章导读
先来看一下文章的摘要部分:
In Visual Question Answering (VQA), answers have a great correlation with question meaning and visual contents. Thus, to selectively utilize image, question and answer information, we propose a novel trilinear interaction model which simultaneously learns high level associations between these three inputs. In addition, to overcome the interaction complexity, we introduce a multimodal tensor-based PARALIND decomposition which efficiently parameterizes trilinear interaction between the three inputs. Moreover, knowledge distillation is first time applied in Free form Opened-ended VQA. It is not only for reducing the computational cost and required memory but also for transferring knowledge from trilinear interaction model to bilinear interaction model. The extensive experiments on benchmarking datasets TDIUC, VQA-2.0, and Visual7W show that the proposed compact trilinear interaction model achieves state-of-the-art results when using a single model on all three datasets. The source code is available at https://github.com/aioz-ai/ICCV19_VQA-CTI.
在视觉问答中,答案和问题还有视觉内容之间有着很好的相关性。因此,为了有选择性的使用图像,问题和答案信息,我们提出了一个新的三重交互模型,该模型的学习结合了这三种输入。另外,为了解决交互的复杂性,我们引入了一个多模态基于张量的PARALIND分解。此外,知识蒸馏首次用于开放式视觉问答。它不仅能够减少计算量和内存,而且能够将三重交互中的知识转化为双线性交互。基于TDIUC, VQA-2.0, 和Visual7W数据集的实验都表明该模型达到了艺术级的 效果。所有的代码可以在下面的连接中找到: https://github.com/aioz-ai/ICCV19_VQA-CTI
三、文章详细介绍
VQA目前的两种形式,一种是开放式问答,一种是多选式问答。之前的所有VQA模型,都是先学习图像和文本两者的联合表示,再将预测答案视为一个“消极”构成(passive form),比如将其视为分类问题。然后,答案往往与输入的问题-图像之间有着很好的相关性,因此从这三种输入之间提取信息将能够更好的得到联合表示。本文依次提出了一个三重交互模型,以同时学习三种输入之间的联系。
三重交互模型的主要困难在于维度问题,它会引起计算量爆炸并占用大量内存。因此本文使用了PARALIND分解算法,将一个大的张量分解为多个小的张量。
由于三重交互模型不能直接用于开放式问答(只能训练不能测试,因为测试没有答案),为了解决这个问题,作者提出了知识蒸馏(knowledge distillation)将一个三重交互模型转化为双重交互模型,双重模型只需要输入问题和图像即可,因此可以用于开放式问答。另外三重交互模型是可以直接用于多选问答。最后对模型的评估是基于数据集TDIUC, VQA-2.0, 和Visual7W,结果说明该算法达到了艺术级的效果。
本文的主要贡献在于:
(i) We propose a novel trilinear interaction model which simultaneously learns high level joint presentation between image, question, and answer information in VQA task. (ii) We utilize PARALIND decomposition to deal with the dimensionality issue in trilinear interaction. (iii) To make the proposed trilinear interaction applicable for FFOE VQA, we propose to use knowledge distillation for transferring knowledge from trilinear interaction model to bilinear interaction model. (基本上就是前面标红的三点。)
1. 相关工作
VQA中的联合嵌入(Joint embedding in Visual Question Answering):在现有的VQA模型中,输入的问题和图像特征往往用矩阵来表示,而图像矩阵和文本矩阵之间的交互多采用矢量积,这种线性方式会极大的增加输出空间(output space),因此很多研究都常识抑制或者分解这类线性操作。作者的工作与先前的这些工作都不同,以前的这些工作都是学习两个模态之间的联合表示或者使用点积操作来简化三种模态之间的交互。而本文提出的三重交互模型则是对三种模态的联合表示,关键环节有两个,一个是三个模态之间的交互,另一个就是对其分解使其易于交互。
知识蒸馏(Knowledge Distillation):作者这里只提了下他的灵感来自于Hinton’s seminar work。
2. 紧凑的三重交互模型
(1)完全参数化的三重交互(Fully parameterized trilinear interaction):
假设M = {M1, M2, M3}是三个模态输入的联合表示,完全参数化的三重交互结果为:

其中d表示维度。其中T是一个学习到的张量,它能够帮助学习三种输入模态之间的交互。然而这个T的学习是不可行的,因为输入模态的维度都非常高,因此需要对其进行降维。
灵感来自于其他文献,作者参考了unitary attention,假设z表示来自于第p个三元组triplet的联合表示,那么z的完全参数化的三重交互结果则为:

