x264代码剖析(十一):核心算法之宏块分析函数x264_macroblock_analyse()
x264代码剖析(十一):核心算法之宏块分析函数x264_macroblock_analyse()
x264的 x264_slice_write()函数中调用了宏块分析函数x264_macroblock_analyse(),该模块主要完成2大任务:一是对于帧内宏块,分析帧内预测模式;二是对于帧间宏块,进行运动估计,分析帧间预测模式。
如下图所示是x264_macroblock_analyse()的函数关系图。
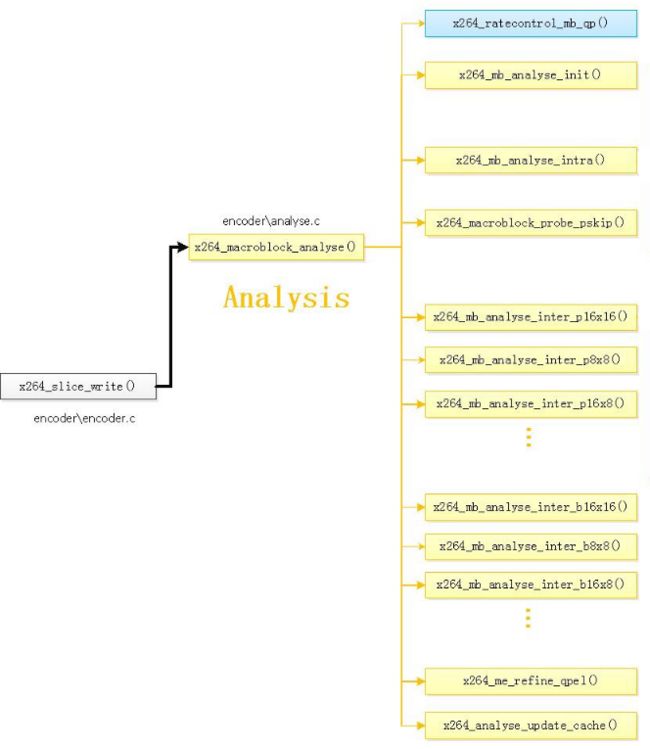
从图中可以总结出x264_macroblock_analyse()函数调用了如下几个主要的函数:
x264_ratecontrol_mb_qp( ):通过码率控制方法获取本宏块QP
x264_mb_analyse_init():Analysis模块初始化。
x264_mb_analyse_intra():Intra宏块帧内预测模式分析。
x264_macroblock_probe_pskip():分析是否是skip模式。
x264_mb_analyse_inter_p16x16():P16x16宏块帧间预测模式分析。
x264_mb_analyse_inter_p8x8():P8x8宏块帧间预测模式分析。
x264_mb_analyse_inter_p16x8():P16x8宏块帧间预测模式分析。
x264_mb_analyse_inter_b16x16():B16x16宏块帧间预测模式分析。
x264_mb_analyse_inter_b8x8():B8x8宏块帧间预测模式分析。
x264_mb_analyse_inter_b16x8():B16x8宏块帧间预测模式分析。
x264_macroblock_analyse()用于分析宏块的预测模式。该函数的定义位于encoder\analyse.c,对应的代码分析如下:
/******************************************************************/
/******************************************************************/
/*
======Analysed by RuiDong Fang
======Csdn Blog:http://blog.csdn.net/frd2009041510
======Date:2016.03.13(今天当舅舅啦!!!哈哈哈)
*/
/******************************************************************/
/******************************************************************/
/************====== x264_macroblock_analyse()函数 ======************/
/*
功能:分析函数,调用了帧内预测与帧间预测
*/
/*****************************************************************************
* x264_macroblock_analyse:
*****************************************************************************/
void x264_macroblock_analyse( x264_t *h )
{
x264_mb_analysis_t analysis;
int i_cost = COST_MAX;
h->mb.i_qp = x264_ratecontrol_mb_qp( h ); ///通过码率控制方法,获取本宏块QP
/* If the QP of this MB is within 1 of the previous MB, code the same QP as the previous MB,
* to lower the bit cost of the qp_delta. Don't do this if QPRD is enabled. */
if( h->param.rc.i_aq_mode && h->param.analyse.i_subpel_refine < 10 )
h->mb.i_qp = abs(h->mb.i_qp - h->mb.i_last_qp) == 1 ? h->mb.i_last_qp : h->mb.i_qp;
if( h->param.analyse.b_mb_info )
h->fdec->effective_qp[h->mb.i_mb_xy] = h->mb.i_qp; /* Store the real analysis QP. */
x264_mb_analyse_init( h, &analysis, h->mb.i_qp ); ///Analysis模块初始化
/*--------------------------- Do the analysis ---------------------------*/
/*******************************************************/
/*
I帧:只使用帧内预测,分别计算亮度16x16(4种)和4x4(9种)所有模式的代价值,选出代价最小的模式
*/
/*******************************************************/
if( h->sh.i_type == SLICE_TYPE_I )
{
//I slice
//通过一系列帧内预测模式(16x16的4种,4x4的9种)代价的计算得出代价最小的最优模式
intra_analysis:
if( analysis.i_mbrd )
x264_mb_init_fenc_cache( h, analysis.i_mbrd >= 2 );
//帧内预测分析
//从16×16的SAD,4个8×8的SAD和,16个4×4SAD中选出最优方式
x264_mb_analyse_intra( h, &analysis, COST_MAX ); ///Intra宏块帧内预测模式分析
if( analysis.i_mbrd )
x264_intra_rd( h, &analysis, COST_MAX );
//分析结果(开销)都存储在analysis结构体中
i_cost = analysis.i_satd_i16x16;
h->mb.i_type = I_16x16;
//如果I4x4或者I8x8开销更小的话就拷贝
//copy if little
COPY2_IF_LT( i_cost, analysis.i_satd_i4x4, h->mb.i_type, I_4x4 );
COPY2_IF_LT( i_cost, analysis.i_satd_i8x8, h->mb.i_type, I_8x8 );
//画面极其特殊的时候,才有可能用到PCM
if( analysis.i_satd_pcm < i_cost )
h->mb.i_type = I_PCM;
else if( analysis.i_mbrd >= 2 )
x264_intra_rd_refine( h, &analysis );
}
