联合篇1:elasticsearch作为hbase的二级索引
联合篇1:elasticsearch作为hbase的二级索引
一、简述
1 适用场景
1 超大数据OLAP实时分页排序查询(千万级别毫秒返回)
2 数据字段多,但是可筛选的字段少,比如数据有15个字段,筛选查询的字段只有3-5个字段
2 组件介绍:
ES: 适合大数据检索,但是不适合作为数据存储
Hbase: 适合超大数据存储,但是不适合作为数据检索,在没有设置二级索引的情况下,只能针对rowkey进行操作,但是对于rowkey的精准查询速度可pb级别毫秒返回
Phoenix: 可以通俗的理解为hbase的sql转写工具,此外还可以对hbase设置二级索引,大量依靠phoenix建立二级索引后势必引起Hbase的索引滥用
Spark(hive):主要针对hbase中的数据进行校队和离线数仓分析,etl以及报表,用户标签等
Flume: 把数据实时从kafka中写入Hbase(之前用sparkstreaming写,最后对比flume不消耗核,最终又改为flume)
3 整体思路:
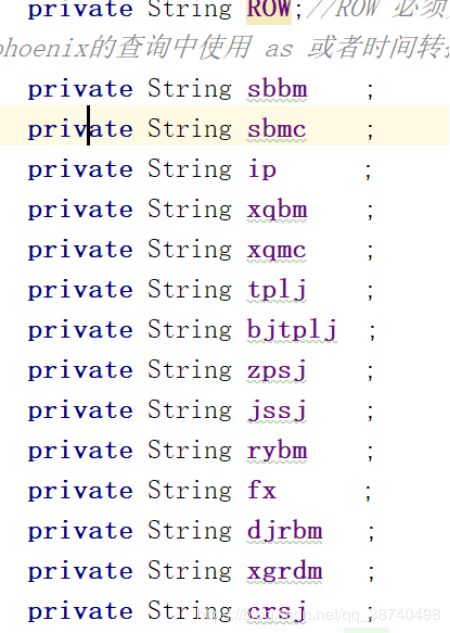
原字段有15个字段,那么可供搜索的字段只有
抓拍时间zpsj,
设备编码 sbbm,
小区编码xqbm,
只有这三个字段(索引字段越少越好),
大约有一半以上的字段都是没有搜索价值的
那么我们可以先用flume把这15个字段加载到hbase中,再把这3个索引字段加上rowkey总共4个字段抽到es中作为二级索引,为了节约资源,rowkey就只存在_id中,_source中不对rowkey进行另外存储

Es中通过时间地点人物排序分页筛选出rowkey,
然后通过rowkey从hbase中返回对应的明细数据
二 整体架构图:
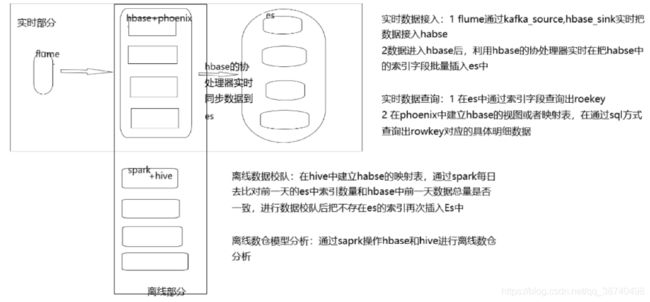
三 flume篇:
目的:把kafka中的数据写入Hbase
1 编写拦截器
Hbase-sink
(代码在拦截器包里)
2 编写conf
cd /opt/cloudera/parcels/CDH/lib/flume-ng/
vi hbase.conf
ng.sources = kafkaSource
ng.channels = memorychannel
ng.sinks = hbasesink
ng.sources.kafkaSource.type= org.apache.flume.source.kafka.KafkaSource
ng.sources.kafkaSource.kafka.bootstrap.servers=cdh01:9092,cdh02:9092,cdh03:9092
ng.sources.kafkaSource.kafka.consumer.group.id=xytest1222
ng.sources.kafkaSource.kafka.topics=pd_ry_txjl
ng.sources.kafkaSource.batchSize=1000
ng.sources.kafkaSource.channels= memorychannel
ng.sources.kafkaSource.kafka.consumer.auto.offset.reset=latest
ng.sources.kafkaSource.interceptors= i1
ng.sources.kafkaSource.interceptors.i1.type= com.iflytek.extracting.flume.interceptor.XyHbaseInterceptorLongTimeTC$Builder
ng.channels.memorychannel.type = memory
ng.channels.memorychannel.keep-alive = 3
ng.channels.memorychannel.byteCapacityBufferPercentage = 20
ng.channels.memorychannel.transactionCapacity = 10000
ng.channels.memorychannel.capacity = 100000
# sink 配置为 Hbase
ng.sinks.hbasesink.type = org.apache.flume.sink.hbase.HBaseSink
ng.sinks.hbasesink.table = rxjl2
ng.sinks.hbasesink.columnFamily = cf1
ng.sinks.hbasesink.serializer = org.apache.flume.sink.hbase.RegexHbaseEventSerializer
# 比如我要对nginx日志做分割,然后按列存储HBase,正则匹配分成的列为: ([xxx] [yyy] [zzz] [nnn] ...) 这种格式, 所以用下面的正则:
ng.sinks.hbasesink.serializer.regex = (.*)::(.*)::(.*)::(.*)::(.*)::(.*)::(.*)::(.*)::(.*)::(.*)::(.*)::(.*)::(.*)::(.*)::(.*)::(.*)::(.*)::(.*)::(.*)::(.*)::(.*)::(.*)
ng.sinks.hbasesink.serializer.colNames = ROW_KEY,mjbm,xqbm,xqmc,fx,txsj,bjtplj,sffx,rybm,rymc,djrdm,xgrdm,kmlxms,cjsj,xgsj,mjmc,rlmm,swmm,fz,zjhm,kmlx,rklxdm
