【目录结构】
- Java基础
- 1,Java语言的特点
- 2,配置开发环境
- 3,经典HelloWorld
- 3.1 命令行运行Java程序
- 3.2 使用IDEA 运行Java程序
- 4,数据类型&变量
- 4.1 为什么要设计不同种类的数据类型?
- 4.2 数据变量&类型的定义
- 4.3 基本数据类型
- 4.4 自动类型转换&强制类型转换
- 4.5 包装类
- 面向对象
- 1,灵魂拷问,什么是面向对象?
- 2,如何实现面向对象?——封装,继承,多态
- 2.1 封装
- 2.2 继承
- 2.3 多态
- 3,关键字盘点
- 3.1 static
- 3.2 final
Java基础
1,Java语言的特点
- 基于JVM的跨平台语言
- 具有垃圾回收机制
- 生态强大
2,配置开发环境
JDK版本多样,主要包括Oracle JDK 和OpenJDK
支持国产的话可以考虑阿里的dragonwell:https://cn.aliyun.com/product/dragonwell
【win10安装JDK的常用步骤】
- jdk8下载地址:
https://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html
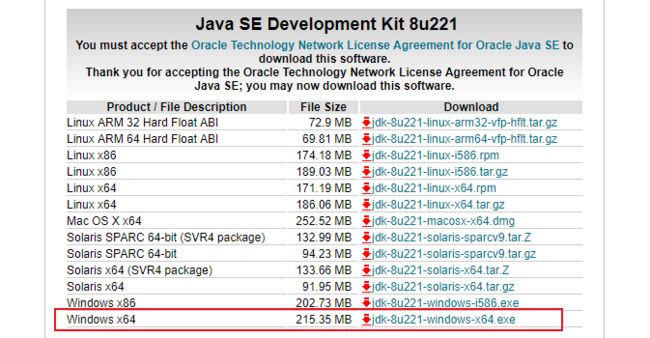
【下载的这个安装包主要包含JDK,JRE,JavaFx包】(JavaFX主要用于桌面端开发)
- 设置jdk安装路径
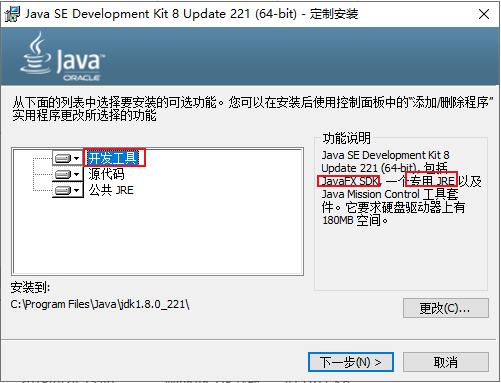
- 设置jre安装路径
-
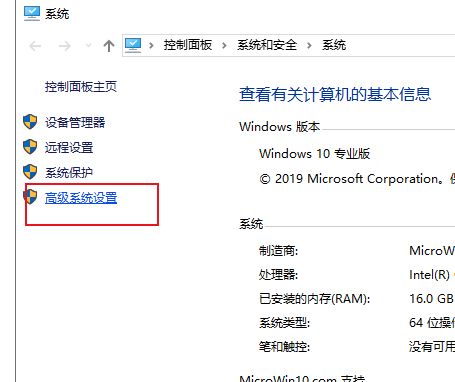
设置环境变量
- 找到jdk安装的bin目录,复制安装路径
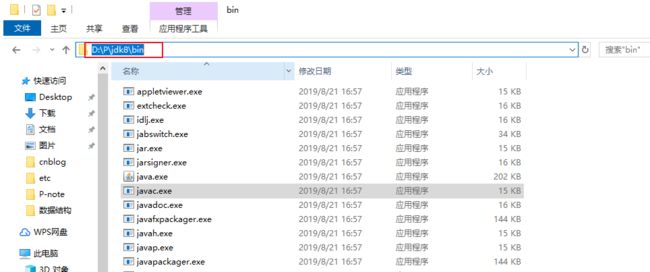