/*******************************************************/
/*
P帧:计算帧内模式和帧间模式( P Slice允许有Intra宏块和P宏块;同理B帧也支持Intra宏块)。
对P帧的每一种分割进行帧间预测,得到最佳的运动矢量及最佳匹配块。
帧间预测过程:选出最佳矢量——>找到最佳的整像素点——>找到最佳的二分之一像素点——>找到最佳的1/4像素点
然后取代价最小的为最佳MV和分割方式
最后从帧内模式和帧间模式中选择代价比较小的方式(有可能没有找到很好的匹配块,这时候就直接使用帧内预测而不是帧间预测)。
*/
/*******************************************************/
else if( h->sh.i_type == SLICE_TYPE_P )
{
int b_skip = 0;
h->mc.prefetch_ref( h->mb.pic.p_fref[0][0][h->mb.i_mb_x&3], h->mb.pic.i_stride[0], 0 );
analysis.b_try_skip = 0;
if( analysis.b_force_intra )
{
if( !h->param.analyse.b_psy )
{
x264_mb_analyse_init_qp( h, &analysis, X264_MAX( h->mb.i_qp - h->mb.ip_offset, h->param.rc.i_qp_min ) );
goto intra_analysis;
}
}
else
{
/* Special fast-skip logic using information from mb_info. */
if( h->fdec->mb_info && (h->fdec->mb_info[h->mb.i_mb_xy]&X264_MBINFO_CONSTANT) )
{
if( !SLICE_MBAFF && (h->fdec->i_frame - h->fref[0][0]->i_frame) == 1 && !h->sh.b_weighted_pred &&
h->fref[0][0]->effective_qp[h->mb.i_mb_xy] <= h->mb.i_qp )
{
h->mb.i_partition = D_16x16;
/* Use the P-SKIP MV if we can... */
if( !M32(h->mb.cache.pskip_mv) )
{
b_skip = 1;
h->mb.i_type = P_SKIP;
}
/* Otherwise, just force a 16x16 block. */
else
{
h->mb.i_type = P_L0;
analysis.l0.me16x16.i_ref = 0;
M32( analysis.l0.me16x16.mv ) = 0;
}
goto skip_analysis;
}
/* Reset the information accordingly */
else if( h->param.analyse.b_mb_info_update )
h->fdec->mb_info[h->mb.i_mb_xy] &= ~X264_MBINFO_CONSTANT;
}
int skip_invalid = h->i_thread_frames > 1 && h->mb.cache.pskip_mv[1] > h->mb.mv_max_spel[1];
/* If the current macroblock is off the frame, just skip it. */
if( HAVE_INTERLACED && !MB_INTERLACED && h->mb.i_mb_y * 16 >= h->param.i_height && !skip_invalid )
b_skip = 1;
/* Fast P_SKIP detection */
else if( h->param.analyse.b_fast_pskip )
{
if( skip_invalid )
// FIXME don't need to check this if the reference frame is done
{}
else if( h->param.analyse.i_subpel_refine >= 3 )
analysis.b_try_skip = 1;
else if( h->mb.i_mb_type_left[0] == P_SKIP ||
h->mb.i_mb_type_top == P_SKIP ||
h->mb.i_mb_type_topleft == P_SKIP ||
h->mb.i_mb_type_topright == P_SKIP )
b_skip = x264_macroblock_probe_pskip( h ); ///分析是否是skip模式--P
}
}
h->mc.prefetch_ref( h->mb.pic.p_fref[0][0][h->mb.i_mb_x&3], h->mb.pic.i_stride[0], 1 );
if( b_skip )
{
h->mb.i_type = P_SKIP;
h->mb.i_partition = D_16x16;
assert( h->mb.cache.pskip_mv[1] <= h->mb.mv_max_spel[1] || h->i_thread_frames == 1 );
skip_analysis:
/* Set up MVs for future predictors */
for( int i = 0; i < h->mb.pic.i_fref[0]; i++ )
M32( h->mb.mvr[0][i][h->mb.i_mb_xy] ) = 0;
}
else
{
const unsigned int flags = h->param.analyse.inter;
int i_type;
int i_partition;
int i_satd_inter, i_satd_intra;
x264_mb_analyse_load_costs( h, &analysis );
x264_mb_analyse_inter_p16x16( h, &analysis ); ///16x16 帧间预测宏块分析--P
if( h->mb.i_type == P_SKIP )
{
for( int i = 1; i < h->mb.pic.i_fref[0]; i++ )
M32( h->mb.mvr[0][i][h->mb.i_mb_xy] ) = 0;
return;
}
if( flags & X264_ANALYSE_PSUB16x16 )
{
if( h->param.analyse.b_mixed_references )
x264_mb_analyse_inter_p8x8_mixed_ref( h, &analysis );
else
x264_mb_analyse_inter_p8x8( h, &analysis ); ///8x8帧间预测宏块分析--P
}
/* Select best inter mode */
i_type = P_L0;
i_partition = D_16x16;
i_cost = analysis.l0.me16x16.cost;
//如果8x8的代价值小于16x16
//则进行8x8子块分割的处理
//处理的数据源自于l0?