ng.sinks.hbasesink.serializer.rowKeyIndex = 0
#ng.sinks.hbasesink.serializer.colNames = mjbm,xqbm,zjhm
#ng.sinks.hbasesink.zookeeperQuorum = cdh01:2181
ng.sinks.hbasesink.channel = memorychannel
3 启动flume
bin/flume-ng agent -n ng -c conf -f conf/hbase.conf
4 查看日志
cd /var/log/flume-ng/
tail -100f flume.log
四 Hbase的协处理器篇:
目的:把索引字段实时批量从hbase中导入es
1 编写协处理器
(代码在协处理器包里)
package com.iflytek.result;
import org.apache.commons.lang3.StringUtils;
import org.apache.commons.logging.Log;
import org.apache.commons.logging.LogFactory;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.Cell;
import org.apache.hadoop.hbase.CellUtil;
import org.apache.hadoop.hbase.CoprocessorEnvironment;
import org.apache.hadoop.hbase.client.Durability;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.coprocessor.BaseRegionObserver;
import org.apache.hadoop.hbase.coprocessor.ObserverContext;
import org.apache.hadoop.hbase.coprocessor.RegionCoprocessorEnvironment;
import org.apache.hadoop.hbase.regionserver.wal.WALEdit;
import org.apache.hadoop.hbase.util.Bytes;
import org.elasticsearch.action.bulk.BulkRequestBuilder;
import org.elasticsearch.client.transport.TransportClient;
import org.elasticsearch.common.settings.Settings;
import org.elasticsearch.common.transport.InetSocketTransportAddress;
import org.elasticsearch.transport.client.PreBuiltTransportClient;
import java.io.IOException;
import java.net.InetAddress;
import java.net.UnknownHostException;
import java.text.SimpleDateFormat;
import java.util.*;
public class Hbase2EsZpjl2 extends BaseRegionObserver {
private static final Log LOG = LogFactory.getLog(Hbase2EsZpjl2.class);
public String clusterName;
public String nodeHost;
public String indexName;
public String typeName;
public Integer nodePort;
private TransportClient client;
private SimpleDateFormat dataFormat =new SimpleDateFormat("yyyyMM");
private void readConfiguration(CoprocessorEnvironment env) {
Configuration conf = env.getConfiguration();
clusterName = conf.get("es_cluster","iflytek");
nodeHost = conf.get("es_host","cdh01");
nodePort = conf.getInt("es_port", 9350);
indexName = conf.get("es_index");
typeName = conf.get("es_type");
}
@Override
public void start(CoprocessorEnvironment e) throws IOException{
readConfiguration(e);
try {
Settings settings = Settings.builder()
.put("cluster.name",clusterName).build();
client = new PreBuiltTransportClient(settings)