-
右键电脑选择属性
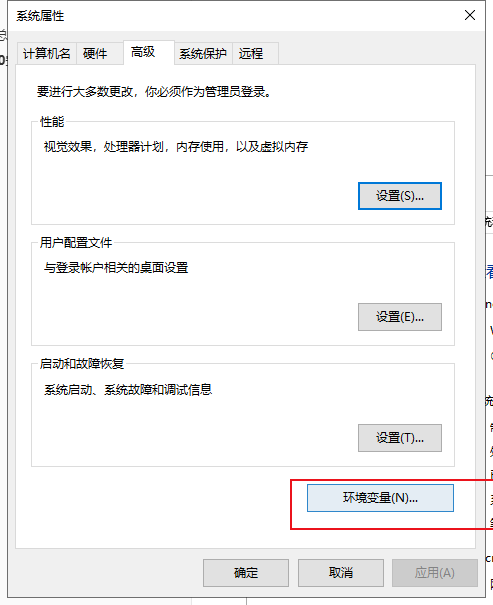
添加刚刚复制的路径到path里:

点击三个确定。
-
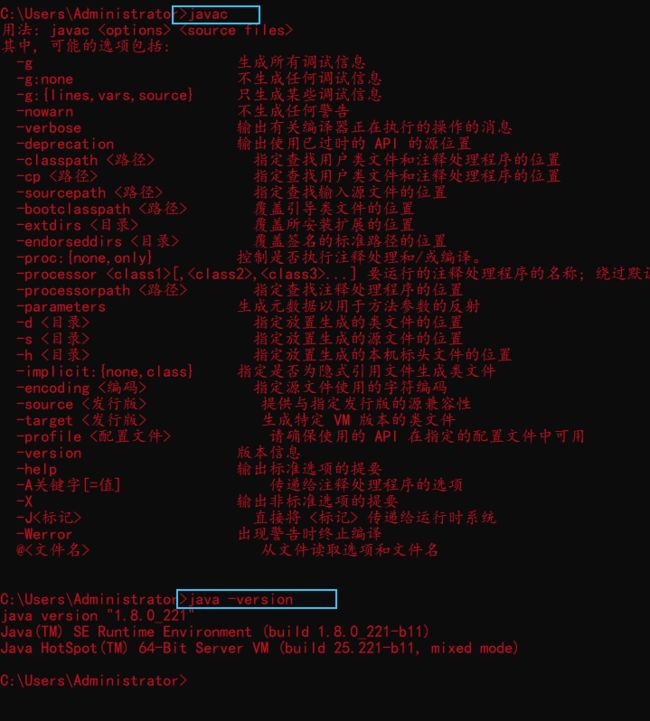
查看是否安装成功
java -versionjavajavac
3,经典HelloWorld
3.1 命令行运行Java程序
-
新建文件,命名为HelloWorld.java
用记事本打开,输入
public class HelloWorld { public static void main(String[] args) { System.out.println("Hello World!"); } } -
打开命令行,定位到HelloWorld.java所在位置
javac HelloWorld.java //编译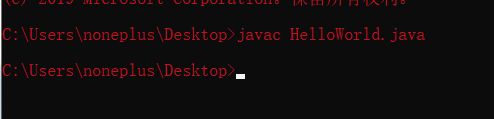
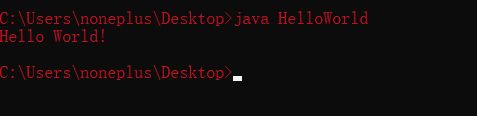
java HelloWorld //运行
3.2 使用IDEA 运行Java程序
-
安装IDEA
https://www.jetbrains.com/idea/
-
配置JDK

-
创建Java程序
-
输出HelloWorld
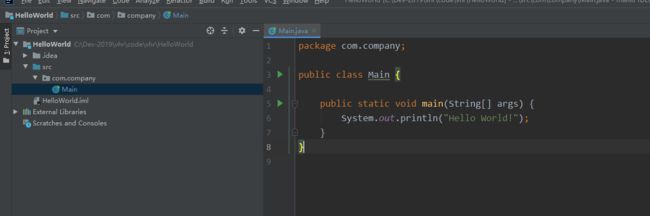
package com.company;
public class Main {
public static void main(String[] args) {
System.out.println("Hello World!");
}
}
-
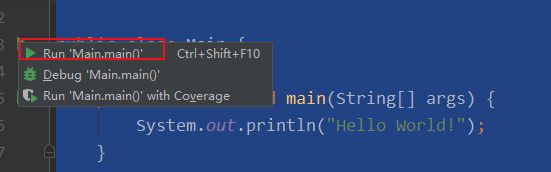
运行程序

4,数据类型&变量
4.1 为什么要设计不同种类的数据类型?