if( ( flags & X264_ANALYSE_PSUB16x16 ) && (!analysis.b_early_terminate ||
analysis.l0.i_cost8x8 < analysis.l0.me16x16.cost) )
{
i_type = P_8x8;
i_partition = D_8x8;
i_cost = analysis.l0.i_cost8x8;
/* Do sub 8x8 */
if( flags & X264_ANALYSE_PSUB8x8 )
{
for( int i = 0; i < 4; i++ )//8x8块的子块的分析
{
x264_mb_analyse_inter_p4x4( h, &analysis, i ); ///4x4帧间预测宏块分析--P
int i_thresh8x4 = analysis.l0.me4x4[i][1].cost_mv + analysis.l0.me4x4[i][2].cost_mv;
//如果4x4小于8x8,则再分析8x4,4x8的代价
if( !analysis.b_early_terminate || analysis.l0.i_cost4x4[i] < analysis.l0.me8x8[i].cost + i_thresh8x4 )
{
int i_cost8x8 = analysis.l0.i_cost4x4[i];
h->mb.i_sub_partition[i] = D_L0_4x4;
x264_mb_analyse_inter_p8x4( h, &analysis, i ); ///8x4帧间预测宏块分析--P
COPY2_IF_LT( i_cost8x8, analysis.l0.i_cost8x4[i],
h->mb.i_sub_partition[i], D_L0_8x4 );//如果8x4小于8x8
x264_mb_analyse_inter_p4x8( h, &analysis, i ); ///4x8帧间预测宏块分析--P
COPY2_IF_LT( i_cost8x8, analysis.l0.i_cost4x8[i],
h->mb.i_sub_partition[i], D_L0_4x8 );//如果4x8小于8x8
i_cost += i_cost8x8 - analysis.l0.me8x8[i].cost;
}
x264_mb_cache_mv_p8x8( h, &analysis, i );
}
analysis.l0.i_cost8x8 = i_cost;
}
}
/* Now do 16x8/8x16 */
int i_thresh16x8 = analysis.l0.me8x8[1].cost_mv + analysis.l0.me8x8[2].cost_mv;
//前提要求8x8的代价值小于16x16
if( ( flags & X264_ANALYSE_PSUB16x16 ) && (!analysis.b_early_terminate ||
analysis.l0.i_cost8x8 < analysis.l0.me16x16.cost + i_thresh16x8) )
{
int i_avg_mv_ref_cost = (analysis.l0.me8x8[2].cost_mv + analysis.l0.me8x8[2].i_ref_cost
+ analysis.l0.me8x8[3].cost_mv + analysis.l0.me8x8[3].i_ref_cost + 1) >> 1;
analysis.i_cost_est16x8[1] = analysis.i_satd8x8[0][2] + analysis.i_satd8x8[0][3] + i_avg_mv_ref_cost;
x264_mb_analyse_inter_p16x8( h, &analysis, i_cost ); ///16x8帧间预测宏块分析--P
COPY3_IF_LT( i_cost, analysis.l0.i_cost16x8, i_type, P_L0, i_partition, D_16x8 );
i_avg_mv_ref_cost = (analysis.l0.me8x8[1].cost_mv + analysis.l0.me8x8[1].i_ref_cost
+ analysis.l0.me8x8[3].cost_mv + analysis.l0.me8x8[3].i_ref_cost + 1) >> 1;
analysis.i_cost_est8x16[1] = analysis.i_satd8x8[0][1] + analysis.i_satd8x8[0][3] + i_avg_mv_ref_cost;
x264_mb_analyse_inter_p8x16( h, &analysis, i_cost ); ///8x16帧间预测宏块分析--P
COPY3_IF_LT( i_cost, analysis.l0.i_cost8x16, i_type, P_L0, i_partition, D_8x16 );
}
h->mb.i_partition = i_partition;
/* refine qpel */
//亚像素精度搜索
//FIXME mb_type costs?
if( analysis.i_mbrd || !h->mb.i_subpel_refine )
{
/* refine later */
}
else if( i_partition == D_16x16 )
{
x264_me_refine_qpel( h, &analysis.l0.me16x16 ); ///亚像素精度搜索
i_cost = analysis.l0.me16x16.cost;
}
else if( i_partition == D_16x8 )
{
x264_me_refine_qpel( h, &analysis.l0.me16x8[0] );
x264_me_refine_qpel( h, &analysis.l0.me16x8[1] );
i_cost = analysis.l0.me16x8[0].cost + analysis.l0.me16x8[1].cost;
}
else if( i_partition == D_8x16 )
{
x264_me_refine_qpel( h, &analysis.l0.me8x16[0] );
x264_me_refine_qpel( h, &analysis.l0.me8x16[1] );
i_cost = analysis.l0.me8x16[0].cost + analysis.l0.me8x16[1].cost;
}
else if( i_partition == D_8x8 )
{
i_cost = 0;
for( int i8x8 = 0; i8x8 < 4; i8x8++ )
{
switch( h->mb.i_sub_partition[i8x8] )
{
case D_L0_8x8:
x264_me_refine_qpel( h, &analysis.l0.me8x8[i8x8] );
i_cost += analysis.l0.me8x8[i8x8].cost;
break;
case D_L0_8x4:
x264_me_refine_qpel( h, &analysis.l0.me8x4[i8x8][0] );
x264_me_refine_qpel( h, &analysis.l0.me8x4[i8x8][1] );
i_cost += analysis.l0.me8x4[i8x8][0].cost +
analysis.l0.me8x4[i8x8][1].cost;
break;
case D_L0_4x8:
x264_me_refine_qpel( h, &analysis.l0.me4x8[i8x8][0] );
x264_me_refine_qpel( h, &analysis.l0.me4x8[i8x8][1] );
i_cost += analysis.l0.me4x8[i8x8][0].cost +
analysis.l0.me4x8[i8x8][1].cost;
break;
case D_L0_4x4:
x264_me_refine_qpel( h, &analysis.l0.me4x4[i8x8][0] );
x264_me_refine_qpel( h, &analysis.l0.me4x4[i8x8][1] );
x264_me_refine_qpel( h, &analysis.l0.me4x4[i8x8][2] );
x264_me_refine_qpel( h, &analysis.l0.me4x4[i8x8][3] );
i_cost += analysis.l0.me4x4[i8x8][0].cost +
analysis.l0.me4x4[i8x8][1].cost +
analysis.l0.me4x4[i8x8][2].cost +
analysis.l0.me4x4[i8x8][3].cost;
break;
default:
x264_log( h, X264_LOG_ERROR, "internal error (!8x8 && !4x4)\n" );
break;
}
}
}
if( h->mb.b_chroma_me )
{
