Kafka-Producer API,异步发送,分区器,同步发送,Consumer API,自动提交和手动提交offset
文章目录
- Producer API
- 1 消息发送流程
- 2 异步发送API
- 3 分区器
- 4 同步发送API
- Consumer API
- 1 自动提交offset
- 2 手动提交offset
Producer API
1 消息发送流程
Kafka的Producer发送消息采用的是异步发送的方式。在消息发送的过程中,涉及到了两个线程main线程和Sender线程,以及一个线程共享变量RecordAccumulator。main线程将消息发送给RecordAccumulator,Sender线程不断从RecordAccumulator中拉取消息发送到Kafka broker。
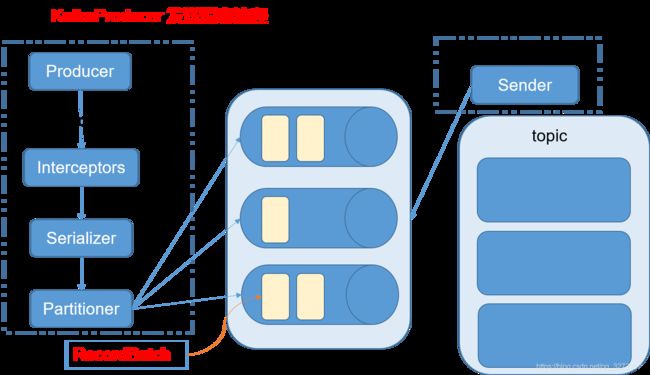
相关参数:
batch.size:只有数据积累到batch.size之后,sender才会发送数据。
linger.ms:如果数据迟迟未达到batch.size,sender等待linger.time之后就会发送数据。
2 异步发送API
需要用到的类:
KafkaProducer:需要创建一个生产者对象,用来发送数据
ProducerConfig:获取所需的一系列配置参数
ProducerRecord:每条数据都要封装成一个ProducerRecord对象
(1)不带回调函数的API
package com.qinjl.producer;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;
import java.util.Properties;
public class MyProducer {
public static void main(String[] args) throws InterruptedException {
// 创建配置对象
Properties properties = new Properties();
// 设置kafka集群,broker-list
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "hadoop102:9092");
// 设定ack等级
properties.put(ProducerConfig.ACKS_CONFIG, "all");
// 设定重试次数
properties.put(ProducerConfig.RETRIES_CONFIG, 3);
// 设定batch大小
properties.put(ProducerConfig.BATCH_SIZE_CONFIG, 16384);
// 设定等待时间
properties.put(ProducerConfig.LINGER_MS_CONFIG, 1);
// 设定RecordAccumulator缓冲区大小 32M
properties.put(ProducerConfig.BUFFER_MEMORY_CONFIG, 33554432);
// 设定key和value的序列化方式
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,
"org.apache.kafka.common.serialization.StringSerializer");
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,
"org.apache.kafka.common.serialization.StringSerializer");
// 创建生产者的客户端对象
KafkaProducer<String, String> producer = new KafkaProducer<>(properties);
for (int i = 0; i < 10; i++) {
// 采用生产者对象发送数据
producer.send(new ProducerRecord<String, String>("first","hello-->"+i ));
}
// 关闭客户端对象
// 这个close会在关闭前,将所有数据处理完再推出生产者
producer.close();
}
}
(2)带回调函数的API
回调函数会在 producer 收到 ack 时调用,为异步调用,该方法有两个参数,分别是RecordMetadata和Exception,如果Exception为null,说明消息发送成功,如果Exception不为null,说明消息发送失败。
- 注:消息发送失败会自动重试,不需要我们在回调函数中手动重试。
public class CallBackProducer {
public static void main(String[] args) throws InterruptedException {
//创建生产者的配置对象
Properties properties = new Properties();
// 设置kafka集群,broker-list
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "hadoop102:9092");
// 设定ack等级
properties.put(ProducerConfig.ACKS_CONFIG, "all");
// 设定重试次数
properties.put(ProducerConfig.RETRIES_CONFIG, 3);
// 设定batch大小
properties.put(ProducerConfig.BATCH_SIZE_CONFIG, 16384);
// 设定等待时间
properties.put(ProducerConfig.LINGER_MS_CONFIG, 1);
// 设定RecordAccumulator缓冲区大小 32M
properties.put(ProducerConfig.BUFFER_MEMORY_CONFIG, 33554432);
// 设定key和value的序列化方式
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,
"org.apache.kafka.common.serialization.StringSerializer");
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,
"org.apache.kafka.common.serialization.StringSerializer");
// 创建生产者对象
KafkaProducer<String, String> producer = new KafkaProducer<>(properties);
//发送数据
for (int i = 0; i < 10; i++) {
producer.send(new ProducerRecord<String, String>("second", "hello-->" + i),
new Callback() {
@Override
//这个回调函数 在ack正常返回的时候是返回metadata,如果不正常返回则返回异常
public void onCompletion(RecordMetadata metadata, Exception exception) {
if (exception==null){
System.out.println("topic:"+metadata.topic()+"--partition:"
+metadata.partition()+"--offset:"+metadata.offset());
}
}
});
}
// 关闭生产者对象
producer.close();
}
}
3 分区器
- 自定义分区器,可以根据需求指定消息发往那个分区,例如:包含”hello world“的发往0号分区,其余的发往1号分区。
public class MyPartitioner implements Partitioner {
@Override
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {
String msg = new String(valueBytes);
if (msg.contains("hello world")) return 0;
else return 1;
}
@Override
public void close() {
}
@Override
public void configure(Map<String, ?> configs) {
}
}
- 在producer指定,自定义分区器类的全路径。
public static void main(String[] args) throws Exception {
Properties properties = new Properties();
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "hadoop102:9092");