以结果为导向来分析:Java的整数类型分为4种:byte,short,int,long。四种的区别在于占用的存储空间不一样。
byte占用1个字节,short占用2个字节,int占用4个字节,而long占用8个字节。
1字节等于8位而八位可以表示数-128 - 127。这是byte类型的表示范围。那如果想用计算机计算1000加上1000,byte明显是不可用的。因为byte表示不了1000这个数值。
而short类型的存储空间为2个字节,也就是16位。对于short数据类型来说,能表示多大的数呢?根据8位的表示范围推算:
-2^15 = 2^15-1 -32768--32767
以此类推,int为4个字节,long为8个字节,能表示的数更大。
Java通过定义变量的类型来规定变量的内存空间大小,通过阶梯式的定义,既有满足小数值运行的byte类型,也有支持大数值运算的long类型。这样不仅满足运算的最大支持(long),同时也能节省系统内存资源(byte)。
【总结】
数据类型的区分是一种系统资源分配优化的方案。
【字节和位的关系】
字节是一种存储单位的度量。1个字节等于8位。
位可以理解为计算机的最小单位:0或者是1。也就是是说1个字节是8个0和1的排列组合:
比如说:00000000,00000001,00000011,......11111111。
【理论上1个字节可以表示多大的数呢?】
-
在无符号位的情况下:
00000000转换为十进制依然是0,11111111转换为十进制是255。
转换工具:https://tool.lu/hexconvert/
也就是说,一个字节最大可以表示255而最小1可以表示0。
-
在有符号位的情况下:
如果8位表示正数和负数,那么8位可以表示的范围是多大呢?
通常情况下,用第一位来表示正负【0为正,1为负】,这样算下来8位可以表示的范围是-127到+127。
【实际上1个字节可以表示多大的数呢?补码登场】
上述引入符号位的8位二进制数可以理解为原码。对于正数来说,原码就是补码,而对于负数来说,符号位不变,其他原码按位取反加1所得即为补码。
为什么需要补码?