if( CHROMA444 )
{
x264_mb_analyse_intra( h, &analysis, i_cost );
x264_mb_analyse_intra_chroma( h, &analysis );
}
else
{
x264_mb_analyse_intra_chroma( h, &analysis );
x264_mb_analyse_intra( h, &analysis, i_cost - analysis.i_satd_chroma );
}
analysis.i_satd_i16x16 += analysis.i_satd_chroma;
analysis.i_satd_i8x8 += analysis.i_satd_chroma;
analysis.i_satd_i4x4 += analysis.i_satd_chroma;
}
else
x264_mb_analyse_intra( h, &analysis, i_cost );//P Slice中也允许有Intra宏块,所以也要进行分析
i_satd_inter = i_cost;
i_satd_intra = X264_MIN3( analysis.i_satd_i16x16,
analysis.i_satd_i8x8,
analysis.i_satd_i4x4 );
if( analysis.i_mbrd )
{
x264_mb_analyse_p_rd( h, &analysis, X264_MIN(i_satd_inter, i_satd_intra) );
i_type = P_L0;
i_partition = D_16x16;
i_cost = analysis.l0.i_rd16x16;
COPY2_IF_LT( i_cost, analysis.l0.i_cost16x8, i_partition, D_16x8 );
COPY2_IF_LT( i_cost, analysis.l0.i_cost8x16, i_partition, D_8x16 );
COPY3_IF_LT( i_cost, analysis.l0.i_cost8x8, i_partition, D_8x8, i_type, P_8x8 );
h->mb.i_type = i_type;
h->mb.i_partition = i_partition;
if( i_cost < COST_MAX )
x264_mb_analyse_transform_rd( h, &analysis, &i_satd_inter, &i_cost );
x264_intra_rd( h, &analysis, i_satd_inter * 5/4 + 1 );
}
//获取最小的代价
COPY2_IF_LT( i_cost, analysis.i_satd_i16x16, i_type, I_16x16 );
COPY2_IF_LT( i_cost, analysis.i_satd_i8x8, i_type, I_8x8 );
COPY2_IF_LT( i_cost, analysis.i_satd_i4x4, i_type, I_4x4 );
COPY2_IF_LT( i_cost, analysis.i_satd_pcm, i_type, I_PCM );
h->mb.i_type = i_type;
if( analysis.b_force_intra && !IS_INTRA(i_type) )
{
/* Intra masking: copy fdec to fenc and re-encode the block as intra in order to make it appear as if
* it was an inter block. */
x264_analyse_update_cache( h, &analysis ); /
x264_macroblock_encode( h ); /
for( int p = 0; p < (CHROMA444 ? 3 : 1); p++ )
h->mc.copy[PIXEL_16x16]( h->mb.pic.p_fenc[p], FENC_STRIDE, h->mb.pic.p_fdec[p], FDEC_STRIDE, 16 );
if( !CHROMA444 )
{
int height = 16 >> CHROMA_V_SHIFT;
h->mc.copy[PIXEL_8x8] ( h->mb.pic.p_fenc[1], FENC_STRIDE, h->mb.pic.p_fdec[1], FDEC_STRIDE, height );
h->mc.copy[PIXEL_8x8] ( h->mb.pic.p_fenc[2], FENC_STRIDE, h->mb.pic.p_fdec[2], FDEC_STRIDE, height );
}
x264_mb_analyse_init_qp( h, &analysis, X264_MAX( h->mb.i_qp - h->mb.ip_offset, h->param.rc.i_qp_min ) );
goto intra_analysis;
}
if( analysis.i_mbrd >= 2 && h->mb.i_type != I_PCM )
{
if( IS_INTRA( h->mb.i_type ) )
{
x264_intra_rd_refine( h, &analysis );
}
else if( i_partition == D_16x16 )
{
x264_macroblock_cache_ref( h, 0, 0, 4, 4, 0, analysis.l0.me16x16.i_ref );
analysis.l0.me16x16.cost = i_cost;
x264_me_refine_qpel_rd( h, &analysis.l0.me16x16, analysis.i_lambda2, 0, 0 );
}
else if( i_partition == D_16x8 )
{
h->mb.i_sub_partition[0] = h->mb.i_sub_partition[1] =
h->mb.i_sub_partition[2] = h->mb.i_sub_partition[3] = D_L0_8x8;
x264_macroblock_cache_ref( h, 0, 0, 4, 2, 0, analysis.l0.me16x8[0].i_ref );
x264_macroblock_cache_ref( h, 0, 2, 4, 2, 0, analysis.l0.me16x8[1].i_ref );
x264_me_refine_qpel_rd( h, &analysis.l0.me16x8[0], analysis.i_lambda2, 0, 0 );
x264_me_refine_qpel_rd( h, &analysis.l0.me16x8[1], analysis.i_lambda2, 8, 0 );
}
else if( i_partition == D_8x16 )
{
h->mb.i_sub_partition[0] = h->mb.i_sub_partition[1] =
h->mb.i_sub_partition[2] = h->mb.i_sub_partition[3] = D_L0_8x8;
x264_macroblock_cache_ref( h, 0, 0, 2, 4, 0, analysis.l0.me8x16[0].i_ref );
x264_macroblock_cache_ref( h, 2, 0, 2, 4, 0, analysis.l0.me8x16[1].i_ref );
x264_me_refine_qpel_rd( h, &analysis.l0.me8x16[0], analysis.i_lambda2, 0, 0 );
x264_me_refine_qpel_rd( h, &analysis.l0.me8x16[1], analysis.i_lambda2, 4, 0 );
}
else if( i_partition == D_8x8 )
{
x264_analyse_update_cache( h, &analysis );
for( int i8x8 = 0; i8x8 < 4; i8x8++ )
{
if( h->mb.i_sub_partition[i8x8] == D_L0_8x8 )
{
x264_me_refine_qpel_rd( h, &analysis.l0.me8x8[i8x8], analysis.i_lambda2, i8x8*4, 0 );
}
else if( h->mb.i_sub_partition[i8x8] == D_L0_8x4 )
{
x264_me_refine_qpel_rd( h, &analysis.l0.me8x4[i8x8][0], analysis.i_lambda2, i8x8*4+0, 0 );
x264_me_refine_qpel_rd( h, &analysis.l0.me8x4[i8x8][1], analysis.i_lambda2, i8x8*4+2, 0 );
}
else if( h->mb.i_sub_partition[i8x8] == D_L0_4x8 )
{