properties.put(ProducerConfig.ACKS_CONFIG, "all");
properties.put(ProducerConfig.RETRIES_CONFIG, 3);
properties.put(ProducerConfig.BATCH_SIZE_CONFIG, 16384);
properties.put(ProducerConfig.LINGER_MS_CONFIG, 1);
properties.put(ProducerConfig.BUFFER_MEMORY_CONFIG, 33554432);
// 指定自定义分区类
properties.put(ProducerConfig.PARTITIONER_CLASS_CONFIG,
"com.qinjl.partitioner.MyPartitioner");
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,
"org.apache.kafka.common.serialization.StringSerializer");
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,
"org.apache.kafka.common.serialization.StringSerializer");
KafkaProducer<String, String> producer = new KafkaProducer<>(properties);
for (int i = 0; i < 10; i++) {
if (i < 5) {
producer.send(new ProducerRecord<>("test", "hello world->" + i), new Callback() {
@Override
public void onCompletion(RecordMetadata metadata, Exception exception) {
if (exception == null) {
System.out.println("topic:" + metadata.topic() + "--partition:"
+ metadata.partition() + "--offset:" + metadata.offset());
}
}
});
} else {
producer.send(new ProducerRecord<>("test", "axi->" + i),
(metadata, exception) -> {
if (exception == null) {
System.out.println("topic:" + metadata.topic() + "--partition:"
+ metadata.partition() + "--offset:" + metadata.offset());
}
});
}
}
producer.close();
}
}
4 同步发送API
同步发送的意思就是,一条消息发送之后,会阻塞当前线程,直至返回ack。
由于send方法返回的是一个Future对象,根据Futrue对象的特点,也可以实现同步发送的效果,只需在调用Future对象的get方发即可。
public class SyncProducer {
public static void main(String[] args) throws InterruptedException {
//创建生产者的配置对象
Properties properties = new Properties();
// 设置kafka集群,broker-list
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "hadoop102:9092");
// 设定ack等级
properties.put(ProducerConfig.ACKS_CONFIG, "all");
// 设定重试次数
properties.put(ProducerConfig.RETRIES_CONFIG, 3);
// 设定batch大小
properties.put(ProducerConfig.BATCH_SIZE_CONFIG, 16384);
// 设定等待时间
properties.put(ProducerConfig.LINGER_MS_CONFIG, 1);
// 设定RecordAccumulator缓冲区大小 32M
properties.put(ProducerConfig.BUFFER_MEMORY_CONFIG, 33554432);
// 设定key和value的序列化方式
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,
"org.apache.kafka.common.serialization.StringSerializer");
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,
"org.apache.kafka.common.serialization.StringSerializer");
// 创建生产者对象
KafkaProducer<String, String> producer = new KafkaProducer<>(properties);
//发送数据
for (int i = 0; i < 10; i++) {
Future future = producer.send(new ProducerRecord<>("test", "hello world->" + i), new Callback() {
@Override
public void onCompletion(RecordMetadata metadata, Exception exception) {
if (exception == null) {
System.out.println("topic:" + metadata.topic() + "--partition:"
+ metadata.partition() + "--offset:" + metadata.offset());
}
}
});
future.get();
}
// 关闭生产者对象
producer.close();
}
}
Consumer API
Consumer消费数据时的可靠性是很容易保证的,因为数据在Kafka中是持久化的,故不用担心数据丢失问题。
由于consumer在消费过程中可能会出现断电宕机等故障,consumer恢复后,需要从故障前的位置的继续消费,所以consumer需要实时记录自己消费到了哪个offset,以便故障恢复后继续消费。
所以offset的维护是Consumer消费数据是必须考虑的问题。
1 自动提交offset
需要用到的类:
KafkaConsumer:需要创建一个消费者对象,用来消费数据
ConsumerConfig:获取所需的一系列配置参数
ConsuemrRecord:每条数据都要封装成一个ConsumerRecord对象
为了使我们能够专注于自己的业务逻辑,Kafka提供了自动提交offset的功能。
自动提交offset的相关参数:
-
enable.auto.commit:是否开启自动提交 offset 功能
-
auto.commit.interval.ms:自动提交 offset 的时间间隔
重置offset:
auto.offset.rest = earliest | latest | none |
auto.offset.reset: What to do when there is no initial offset in Kafka or if the current offset does not exist any more on the server (e.g. because that data has been deleted):
earliest: automatically reset the offset to the earliest offset
latest: automatically reset the offset to the latest offset当想要重头开始消费,需要满足3个条件
1.当前的消费者的消费者组从来没有消费过订阅的主题
2.当前的消费者的消费者组的 offset 已经找不到(过期了超过7天对应数据被删除了)
3.需要将 AUTO_OFFSET_RESET_CONFIG 设置为 earliest
1)消费者自动提交offset
public class MyConsumer {
public static void main(String[] args) throws InterruptedException {
Properties properties = new Properties();
// 去配置集群
properties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "hadoop102:9092");
// 指定消费者的组,只要group.id相同,就属于同一个消费者组