补码的出现使得加减法只有加法,简化了计算结构,提高运算速度。(减法变成了加一个负数)
【为什么8位二进制数补码表示的范围是-128-127?】
无符号位原码:0000 0000 - 1111 1111 表示范围0 - 255
有符号位原码:1111 1111 - 0111 1111 表示范围-127 - 127
补码:符号位不变,在原码的基础上按位取反加1,理论上最大的数0111 1111 = 127 ,最小的数 1111 1111 = -127
但是特殊情况:原码0000 0000 理论上表示正数,也就是+0,原码1000 0000理论上表示负数,变为补码后去掉最高为也是0000 0000。
[+0]原码=0000 0000, [-0]原码=1000 0000
[+0]反码=0000 0000, [-0]反码=1111 1111
[+0]补码=0000 0000, [-0]补码=0000 0000
+0的补码和-0的补码都是0000 0000。但8位二进制数的补码可以表示2^8也就是256个数1-127,-1-(-127)一共数254个数。
所以计算机将补码-0(1000 000)特殊设为-128。这个数没有原码和反码。
(就是多了一个表示的数,计算机就特殊处理了)
4.2 数据变量&类型的定义
变量是内存中的一个存储区域。而数据类型的定义决定了这块存储区域的大小。
比如 int x ;其中x变量在内存中占有一定空间,而int决定这个空间是4个字节。
【关于变量的描述】
-
变量是内存中的一个存储区域。【程序运行的时候,变量是放在内存里的】
-
存储区域的数据可以在同一类型范围里不断变化【所以叫变量,就是能变嘛】
-
变量包括:例如【int x = 3】 变量类型int 变量名x 变量的值3
-
变量必须先声明后使用
int x = 10; (√)
x = 10; (×)
声明:变量必须得先指定具体的数据类型才能使用。
4.3 基本数据类型
4类8种:4种整数型,2种浮点型,1种字符型,一种布尔型
| byte | 1字节 | 默认值 | 范围 |
|---|---|---|---|
| short | 2字节 | 0 | |
| int | 4字节 | 0 | -231 至-231-1 |
| long | 8字节 | 0L | |
| float | 4字节 | 0f | |
| double | 8字节 | 0d | |
| char | 2字节 | ‘u000’ | |
| boolean | 4字节 | false | |
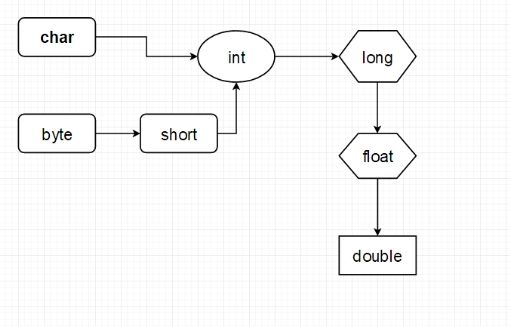
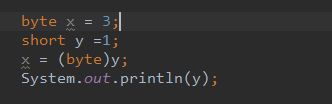
4.4 自动类型转换&强制类型转换
自动类型转换:由表示范围小的自动转换为表示范围大的。
强制类型转换:反向转换
4.5 包装类
包装类是Java设计之初提出的,主要解决基本数据类型无法面对对象编程的问题。
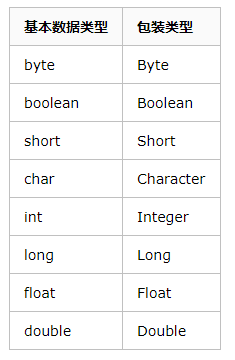
装箱:基本数据类型 to 包装类
拆箱:包装类 to 基本数据类型
//int与Integer之间的转换
int x = 5;
Integer y = new Integer(x);
System.out.println("int转换为Integer,y="+y);
int z = y.intValue();
System.out.println("Integer转换为int,z="+z);
System.out.println("=======================");
//Integer与String转换
String s1 = "666";
Integer i1 = Integer.parseInt(s1);
System.out.println("String转换为Integer,i1="+i1);
String s2 = i1.toString();
System.out.println("Integer转换为String,s2="+s2);
System.out.println("=======================");
//int与String转换
int xx = 2;
String ss1 = String.valueOf(xx);
System.out.println("int转换为String,ss1="+ss1);
int yy = Integer.parseInt(ss1);
System.out.println("String转换为int,yy="+yy);
System.out.println("=======================");
//JDK1.5后Java采取自动装箱和自动拆箱功能
//自动装箱,编译器执行了Integer x1 = Integer.valueOf(x)
Integer x1 = x;
System.out.println("自动装箱,x1="+x1);
//自动拆箱,编译器执行了 int y1 = y.intValue()
int y1 = y;
System.out.println("自动拆箱,y1="+y1);
面向对象
1,灵魂拷问,什么是面向对象?