x264_me_refine_qpel_rd( h, &analysis.l0.me4x8[i8x8][0], analysis.i_lambda2, i8x8*4+0, 0 );
x264_me_refine_qpel_rd( h, &analysis.l0.me4x8[i8x8][1], analysis.i_lambda2, i8x8*4+1, 0 );
}
else if( h->mb.i_sub_partition[i8x8] == D_L0_4x4 )
{
x264_me_refine_qpel_rd( h, &analysis.l0.me4x4[i8x8][0], analysis.i_lambda2, i8x8*4+0, 0 );
x264_me_refine_qpel_rd( h, &analysis.l0.me4x4[i8x8][1], analysis.i_lambda2, i8x8*4+1, 0 );
x264_me_refine_qpel_rd( h, &analysis.l0.me4x4[i8x8][2], analysis.i_lambda2, i8x8*4+2, 0 );
x264_me_refine_qpel_rd( h, &analysis.l0.me4x4[i8x8][3], analysis.i_lambda2, i8x8*4+3, 0 );
}
}
}
}
}
}
/*******************************************************/
/*
B Slice的时候
*/
/*******************************************************/
else if( h->sh.i_type == SLICE_TYPE_B )
{
int i_bskip_cost = COST_MAX;
int b_skip = 0;
if( analysis.i_mbrd )
x264_mb_init_fenc_cache( h, analysis.i_mbrd >= 2 );
h->mb.i_type = B_SKIP;
if( h->mb.b_direct_auto_write )
{
/* direct=auto heuristic: prefer whichever mode allows more Skip macroblocks */
for( int i = 0; i < 2; i++ )
{
int b_changed = 1;
h->sh.b_direct_spatial_mv_pred ^= 1;
analysis.b_direct_available = x264_mb_predict_mv_direct16x16( h, i && analysis.b_direct_available ? &b_changed : NULL );
if( analysis.b_direct_available )
{
if( b_changed )
{
x264_mb_mc( h );
b_skip = x264_macroblock_probe_bskip( h ); ///分析是否是skip模式--B
}
h->stat.frame.i_direct_score[ h->sh.b_direct_spatial_mv_pred ] += b_skip;
}
else
b_skip = 0;
}
}
else
analysis.b_direct_available = x264_mb_predict_mv_direct16x16( h, NULL );
analysis.b_try_skip = 0;
if( analysis.b_direct_available )
{
if( !h->mb.b_direct_auto_write )
x264_mb_mc( h );
/* If the current macroblock is off the frame, just skip it. */
if( HAVE_INTERLACED && !MB_INTERLACED && h->mb.i_mb_y * 16 >= h->param.i_height )
b_skip = 1;
else if( analysis.i_mbrd )
{
i_bskip_cost = ssd_mb( h );
/* 6 = minimum cavlc cost of a non-skipped MB */
b_skip = h->mb.b_skip_mc = i_bskip_cost <= ((6 * analysis.i_lambda2 + 128) >> 8);
}
else if( !h->mb.b_direct_auto_write )
{
/* Conditioning the probe on neighboring block types
* doesn't seem to help speed or quality. */
analysis.b_try_skip = x264_macroblock_probe_bskip( h );
if( h->param.analyse.i_subpel_refine < 3 )
b_skip = analysis.b_try_skip;
}
/* Set up MVs for future predictors */
if( b_skip )
{
for( int i = 0; i < h->mb.pic.i_fref[0]; i++ )
M32( h->mb.mvr[0][i][h->mb.i_mb_xy] ) = 0;
for( int i = 0; i < h->mb.pic.i_fref[1]; i++ )
M32( h->mb.mvr[1][i][h->mb.i_mb_xy] ) = 0;
}
}
if( !b_skip )
{
const unsigned int flags = h->param.analyse.inter;
int i_type;
int i_partition;
int i_satd_inter;
h->mb.b_skip_mc = 0;
h->mb.i_type = B_DIRECT;
x264_mb_analyse_load_costs( h, &analysis );
/* select best inter mode */
/* direct must be first */
if( analysis.b_direct_available )
x264_mb_analyse_inter_direct( h, &analysis );
x264_mb_analyse_inter_b16x16( h, &analysis ); ///16x16 帧间预测宏块分析--B
if( h->mb.i_type == B_SKIP )
{
for( int i = 1; i < h->mb.pic.i_fref[0]; i++ )
M32( h->mb.mvr[0][i][h->mb.i_mb_xy] ) = 0;
for( int i = 1; i < h->mb.pic.i_fref[1]; i++ )
M32( h->mb.mvr[1][i][h->mb.i_mb_xy] ) = 0;
return;
}
i_type = B_L0_L0;
i_partition = D_16x16;
i_cost = analysis.l0.me16x16.cost;
COPY2_IF_LT( i_cost, analysis.l1.me16x16.cost, i_type, B_L1_L1 );
COPY2_IF_LT( i_cost, analysis.i_cost16x16bi, i_type, B_BI_BI );
COPY2_IF_LT( i_cost, analysis.i_cost16x16direct, i_type, B_DIRECT );
if( analysis.i_mbrd && analysis.b_early_terminate && analysis.i_cost16x16direct <= i_cost * 33/32 )
{
x264_mb_analyse_b_rd( h, &analysis, i_cost );
if( i_bskip_cost < analysis.i_rd16x16direct &&
i_bskip_cost < analysis.i_rd16x16bi &&
i_bskip_cost < analysis.l0.i_rd16x16 &&
i_bskip_cost < analysis.l1.i_rd16x16 )
{
h->mb.i_type = B_SKIP;
x264_analyse_update_cache( h, &analysis );
return;
}
}
if( flags & X264_ANALYSE_BSUB16x16 )
{
if( h->param.analyse.b_mixed_references )
x264_mb_analyse_inter_b8x8_mixed_ref( h, &analysis );
else
x264_mb_analyse_inter_b8x8( h, &analysis ); ///8x8 帧间预测宏块分析--B
COPY3_IF_LT( i_cost, analysis.i_cost8x8bi, i_type, B_8x8, i_partition, D_8x8 );