.addTransportAddress(new InetSocketTransportAddress(InetAddress.getByName(nodeHost), nodePort));
}catch (UnknownHostException ex) {
ex.printStackTrace();
LOG.info("------init EsClient 识败------");
}
LOG.info("------init EsClient 成功------");
}
@Override
public void stop(CoprocessorEnvironment e) throws IOException {
client.close();
}
@Override
public void postPut(ObserverContext<RegionCoprocessorEnvironment> e, Put put, WALEdit edit, Durability durability) throws IOException {
String indexId = new String(put.getRow());
String dateString=null ;
Map<String, Object> json = new HashMap<String, Object>();
try{
BulkRequestBuilder bulkRequest = client.prepareBulk();
NavigableMap<byte[], List<Cell>> familyMap = put.getFamilyCellMap();
for (Map.Entry<byte[], List<Cell>> entry : familyMap.entrySet()) {
for (Cell cell : entry.getValue()) {
String key = Bytes.toString(CellUtil.cloneQualifier(cell));
String value = Bytes.toString(CellUtil.cloneValue(cell));
if (key.equals("zpsj") &&StringUtils.isNotBlank(value)) {
json.put(key, Long.parseLong(value));
dateString = dataFormat.format(Long.parseLong(value));
}else if (key.equals("xqbm") || key.equals("sbbm")) {
json.put(key, value);
}
}
}
bulkRequest.add( client.prepareUpdate(indexName+"_"+dateString,typeName, indexId).setDocAsUpsert(true).setDoc(json));
String format = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss:SSS").format(new Date());
long new_time = Long.parseLong(format.substring(17, 19));
if(new_time % 10 == 0){
bulkRequest.execute().actionGet();
bulkRequest = client.prepareBulk();
}
bulkRequest.execute().actionGet();
} catch (Exception ex) {
LOG.info("OK数据已经发往ES索引为"+indexName+"_"+dateString+"rowkey为:" + indexId+"内容为"+json+e);
}
}
}
//还有同步删除的方法,这里没有写,需要重写 postDelete方法
2 上传协处理器包到hdfs上
hdfs dfs -put Hbase2Es6-1.0-SNAPSHOT-jar-with-dependencies.jar /user/hive/warehouse/jars/
3 开启协处理器
disable "zpjl"
alter 'zpjl',METHOD =>'table_att','coprocessor'=>'hdfs:///user/hive/warehouse/jars/Hbase2Es7-1.0-SNAPSHOT-jar-with-dependencies.jar|com.iflytek.result.Hbase2EsZpjl2|1001|es_cluster=iflytek,es_type=caputre,es_index=xytest,es_port=9350,es_host=cdh01'
enable "zpjl"
五 Hbase篇
1 rowkey的设计:三要素:
短(最好16字节内)
散(分散均匀,不要让所有的rowkey都集中在同一region上)
唯一性
(业务上:rowkey为jild已具有散列性,唯一性,简短性稍有不足)
此外当初考虑加上rowkey前缀,利用max Inter-时间戳作为rowk前缀,但考虑到到简短性,此处rowkey就为Jlid,不做任何处理
2 预分区:主要和rowkey的散列性有关,我能提前对rowkey进行分区,可以大大提高查询效率
启动habse: hbase shell
新建预分区表:此处为16个分区,为了负载均衡最好采用4的倍数hbase机器效果最佳