说到面向对象,不得不说面向过程,比如C,汇编都是面向过程的开发思路,面向过程的也是有抽象层次的,例如汇编是对机器语言的抽象,通过指令的方式对01代码进行抽象,这样不用直接操作01更加方便,而C又是对汇编语言的抽象,屏蔽了指令,直接使用语义化的代码来写程序。而不管是C还是汇编都是站在计算机的角度,或者说按照计算机的规律,就比如说流程控制,if else,for循环,一步一步来。这样的问题就是如果想要通过这样的方式将程序应用到一些更加广泛更加复杂的场景就会比较困难,比如说现在的电商应用,B端产品,复杂度都是相当高的软件。两次软件危机的发生也促使了面向对象的发展,然后说说面向对象,抛开语法层面的东西,面向对象的核心思想我认为是换了一个主体,就是以谁为主。传统的面向过程的方法以计算机为主,是基于计算机的结构去解决现实生活中的一些问题,比如说顺序结构,循环,条件这些,这是计算机的思路,而以前开发程序就是得依着这样一种思路,当然现在也是,但面向对象打开了一种新的思路,我们不用先依着计算机,然后在计算机的角度来解决我们的问题,我们可以直接思考问题,然后解决它。比如说,我想要做一个博客类的应用,这就会涉及到文章的各种处理,面向对象的思路就是直接把问题抽象成类,比如文章就抽象成一个文章类,里面包含标题,作者,一堆属性,里面还可以定义一系列方法,那么问题来了?这样一种开发思路有什么好处?直接用字符串操作不行吗?整的这么弯弯绕绕!首先,我承认,面向对象的思路相对于面向过程来说,是有一定难度的。因为面向对象所思考的问题和面向过程最大的区别是问题复杂度的程度完全不一致。或者说,面向对象就是为了解决复杂的程序而设计的,一个简单的程序,如果用面向过程和面向对象来解决,比较是没有任何意义的,肯定面向过程方便,没有人计算个1+1还把电脑打开。在问题复杂度上升了之后,面向对象的优势就出来了,关于第二次软件危机里面有一个描述就是:一个大型的软件,耗费数年之久,投入程序员数千名,花费资金占原子弹造价1/4,但还是宣告失败。面向对象为什么能应对复杂度高的软件?这就涉及到面向对象的三大特征了,首先是封装,封装的核心就是隐藏具体的实现方法,只暴露一个接口,说白了就是调用API,然后实现代码解耦。高内聚,低耦合,其中低耦合就是通过封装实现,那么低耦合之后呢?有啥好处,其实人人都能感受到,现在我们使用的大量的第三方框架,比如搭建一个Web服务,为什么可以直接访问到写的页面,这个过程只有开发框架的人知道,而调用框架的人不知道,但不知道还是能够正常的完成一个web应用,真神奇,这就是封装的作用,想象一下,一个超大型的应用,有几百个同事在和你一起开发,如果你要把几百个同事写的代码全都看一遍才能写你这部分代码,那效率得有多低啊!但现在通过一个语义清晰的方法和注释,你就能轻松使用别人写了几千行甚至几万行代码的功能,就问你香不香?这是其一,封装的作用。面向对象的第二个特性是继承,继承就一个点,实现代码复用。同样一个方法,在父类里写一遍比在每个子类中都写一遍肯定更节约电。面向对象第三个特性便是多态,多态是配合继承来说的,继承实现了代码复用,多态在复用的基础上定义子类可以重写父类的方法,使程序更加灵活可扩展。我一直没有意识到面向对象这个问题,直到我知道了面向过程。现在市场上大部分用的都是面向对象,巨大的市场需求催生了面向对象的火爆,但究其根本只是一种软件开发的思想,软件开发是没有银弹的,若干年后,也一定会有更好更先进的思维解决问题。
小结一下,面向过程与面向对象的区别在哪?