/* Try to estimate the cost of b16x8/b8x16 based on the satd scores of the b8x8 modes */
int i_cost_est16x8bi_total = 0, i_cost_est8x16bi_total = 0;
int i_mb_type, i_partition16x8[2], i_partition8x16[2];
for( int i = 0; i < 2; i++ )
{
int avg_l0_mv_ref_cost, avg_l1_mv_ref_cost;
int i_l0_satd, i_l1_satd, i_bi_satd, i_best_cost;
// 16x8
i_best_cost = COST_MAX;
i_l0_satd = analysis.i_satd8x8[0][i*2] + analysis.i_satd8x8[0][i*2+1];
i_l1_satd = analysis.i_satd8x8[1][i*2] + analysis.i_satd8x8[1][i*2+1];
i_bi_satd = analysis.i_satd8x8[2][i*2] + analysis.i_satd8x8[2][i*2+1];
avg_l0_mv_ref_cost = ( analysis.l0.me8x8[i*2].cost_mv + analysis.l0.me8x8[i*2].i_ref_cost
+ analysis.l0.me8x8[i*2+1].cost_mv + analysis.l0.me8x8[i*2+1].i_ref_cost + 1 ) >> 1;
avg_l1_mv_ref_cost = ( analysis.l1.me8x8[i*2].cost_mv + analysis.l1.me8x8[i*2].i_ref_cost
+ analysis.l1.me8x8[i*2+1].cost_mv + analysis.l1.me8x8[i*2+1].i_ref_cost + 1 ) >> 1;
COPY2_IF_LT( i_best_cost, i_l0_satd + avg_l0_mv_ref_cost, i_partition16x8[i], D_L0_8x8 );
COPY2_IF_LT( i_best_cost, i_l1_satd + avg_l1_mv_ref_cost, i_partition16x8[i], D_L1_8x8 );
COPY2_IF_LT( i_best_cost, i_bi_satd + avg_l0_mv_ref_cost + avg_l1_mv_ref_cost, i_partition16x8[i], D_BI_8x8 );
analysis.i_cost_est16x8[i] = i_best_cost;
// 8x16
i_best_cost = COST_MAX;
i_l0_satd = analysis.i_satd8x8[0][i] + analysis.i_satd8x8[0][i+2];
i_l1_satd = analysis.i_satd8x8[1][i] + analysis.i_satd8x8[1][i+2];
i_bi_satd = analysis.i_satd8x8[2][i] + analysis.i_satd8x8[2][i+2];
avg_l0_mv_ref_cost = ( analysis.l0.me8x8[i].cost_mv + analysis.l0.me8x8[i].i_ref_cost
+ analysis.l0.me8x8[i+2].cost_mv + analysis.l0.me8x8[i+2].i_ref_cost + 1 ) >> 1;
avg_l1_mv_ref_cost = ( analysis.l1.me8x8[i].cost_mv + analysis.l1.me8x8[i].i_ref_cost
+ analysis.l1.me8x8[i+2].cost_mv + analysis.l1.me8x8[i+2].i_ref_cost + 1 ) >> 1;
COPY2_IF_LT( i_best_cost, i_l0_satd + avg_l0_mv_ref_cost, i_partition8x16[i], D_L0_8x8 );
COPY2_IF_LT( i_best_cost, i_l1_satd + avg_l1_mv_ref_cost, i_partition8x16[i], D_L1_8x8 );
COPY2_IF_LT( i_best_cost, i_bi_satd + avg_l0_mv_ref_cost + avg_l1_mv_ref_cost, i_partition8x16[i], D_BI_8x8 );
analysis.i_cost_est8x16[i] = i_best_cost;
}
i_mb_type = B_L0_L0 + (i_partition16x8[0]>>2) * 3 + (i_partition16x8[1]>>2);
analysis.i_cost_est16x8[1] += analysis.i_lambda * i_mb_b16x8_cost_table[i_mb_type];
i_cost_est16x8bi_total = analysis.i_cost_est16x8[0] + analysis.i_cost_est16x8[1];
i_mb_type = B_L0_L0 + (i_partition8x16[0]>>2) * 3 + (i_partition8x16[1]>>2);
analysis.i_cost_est8x16[1] += analysis.i_lambda * i_mb_b16x8_cost_table[i_mb_type];
i_cost_est8x16bi_total = analysis.i_cost_est8x16[0] + analysis.i_cost_est8x16[1];
/* We can gain a little speed by checking the mode with the lowest estimated cost first */
int try_16x8_first = i_cost_est16x8bi_total < i_cost_est8x16bi_total;
if( try_16x8_first && (!analysis.b_early_terminate || i_cost_est16x8bi_total < i_cost) )
{
x264_mb_analyse_inter_b16x8( h, &analysis, i_cost ); ///16x8 帧间预测宏块分析--B
COPY3_IF_LT( i_cost, analysis.i_cost16x8bi, i_type, analysis.i_mb_type16x8, i_partition, D_16x8 );
}
if( !analysis.b_early_terminate || i_cost_est8x16bi_total < i_cost )
{
x264_mb_analyse_inter_b8x16( h, &analysis, i_cost ); ///8x16 帧间预测宏块分析--B
COPY3_IF_LT( i_cost, analysis.i_cost8x16bi, i_type, analysis.i_mb_type8x16, i_partition, D_8x16 );
}
if( !try_16x8_first && (!analysis.b_early_terminate || i_cost_est16x8bi_total < i_cost) )
{
x264_mb_analyse_inter_b16x8( h, &analysis, i_cost ); ///16x8 帧间预测宏块分析--B
COPY3_IF_LT( i_cost, analysis.i_cost16x8bi, i_type, analysis.i_mb_type16x8, i_partition, D_16x8 );
}
}
if( analysis.i_mbrd || !h->mb.i_subpel_refine )
{
/* refine later */
}
/* refine qpel */
else if( i_partition == D_16x16 )
{
analysis.l0.me16x16.cost -= analysis.i_lambda * i_mb_b_cost_table[B_L0_L0];
analysis.l1.me16x16.cost -= analysis.i_lambda * i_mb_b_cost_table[B_L1_L1];
if( i_type == B_L0_L0 )
{
x264_me_refine_qpel( h, &analysis.l0.me16x16 ); /亚像素精度搜索
i_cost = analysis.l0.me16x16.cost
+ analysis.i_lambda * i_mb_b_cost_table[B_L0_L0];
}
else if( i_type == B_L1_L1 )
{