参考unitary attention,z的近似可以用下式计算:

上式(3)其实是一个加权求和的过程,权重来自于注意力图M,M的结果来自于减少的参数化三重交互,也就是式(4)。将(2)式引入(3)式,最终的联合表示也就是:

(2)参数分解(Parameter factorization):
我们将一个很大的张量T分解为两个小张量Tm和Tsc,这两个小张量的维度仍然会使得学习的开销很大。为了进一步减少计算量,这里使用了PARALIND分解法对这两个小张量进行处理。
对于张量Tm的计算,可以有:
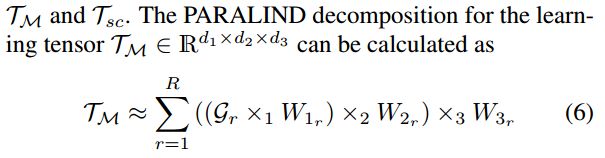
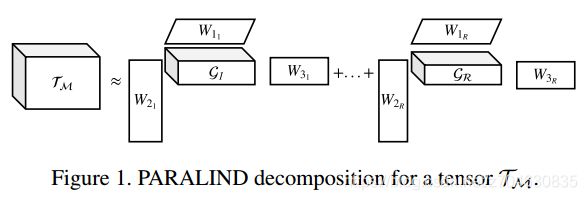
其中R是一个切割参数(slicing parameter),Gr是一个可学习的小张量,称为Tucker tensor,它的数量等于R,R的最大值一般设置为d1,d2,d3中的最大值,实验设置R=32,下图展示了PARALIND算法对Tm的分解:
上式(6)就可以被描述为:
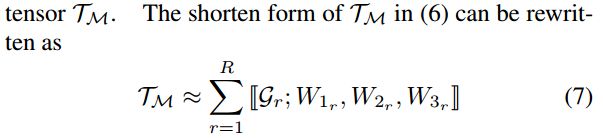
将(7)式代入(4)式,可以得到注意力图M:

对Tsc的分解和Tm类似,这里设置切割参数R=1,Tsc最终可以表达为:

利用(8)和(9)式,我们就可以计算(5)式中的z了:

注意到Gsc的秩为1,因此上式可以用点积近似:

3. 三重交互模型用于VQA
对于输入VQA的三元组(V,Q,A),我们首先计算注意力图M:

然后三元组的联合表示z就可以按照下式计算:

(1)多选式VQA
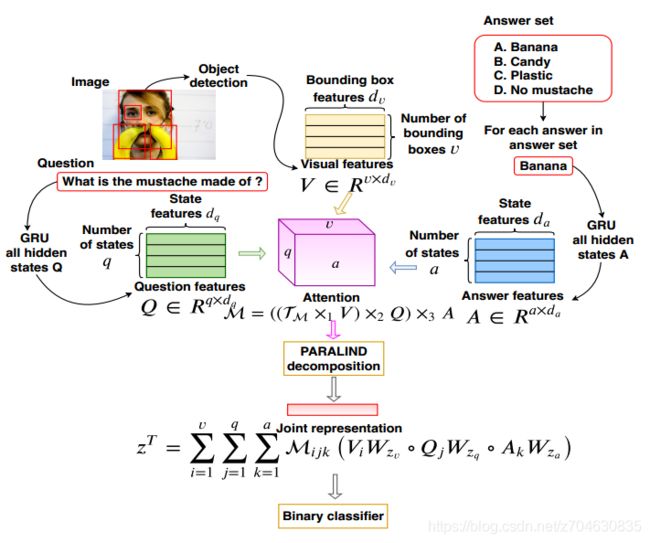
首先将每个问题或者答案的最大长度设置为12个单词,不够的用0补齐,每一个单词都用300维的GloVe词嵌入,每一张图像都表示为14*14*2048的格网特征,他们都是从ResNet-152的倒数第二个层提出来的。
输入的样本则分为正样本和负样本。正样本是有着正确答案的样本,标记为1,负样本是错误答案,标记为0。这些样本一起传入CTI以获得联合表示,这个联合表示在通过一个二值分类器来获得正确的预测结果。模型损失采用二值交叉熵。
多选式vqa的模型结构如下:
(2)开放式VQA
和多选式vqa不同的是,开放式的都是用的分类模型来获得正确答案。它的答案的情况会比多选问题多很多,而CTI需要输入的是Q-A-I,在测试的时候,是没有A的,因此这里对模型进行了改进,引入了知识蒸馏,开放式vqa的模型如下:
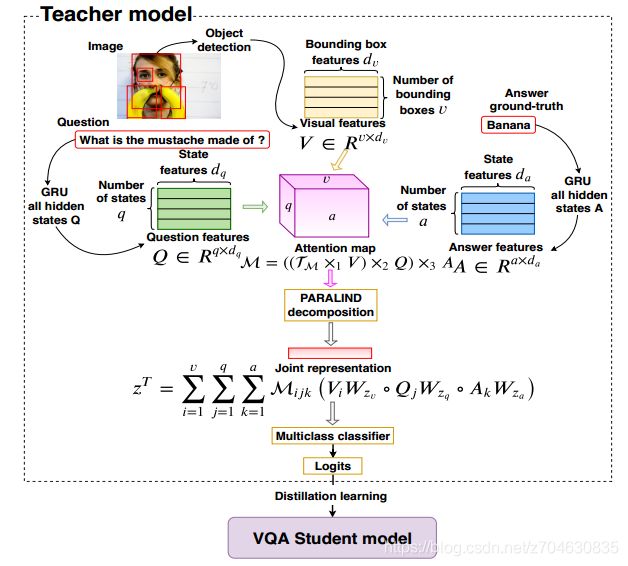
每一个teacher model都是输入的I-Q-A三元组来获得联合表示z,之后再将z传入到分类器中,teacher model中的损失采用的是交叉熵。而student model这里作者采用了BAN2和SAN,模型输入的是I-Q,然后将答案预测视为一个分类问题,student model 的损失函数定义如下:
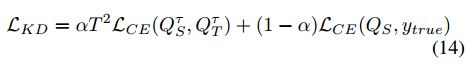
式子中的各个参数含义如下:

结合现有模型的情况,这里图像的目标检测采用的FPN detector (ResNet152 backbone),检测出的bounding boxes最大数量设置为50,对于Q-A,最大单词数量设置为12,少于12则用0补齐,每一个单词都表示为600维的向量(它和300维的Glove词嵌入连接起来获得),问题最终表示为12*600。
4. 实验
(1)数据集和评估
数据集(Dataset):实验用到的数据集有三个:Visual7W(用于多选式问答),VQA-2.0和TDIUC(用于开放式问答)。
实验细节(Implementation details):实验平台是pytorch,GPU是NVIDIA Titan V,12G显存,学习率为0.001,batch size在多选式数据集上设置128,在开放式数据集上设置256,公式(15)中的温度参数T设置为3,联合表示z的维度设置为1024.
评估方法(Evaluation Metrics):对于开放式VQA,使用了准确度;另外由于TDIUC中问题类型的不均匀,还采用了其他4种方法进行较准,分别是Arithmetic MPT(Ari),Arithmetic Norm-MPT (Ari-N),Harmonic MPT (Har),Harmonic Norm-MPT (Har-N);对于多选式vqa,评估方法采用文献【47】中提到的方法。
(2)消融实验
开放式vqa上的效果(The effectiveness of CTI on FFOE VQA):首先BAN2-CTI和distilled SAN代表蒸馏后的student model,下表展示了TDIUC上5种评价方法的效果:
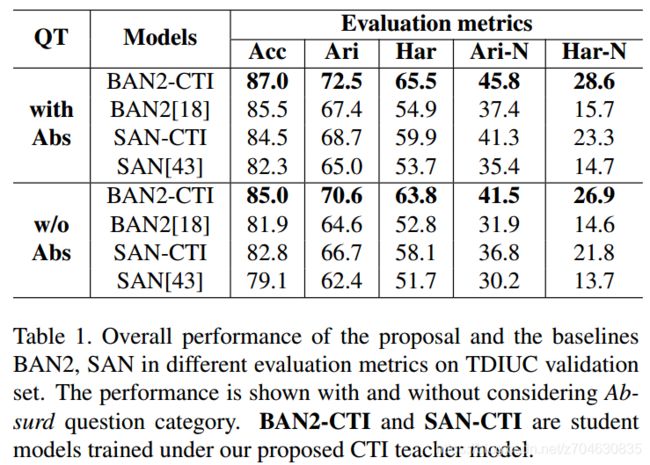
从上表看出,蒸馏后的模型BAN2-CTI和SAN-CTI都明显比原模型要好。表2是统计了TDIUC数据集种不同类型问题的精度:
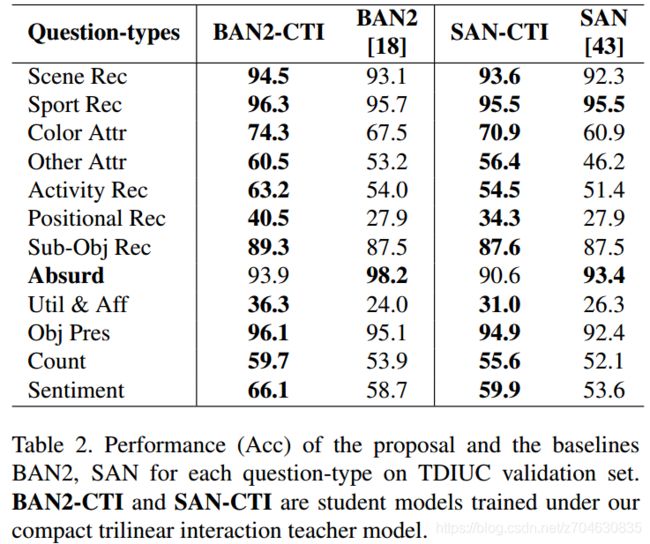
表2种只有“absurd”类型的问题表现没有原模型好。表3是student model和原模型的比较:
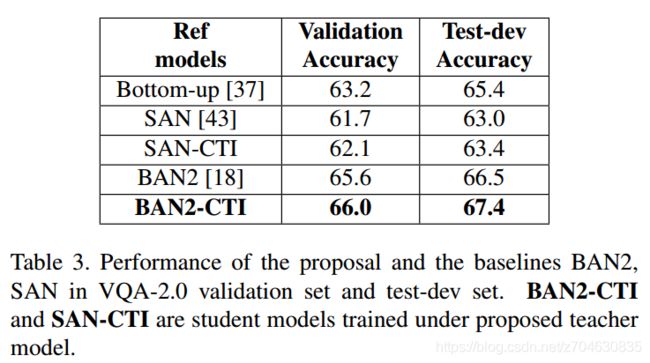
多选式vqa上的效果(The effectiveness of CTI on MC VQA):多选式vqa没有使用知识蒸馏,所以使用到的模型就是SAN和BAN2。在BAN2中,先将图像和问题进行联合表示,然后再将图像和答案进行联合表示,最后再将两种联合表示连接,以获得三元组的联合表示。
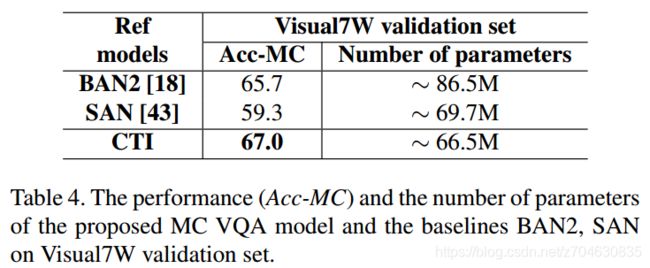
表4体现了模型在Visual7W数据集上的效果:
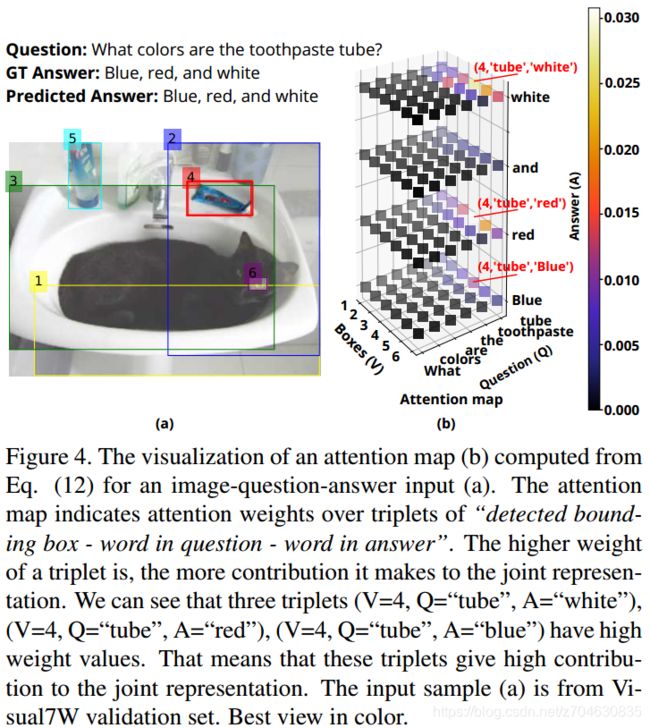
三元组的注意力可视化图如下所示:
(3)和其他模型的比较
这里参与比较的模型包括:
对于开放式vqa数据集TDIUC和VQA-2.0,参与比较的模型包括SAN [43], QTA [35], BAN2 [18], Bottom-up [37],MCB [8], RAU [29]。
对于多选式vqa数据集Visual7W,参与比较的模型包括BAN2 [18], SAN [43], MLP [16], MCB [8], STL [41], fPMC [14]。