-
使用场景:面向过程更加适合复杂度不高的程序,而面向对象就是专门解决复杂度高的问题的
-
解决问题的思路:面向过程将问题抽象为流程来解决,面向对象将问题抽象为类和对象来解决
面向对象的三大特性简述:
- 封装:通过隐藏实现,暴露接口,降低代码的耦合度,使协同开发的复杂度降低
- 继承与多态:继承的作用是实现代码的复用,而多态在复用的基础上定义子类可以重写父类的方法,使得程度灵活可扩展
这部分修改过好几次,之前的理解:
网上有一个生动的例子来说明面向对象的特点:
我要用洗衣机洗衣服,只需要按一下开关和洗涤模式就可以了。有必要了解洗衣机内 部的结构吗?有必要碰电动机吗?有必要了解如何通电的吗?这是一个很“真实”的例子,没有人会为了使用洗衣机去学一下电学的组成原理,但我们却方便使用者洗衣机,手机,电脑等各种各样的事物却并不了解它们的原理。这是好事还是坏事?洗衣机可以洗脏衣服,手机可以和亲朋好友打电话,电脑可以帮助我们方便的处理难以解决的各种问题。但这个世界上并不是没有人不懂洗衣机的原理,手机的制造,电脑的组装。我们不懂其内部结构却正常的使用着这些设备,并不是单纯科技的进步,而是人类对于事物的处理思路发生了变化,究其根本是为了更高的效率!设计手机的人也许用着别人制造的洗衣机,敲着键盘的人是另一个领域的创造者,社会分工明确,整体效率极大提升,你只需专注一项,就可获得所有的便利。
回到面向对象的问题上来,什么是面向对象呢?
个人认为:如果摒弃软件开发的范畴,这是一种通过明确社会分工而提高效率的方法。在软件开发的范围内,就是通过抽象出系统功能而实现最大化代码复用的开发模式。
面向对象的延伸:
面向对象是软件开发的名词,但其中蕴含的是这个世界的发展规律。
比如,住房子不一定自己建,也可以买;吃饭不一定自己做,也可以出去吃或者叫外卖;至于洗衣机,电脑冰箱这些更不用提了。你只需要做好自己的事,剩下的,交给其他人就好了。
在软件开发的范畴内,除了编写代码上运用了面向对象的思想,使用第三方框架等同样是面向对象的延伸,从底层的操作系统,JVM虚拟机,包括Java语言,我们并不需要重新再发明一遍,站在巨人的肩膀上,我们能做的事更多。
2,如何实现面向对象?——封装,继承,多态
2.1 封装
-
什么是封装?
核心:通过隐藏实现,暴露接口,一来实现代码解耦,二来通过访问修饰符保证数据安全。
-
如何保证数据安全
比如说设置年龄,可以在set中加个if强制不能超过30岁。(同理,不能为空等等可以保证数据安全) public void setAge(int age) { if(age>=30){ this.age=18; }else{ this.age = age; } }
![]()
![]() 参考这位女司机豪横:https://zhuanlan.zhihu.com/p/37853346
参考这位女司机豪横:https://zhuanlan.zhihu.com/p/37853346
2.2 继承
核心目的:实现代码复用。
-
继承规则
- 子类具有父类非private的属性和方法
- 子类可以扩展自己的属性和方法
-
构造器会被继承吗?