x264_me_refine_qpel( h, &analysis.l1.me16x16 );
i_cost = analysis.l1.me16x16.cost
+ analysis.i_lambda * i_mb_b_cost_table[B_L1_L1];
}
else if( i_type == B_BI_BI )
{
x264_me_refine_qpel( h, &analysis.l0.bi16x16 );
x264_me_refine_qpel( h, &analysis.l1.bi16x16 );
}
}
else if( i_partition == D_16x8 )
{
for( int i = 0; i < 2; i++ )
{
if( analysis.i_mb_partition16x8[i] != D_L1_8x8 )
x264_me_refine_qpel( h, &analysis.l0.me16x8[i] );
if( analysis.i_mb_partition16x8[i] != D_L0_8x8 )
x264_me_refine_qpel( h, &analysis.l1.me16x8[i] );
}
}
else if( i_partition == D_8x16 )
{
for( int i = 0; i < 2; i++ )
{
if( analysis.i_mb_partition8x16[i] != D_L1_8x8 )
x264_me_refine_qpel( h, &analysis.l0.me8x16[i] );
if( analysis.i_mb_partition8x16[i] != D_L0_8x8 )
x264_me_refine_qpel( h, &analysis.l1.me8x16[i] );
}
}
else if( i_partition == D_8x8 )
{
for( int i = 0; i < 4; i++ )
{
x264_me_t *m;
int i_part_cost_old;
int i_type_cost;
int i_part_type = h->mb.i_sub_partition[i];
int b_bidir = (i_part_type == D_BI_8x8);
if( i_part_type == D_DIRECT_8x8 )
continue;
if( x264_mb_partition_listX_table[0][i_part_type] )
{
m = &analysis.l0.me8x8[i];
i_part_cost_old = m->cost;
i_type_cost = analysis.i_lambda * i_sub_mb_b_cost_table[D_L0_8x8];
m->cost -= i_type_cost;
x264_me_refine_qpel( h, m );
if( !b_bidir )
analysis.i_cost8x8bi += m->cost + i_type_cost - i_part_cost_old;
}
if( x264_mb_partition_listX_table[1][i_part_type] )
{
m = &analysis.l1.me8x8[i];
i_part_cost_old = m->cost;
i_type_cost = analysis.i_lambda * i_sub_mb_b_cost_table[D_L1_8x8];
m->cost -= i_type_cost;
x264_me_refine_qpel( h, m );
if( !b_bidir )
analysis.i_cost8x8bi += m->cost + i_type_cost - i_part_cost_old;
}
/* TODO: update mvp? */
}
}
i_satd_inter = i_cost;
if( analysis.i_mbrd )
{
x264_mb_analyse_b_rd( h, &analysis, i_satd_inter );
i_type = B_SKIP;
i_cost = i_bskip_cost;
i_partition = D_16x16;
COPY2_IF_LT( i_cost, analysis.l0.i_rd16x16, i_type, B_L0_L0 );
COPY2_IF_LT( i_cost, analysis.l1.i_rd16x16, i_type, B_L1_L1 );
COPY2_IF_LT( i_cost, analysis.i_rd16x16bi, i_type, B_BI_BI );
COPY2_IF_LT( i_cost, analysis.i_rd16x16direct, i_type, B_DIRECT );
COPY3_IF_LT( i_cost, analysis.i_rd16x8bi, i_type, analysis.i_mb_type16x8, i_partition, D_16x8 );
COPY3_IF_LT( i_cost, analysis.i_rd8x16bi, i_type, analysis.i_mb_type8x16, i_partition, D_8x16 );
COPY3_IF_LT( i_cost, analysis.i_rd8x8bi, i_type, B_8x8, i_partition, D_8x8 );
h->mb.i_type = i_type;
h->mb.i_partition = i_partition;
}
if( h->mb.b_chroma_me )
{
if( CHROMA444 )
{
x264_mb_analyse_intra( h, &analysis, i_satd_inter );
x264_mb_analyse_intra_chroma( h, &analysis );
}
else
{
x264_mb_analyse_intra_chroma( h, &analysis );
x264_mb_analyse_intra( h, &analysis, i_satd_inter - analysis.i_satd_chroma );
}
analysis.i_satd_i16x16 += analysis.i_satd_chroma;
analysis.i_satd_i8x8 += analysis.i_satd_chroma;
analysis.i_satd_i4x4 += analysis.i_satd_chroma;
}
else
x264_mb_analyse_intra( h, &analysis, i_satd_inter );//B Slice中也允许有Intra宏块,所以也要进行分析
if( analysis.i_mbrd )
{
x264_mb_analyse_transform_rd( h, &analysis, &i_satd_inter, &i_cost );
x264_intra_rd( h, &analysis, i_satd_inter * 17/16 + 1 );
}
COPY2_IF_LT( i_cost, analysis.i_satd_i16x16, i_type, I_16x16 );
COPY2_IF_LT( i_cost, analysis.i_satd_i8x8, i_type, I_8x8 );
COPY2_IF_LT( i_cost, analysis.i_satd_i4x4, i_type, I_4x4 );
COPY2_IF_LT( i_cost, analysis.i_satd_pcm, i_type, I_PCM );
h->mb.i_type = i_type;
h->mb.i_partition = i_partition;
if( analysis.i_mbrd >= 2 && IS_INTRA( i_type ) && i_type != I_PCM )
x264_intra_rd_refine( h, &analysis );
if( h->mb.i_subpel_refine >= 5 )
x264_refine_bidir( h, &analysis );
if( analysis.i_mbrd >= 2 && i_type > B_DIRECT && i_type < B_SKIP )
{
int i_biweight;
x264_analyse_update_cache( h, &analysis ); /
if( i_partition == D_16x16 )
{
if( i_type == B_L0_L0 )
{
analysis.l0.me16x16.cost = i_cost;
x264_me_refine_qpel_rd( h, &analysis.l0.me16x16, analysis.i_lambda2, 0, 0 );
}
else if( i_type == B_L1_L1 )
{
analysis.l1.me16x16.cost = i_cost;
x264_me_refine_qpel_rd( h, &analysis.l1.me16x16, analysis.i_lambda2, 0, 1 );
}
else if( i_type == B_BI_BI )
{