对于开放式vqa,表3和表5分别展示了在数据集VQA-2.0和TDIUC的结果:
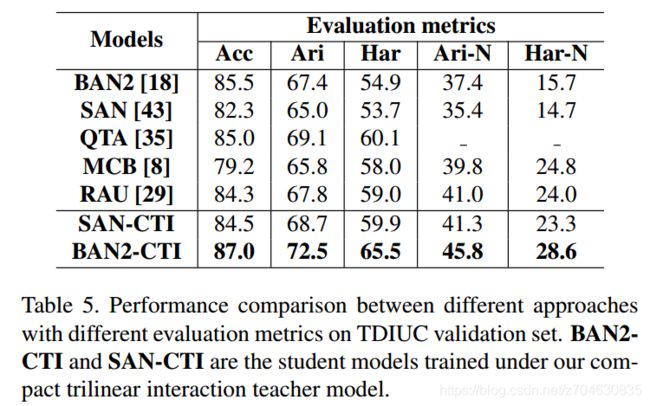
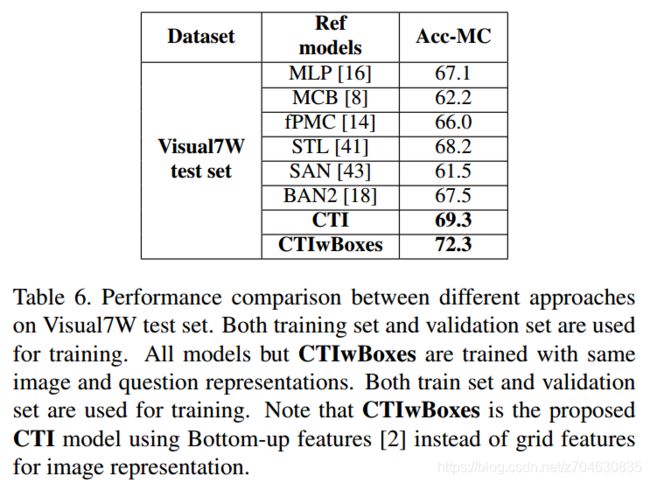
对于多选式vqa,他们的结果如表6所示:
(4)未来的研究
这里作者提到了两点:
PARALIND分解的有效性(The effectiveness of PARALIND decomposition):作者在这里提到他的分解率只有65.
三线性交互作为BAN的泛化(Compact Trilinear Interaction as the generalization of BAN):作者提到了CTI可以作为BAN的泛化情况,并给出了一些公式证明,这里不再多强调。
四、小结
这篇文献中的related work部分我觉得写的挺好,这里贴出来供写文章的时候参考:
In [8], the authors proposed the Multimodal Compact Bilinear pooling which is an efficient method to compress the bilinear interaction. The method works by projecting the visual and linguistic features to a higher dimensional space and then convolving both vectors efficiently by using element-wise product in Fast Fourier Transform space. In [5], the authors proposed Multimodal Tucker Fusion which is a tensor-based Tucker decomposition to efficiently parameterize bilinear interaction between visual and linguistic representations. In [45], the author proposed Factorized Bilinear Pooling that uses two low rank matrices to approximate the fully bilinear interaction. Recently, in [18] the authors proposed Bilinear Attention Networks (BAN) that finds bilinear attention distributions to utilize given visual-linguistic information seamlessly. BAN also uses low rank approximation to approximate the bilinear interaction for each pair of vectors from image and question.