-
构造器是不会被子类继承的,但子类的对象在初始化时会默认调用父类的无参构造器。
子类会继承父类的数据,所以必须要看父类是如何对数据进行初始化的;故子类在进行对象初始化时,会先调用父类的构造函数。
-
当父类显式写了有参构造器,且没有无参构造器。子类继承父类的时候必须显式的调用父类的有参构造器。调用的方式可以使用super(a,b)来调用。
-
-
子类,父类初始化顺序
原则:静态优于非静态,父类优于子类 - 父类静态变量,静态语句块 - 子类静态变量,静态语句块 - 父类非静态代码块,构造器 - 子类非静态代码块,构造器class Base { // 1.父类静态代码块 static { System.out.println("Base static block!"); } // 3.父类非静态代码块 { System.out.println("Base block"); } // 4.父类构造器 public Base() { System.out.println("Base constructor!"); } } public class Derived extends Base { // 2.子类静态代码块 static{ System.out.println("Derived static block!"); } // 5.子类非静态代码块 { System.out.println("Derived block!"); } // 6.子类构造器 public Derived() { System.out.println("Derived constructor!"); } public static void main(String[] args) { new Derived(); } }Base static block! Derived static block! Base block Base constructor! Derived block! Derived constructor! -
继承之父——Object类
Object类是所有Java类的根父类 ,如果在类的声明中未使用extends关键字指明其父类,则默认父类 为java.lang.Object类(任何类都可以调用Object的方法)
【Object的主要组成】
-
public native int hashCode(); 取得hash码
hash码是根据一定的规则将与对象相关的信息(比如对象的存储地址,对象的字段等)映射成一个数值,这个数值称作为散列值。主要作用是为了配合基于散列的集合一起正常运行,这样的散列集合包括HashSet、HashMap以及HashTable。
当集合要添加新的对象时,先调用这个对象的hashCode方法,得到对应的hashcode值,如果table中没有该hashcode值,它就可以直接存进去,不用再进行任何比较了;如果存在该hashcode值,就调用它的equals方法与新元素进行比较,相同的话就不存了,不相同就散列其它的地址。
-
equals(Object obj) 比较对象
-
clone() 可用于复杂对象的深拷贝
-
2.3 多态
-
什么是多态?
一类事物的多种表现形态。(比如手机有各种各样的品牌,但都属于手机这一类事物)
-
多态的体现方式:重载,重写
方法重载:同一个类中,方法名相同,参数或者参数的个数不同
方法重写:类产生了继承关系,子类重写父类方法(方法名,参数,返回类型必须与父类一致)
-
向上转型
将子类对象转化为父类对象,目的:调用父类的公共方法
规则:可以访问父类独有的方法和子类重写父类的方法,无法访问子类扩展的方法
[假如有100个类继承了同一个父类,父类的方法可以被这100个类使用,相比于在子类中逐个定义,在父类中定义具有更好的代码复用性]
Father是父类,Son类继承自Father。 Father f1 = new Son(); //(向上转型) Son s1 = (Son)f1; //(向下转型,父类转换为子类) -
向下转型
将父类对象转换为子类对象,目的:调用子类独有的方法(为什么不直接new一个子类对象???)
规则:可以调用父类的方法,子类重写父类的方法,子类扩展的方法
Father是父类,Son类继承自Father。 Father f1 = new Son(); Son s1 = (Son)f1; //(向下转型,父类转换为子类,注:父类对象无法直接转换为子类对象,向下转型前必须先向上转型)
3,关键字盘点
3.1 static
static可以修饰方法,变量,代码块,类,前两种应用更加常见。
-
static修饰方法
static修饰的方法称为静态方法,也称类方法,可以直接通过类名.方法名直接访问,不需要实例化对象访问。
规则:
- 非static方法可以访问static方法.
- static方法不能访问非static方法
-
static修饰变量
static修饰的变量称为静态变量,也称类变量,全局变量,可以直接通过类名.变量名直接访问,不需要实例化对象访问。
-
static的继承问题
子类是不会继承父类被static修饰的方法和变量,但是可以调用。
-
static修饰代码块
代码块的作用:对类或对象进行初始化。
静态代码块【static修饰】 - 不可以对非静态的属性初始化。即:不可以调用非静态的属性和方法。 - 静态代码块的执行要先于非静态代码块。 - 静态代码块随着类的加载而加载,且只执行一次 非静态代码块 - 除了调用非静态的结构外,还可以调用静态的变量或方法。 - 每次创建对象的时候,都会执行一次。且先于构造器执行。
3.2 final
final关键字可以修饰类,方法,变量。
-
final修饰类
不能被继承
-
final修饰方法
方法不能被子类重写
-
final修饰变量
修饰基本数据类型的变量,想当于定义了一个常量。
final int x =5; x=6;//报错修饰引用类型的变量,固定栈,不固定堆,也就是引用变量的地址是不可变的,但是引用地址指向的堆中的内容是可变的。
final StringBuffer s = new StringBuffer("hello"); s.append("world");