i_biweight = h->mb.bipred_weight[analysis.l0.bi16x16.i_ref][analysis.l1.bi16x16.i_ref];
x264_me_refine_bidir_rd( h, &analysis.l0.bi16x16, &analysis.l1.bi16x16, i_biweight, 0, analysis.i_lambda2 );
}
}
else if( i_partition == D_16x8 )
{
for( int i = 0; i < 2; i++ )
{
h->mb.i_sub_partition[i*2] = h->mb.i_sub_partition[i*2+1] = analysis.i_mb_partition16x8[i];
if( analysis.i_mb_partition16x8[i] == D_L0_8x8 )
x264_me_refine_qpel_rd( h, &analysis.l0.me16x8[i], analysis.i_lambda2, i*8, 0 );
else if( analysis.i_mb_partition16x8[i] == D_L1_8x8 )
x264_me_refine_qpel_rd( h, &analysis.l1.me16x8[i], analysis.i_lambda2, i*8, 1 );
else if( analysis.i_mb_partition16x8[i] == D_BI_8x8 )
{
i_biweight = h->mb.bipred_weight[analysis.l0.me16x8[i].i_ref][analysis.l1.me16x8[i].i_ref];
x264_me_refine_bidir_rd( h, &analysis.l0.me16x8[i], &analysis.l1.me16x8[i], i_biweight, i*2, analysis.i_lambda2 );
}
}
}
else if( i_partition == D_8x16 )
{
for( int i = 0; i < 2; i++ )
{
h->mb.i_sub_partition[i] = h->mb.i_sub_partition[i+2] = analysis.i_mb_partition8x16[i];
if( analysis.i_mb_partition8x16[i] == D_L0_8x8 )
x264_me_refine_qpel_rd( h, &analysis.l0.me8x16[i], analysis.i_lambda2, i*4, 0 );
else if( analysis.i_mb_partition8x16[i] == D_L1_8x8 )
x264_me_refine_qpel_rd( h, &analysis.l1.me8x16[i], analysis.i_lambda2, i*4, 1 );
else if( analysis.i_mb_partition8x16[i] == D_BI_8x8 )
{
i_biweight = h->mb.bipred_weight[analysis.l0.me8x16[i].i_ref][analysis.l1.me8x16[i].i_ref];
x264_me_refine_bidir_rd( h, &analysis.l0.me8x16[i], &analysis.l1.me8x16[i], i_biweight, i, analysis.i_lambda2 );
}
}
}
else if( i_partition == D_8x8 )
{
for( int i = 0; i < 4; i++ )
{
if( h->mb.i_sub_partition[i] == D_L0_8x8 )
x264_me_refine_qpel_rd( h, &analysis.l0.me8x8[i], analysis.i_lambda2, i*4, 0 );
else if( h->mb.i_sub_partition[i] == D_L1_8x8 )
x264_me_refine_qpel_rd( h, &analysis.l1.me8x8[i], analysis.i_lambda2, i*4, 1 );
else if( h->mb.i_sub_partition[i] == D_BI_8x8 )
{
i_biweight = h->mb.bipred_weight[analysis.l0.me8x8[i].i_ref][analysis.l1.me8x8[i].i_ref];
x264_me_refine_bidir_rd( h, &analysis.l0.me8x8[i], &analysis.l1.me8x8[i], i_biweight, i, analysis.i_lambda2 );
}
}
}
}
}
}
x264_analyse_update_cache( h, &analysis ); ///
/* In rare cases we can end up qpel-RDing our way back to a larger partition size
* without realizing it. Check for this and account for it if necessary. */
if( analysis.i_mbrd >= 2 )
{
/* Don't bother with bipred or 8x8-and-below, the odds are incredibly low. */
static const uint8_t check_mv_lists[X264_MBTYPE_MAX] = {[P_L0]=1, [B_L0_L0]=1, [B_L1_L1]=2};
int list = check_mv_lists[h->mb.i_type] - 1;
if( list >= 0 && h->mb.i_partition != D_16x16 &&
M32( &h->mb.cache.mv[list][x264_scan8[0]] ) == M32( &h->mb.cache.mv[list][x264_scan8[12]] ) &&
h->mb.cache.ref[list][x264_scan8[0]] == h->mb.cache.ref[list][x264_scan8[12]] )
h->mb.i_partition = D_16x16;
}
if( !analysis.i_mbrd )
x264_mb_analyse_transform( h ); ///
if( analysis.i_mbrd == 3 && !IS_SKIP(h->mb.i_type) )
x264_mb_analyse_qp_rd( h, &analysis ); ///
h->mb.b_trellis = h->param.analyse.i_trellis;
h->mb.b_noise_reduction = h->mb.b_noise_reduction || (!!h->param.analyse.i_noise_reduction && !IS_INTRA( h->mb.i_type ));
if( !IS_SKIP(h->mb.i_type) && h->mb.i_psy_trellis && h->param.analyse.i_trellis == 1 )
x264_psy_trellis_init( h, 0 );
if( h->mb.b_trellis == 1 || h->mb.b_noise_reduction )
h->mb.i_skip_intra = 0;
}
尽管x264_macroblock_analyse()的源代码比较长,但是它的逻辑比较清晰,如下所示:
(1)、如果当前是I Slice,调用x264_mb_analyse_intra()进行Intra宏块的帧内预测模式分析。
(2)、如果当前是P Slice,则进行下面流程的分析:
a)、调用x264_macroblock_probe_pskip()分析是否为Skip宏块,如果是的话则不再进行下面分析。
b)、调用x264_mb_analyse_inter_p16x16()分析P16x16帧间预测的代价。
c)、调用x264_mb_analyse_inter_p8x8()分析P8x8帧间预测的代价。
d)、如果P8x8代价值小于P16x16,则依次对4个8x8的子宏块分割进行判断:
i、调用x264_mb_analyse_inter_p4x4()分析P4x4帧间预测的代价。
ii、如果P4x4代价值小于P8x8,则调用 x264_mb_analyse_inter_p8x4()和x264_mb_analyse_inter_p4x8()分析P8x4和P4x8帧间预测的代价。
e)、如果P8x8代价值小于P16x16,调用x264_mb_analyse_inter_p16x8()和x264_mb_analyse_inter_p8x16()分析P16x8和P8x16帧间预测的代价。
f)、此外还要调用x264_mb_analyse_intra(),检查当前宏块作为Intra宏块编码的代价是否小于作为P宏块编码的代价(P Slice中也允许有Intra宏块)。
(3)、如果当前是B Slice,则进行和P Slice类似的处理。