Spark编译安装
- Spark环境搭建
权威:
http://spark.apache.org
https://github.com/apache/spark
源码
下载安装包:
(1)、官网

pre-build 预编译
我们的要求是Spark必须是自己编译的
选择源码

选tgz,就是tar.gz
(2) github


(3) git clone https://github.com/apache/spark.git
通过查看分支命令,切换到自己所需要的分支中去

- 编译

[root@hadoop001 ~]# hostname
hadoop001
[root@hadoop001 ~]# cat /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.10.30 hadoop001
[root@hadoop001 ~]#
[root@hadoop001 ~]# useradd hadoop
[root@hadoop001 ~]# su - hadoop
[hadoop@hadoop001 ~]$ mkdir app lib
安装maven
[hadoop@hadoop001 app]$ pwd
/home/hadoop/app
[hadoop@hadoop001 app]$ unzip apache-maven-3.6.1-bin.zip
添加环境变量
[hadoop@hadoop001 ~]$ cat ~/.bash_profile
export MAVEN_HOME=/home/hadoop/app/apache-maven-3.6.1
export PATH=$MAVEN_HOME/bin:$PATH
[hadoop@hadoop001 ~]$ source ~/.bash_profile
[hadoop@hadoop001 ~]$
验证
[hadoop@hadoop001 app]$ mvn -v
修改仓库地址
[hadoop@hadoop001 conf]$ cd $MAVEN_HOME
[hadoop@hadoop001 conf]$ cd conf/
[hadoop@hadoop001 conf]$ vim settings.xml
/home/hadoop/maven_repo
- 安装jdk
mkdir /usr/java # jdk部署
mkdir /usr/share/java #部署CDH需要mysql jdbc jar包
[root@hadoop001 app]# tar -xzvf jdk-8u45-linux-x64.gz -C /usr/java
权限修正
[root@hadoop001 java]# chown -R root:root jdk1.8.0_45
环境变量
[root@hadoop001 java]# vim /home/hadoop/.bash_profile
添加
export JAVA_HOME=/usr/java/jdk1.8.0_45
export JRE_HOME=$JAVA_HOME/jre
export CLASSPATH=.:$JAVA_HOME/lib:$JER_HOME/lib:$CLASSPATH
export PATH=$JAVA_HOME/bin:$JER_HOME/bin:$PATH
[root@hadoop001 java]# source /home/hadoop/.bash_profile
验证
[hadoop@hadoop001 app]$ java -version
- 安装scala
[hadoop@hadoop001 software]$ tar -zxvf scala-2.11.8.tgz -C ~/app/
环境变量
[hadoop@hadoop001 scala-2.11.8]$ vim ~/.bash_profile
添加
export SCALA_HOME=/home/hadoop/app/scala-2.11.8
export PATH=$SCALA_HOME/bin:$PATH
[hadoop@hadoop001 scala-2.11.8]$ source ~/.bash_profile
验证
[hadoop@hadoop001 scala-2.11.8]$ scala
- 安装git
[root@hadoop001 ~]# yum install -y git
- 解压spark源码
[root@hadoop001 software]# tar zxvf spark-2.4.2.tgz -C /home/hadoop/source/
[root@hadoop001 source]# chown -R hadoop.hadoop spark-2.4.2/
修改cdh的依赖,不然报错
[hadoop@hadoop001 spark-2.4.2]$ pwd
/home/hadoop/source/spark-2.4.2
[hadoop@hadoop001 spark-2.4.2]$ vim pom.xml
添加
cloudera
https://repository.cloudera.com/artifactory/cloudera-repos/

make-distribution.sh命令

这段会检查 跑的很慢,注释掉

手动改成:
VERSION=2.4.2
SCALA_VERSION=2.11
SPARK_HADOOP_VERSION=2.6.0-cdh5.7.0
SPARK_HIVE=1 #支持hive
-
编译
./dev/make-distribution.sh --name 2.6.0-cdh5.7.0 --tgz -Phadoop-2.6 -Phive -Phive-thriftserver -Pyarn -Pkubernetes -Dhadoop.version=2.6.0-cdh5.7.0
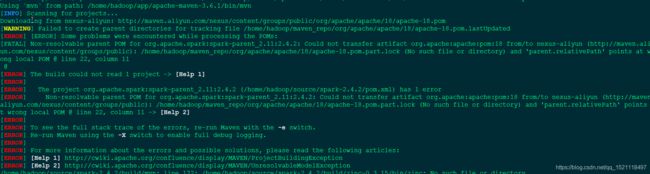
一开始编译报错,把maven包和spark源码包 删除,重新解压,目录权限改为hadoop.hadoop
[hadoop@hadoop001 source]$ chown -R hadoop.hadoop spark-2.4.2/
[hadoop@hadoop001 ~]$ chown -R hadoop.hadoop maven_repo/
说明:只要是hadoop家目录下的最好都改为hadoop.hadoop权限
出现下图表示编译完成


编译后的包


- 解压
[hadoop@hadoop001 spark-2.4.2]$ tar -zxvf spark-2.4.2-bin-2.6.0-cdh5.7.0.tgz -C ~/app
[hadoop@hadoop001 spark-2.4.2-bin-2.6.0-cdh5.7.0]$ vim ~/.bash_profile
添加环境变量
export SPARK_HOME=/home/hadoop/app/spark-2.4.2-bin-2.6.0-cdh5.7.0
export PATH=$SPARK_HOME/bin/:$PATH
export SPARK_CONF_DIR=$SPARK_HOME/conf
[hadoop@hadoop001 spark-2.4.2-bin-2.6.0-cdh5.7.0]$ source ~/.bash_profile
常用命令
$SPARK_HOME/bin
spark-shell
spark-submit
beeline
spark-sql
启动
[hadoop@hadoop001 spark-2.4.2-bin-2.6.0-cdh5.7.0]$ cd bin/
[hadoop@hadoop001 bin]$ ./spark-shell