properties.put(ConsumerConfig.GROUP_ID_CONFIG, "test01");
// 重置offset
props.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest");
// 指定自动提交偏移量(默认是false)
properties.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, "true");
// 每次自动提交偏移量的间隔时间
properties.put(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG, "1000");
// 设定key和value的反序列化
properties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringDeserializer");
properties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringDeserializer");
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(properties);
//对于消费者需要订阅主题
List<String> topics = new ArrayList<>();
topics.add("test");
consumer.subscribe(topics);
// 循环获取消息
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofSeconds(1));
// 遍历topics,获取每个topic
records.forEach(record -> {
System.out.println("topic:" + record.topic() +
"--partition:" + record.partition() +
"--offset:" + record.offset() +
"--key:" + record.key() +
"--value:" + record.value());
});
}
}
}
2 手动提交offset
虽然自动提交offset十分简介便利,但由于其是基于时间提交的,开发人员难以把握offset提交的时机。因此Kafka还提供了手动提交offset的API。
手动提交offset的方法有两种:分别是commitSync(同步提交)和commitAsync(异步提交)。两者的相同点是,都会将本次poll的一批数据最高的偏移量提交;不同点是,commitSync阻塞当前线程,一直到提交成功,并且会自动失败重试(由不可控因素导致,也会出现提交失败);而commitAsync则没有失败重试机制,故有可能提交失败。
1)同步提交offset
由于同步提交offset有失败重试机制,故更加可靠,以下为同步提交offset的示例。
public class SyncConsumer {
public static void main(String[] args) {
// 创建一个配置对象
Properties props = new Properties();
props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "hadoop102:9092");
props.put(ConsumerConfig.GROUP_ID_CONFIG, "test05");
// 关闭自动提交offset
props.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, "false");
// 设定key和value的反序列化
props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG,
"org.apache.kafka.common.serialization.StringDeserializer");
props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG,
"org.apache.kafka.common.serialization.StringDeserializer");
// 创建一个消费者对象
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
// 消费者需要订阅主题
ArrayList<String> topics = new ArrayList<>();
topics.add("test");
consumer.subscribe(topics);
while (true){
ConsumerRecords<String, String> records = consumer.poll(Duration.ofSeconds(1));
records.forEach(record -> {
System.out.println("topic:" + record.topic() +
"--partition:" + record.partition() +
"--offset:" + record.offset() +
"--key:" + record.key() +
"--value:" + record.value());
});
//同步提交,当前线程会阻塞直到offset提交成功
consumer.commitSync();
}
}
}
2)异步提交offset
虽然同步提交offset更可靠一些,但是由于其会阻塞当前线程,直到提交成功。因此吞吐量会收到很大的影响。因此更多的情况下,会选用异步提交offset的方式。
以下为异步提交offset的示例:
public class AsyncConsumer {
public static void main(String[] args) {
// 创建一个配置对象
Properties props = new Properties();
props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "hadoop102:9092");
props.put(ConsumerConfig.GROUP_ID_CONFIG, "test05");
// 关闭自动提交offset
props.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, "false");
// 设定key和value的反序列化
props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG,
"org.apache.kafka.common.serialization.StringDeserializer");
props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG,
"org.apache.kafka.common.serialization.StringDeserializer");
// 创建一个消费者对象
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
// 消费者需要订阅主题
ArrayList<String> topics = new ArrayList<>();
topics.add("test");
consumer.subscribe(topics);
while (true){
ConsumerRecords<String, String> records = consumer.poll(Duration.ofSeconds(1));
records.forEach(record -> {
System.out.println("topic:" + record.topic() +
"--partition:" + record.partition() +
"--offset:" + record.offset() +
"--key:" + record.key() +
"--value:" + record.value());
});
consumer.commitAsync(new OffsetCommitCallback() {
@Override
//这是个回调函数 当offset成功存储的时候会返回这个offsets,如果不成功存储返回exception
public void onComplete(Map<TopicPartition, OffsetAndMetadata> offsets, Exception exception) {
if (exception != null)
System.err.println("Commit failed for" + offsets);
}
});
}
}
}
3)数据漏消费和重复消费分析
无论是同步提交还是异步提交offset,都有可能会造成数据的漏消费或者重复消费。
先提交offset,后消费,有可能造成数据的漏消费;
先消费,后提交offset,有可能会造成数据的重复消费。