create "zpjl","cf1",SPLITS=>['10000000-0000-0000-0000-000000000000','20000000-0000-0000-0000-000000000000','30000000-0000-0000-0000-000000000000','40000000-0000-0000-0000-000000000000','50000000-0000-0000-0000-000000000000','60000000-0000-0000-0000-000000000000','70000000-0000-0000-0000-000000000000','80000000-0000-0000-0000-000000000000','90000000-0000-0000-0000-000000000000',
'a0000000-0000-0000-0000-000000000000','b0000000-0000-0000-0000-000000000000',
'c0000000-0000-0000-0000-000000000000','d0000000-0000-0000-0000-000000000000',
'e0000000-0000-0000-0000-000000000000','f0000000-0000-0000-0000-000000000000']
打开hbase的web页面发现zpjl为16个分区
六 Phoenix篇
目的:在phoenix中建立hbase的视图,通过sql去查询hbase,并与spring boot集成
1 启动phoenix
cd /opt/cloudera/parcels/CLABS_PHOENIX/bin
sh phoenix-sqlline.py cdh01,cdh02,cdh03:2181
hbase表结构发生变化时,phoenix需要重新新建视图:
drop view "zpjl2";
create view "zpjl2"(
row varchar not null primary key,
"cf1"."sbbm" varchar,
"cf1"."sbmc" varchar,
"cf1"."ip" varchar,
"cf1"."xqbm" varchar,
"cf1"."xqmc" varchar,
"cf1"."tplj" varchar,
"cf1"."bjtplj" varchar,
"cf1"."zpsj" varchar,
"cf1"."jssj" varchar,
"cf1"."rybm" varchar,
"cf1"."fx" varchar,
"cf1"."djrbm" varchar,
"cf1"."xgrdm" varchar,
"cf1"."crsj" varchar
);
select * from “zpjl2” limit 10;
select count(*) from “zpjl2”;

七 Es篇:
1 Es为按月索引 后缀为_yyyyMM,每个索引为16个分片,并拥有相同的别名
2 Es查询:
判断时间范围:1 如果时间范围在一个月之内,进行倒排分页
2 如果时间范围大于30天,采用二次查询
第一次查询为:索引别名聚合查询

结果为:

第二次查询会根据具体的索引和起始位置进行顺排或者倒排
八 Hive 篇:
目的:把hbase中数据映射到hive,便于数据校队和离线数仓模型分析
映射是相互的,无论hive或者hbase的数据发生变化,都会相互变化,这也大大减少程序的复杂度,我可以直接向hive中读写数才操作hbase
1 在hive中创建habse的映射表
drop table if exists zpjl_hbase;
create external table if not exists zpjl_hbase(
ROW string,
sbbm string,
sbmc string,
ip string,
xqbm string,
xqmc string,
tplj string,
bjtplj string,
zpsj string,
jssj string,
rybm string,
fx string,
djrbm string,
crsj string
)
stored by 'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
with serdeproperties("hbase.columns.mapping"=":key,cf1:sbbm,cf1:sbmc,cf1:ip,cf1:xqbm,cf1:xqmc,cf1:tplj,cf1:bjtplj,cf1:zpsj,cf1:jssj,cf1:rybm,cf1:fx,cf1:djrbm,cf1:crsj")
tblproperties("hbase.table.name"="zpjl")
;
select * from zpjl_hbase limit 10;
select count(*) from zpjl_hbase;
九 Spark篇
目的:从hive中读取hbase的映射表,并与Es中数据进行校队,并进行离线分析,增大hive的效率
(目前此部分还有待优化,可以设置rowkey前缀为时间前缀,这样spark读写hbase的时候可以过滤查询前一天的数据,不用全读)
import org.apache.spark.sql.{DataFrame, SparkSession}
import org.elasticsearch.spark.sql._
val match_all =
"""| {"query":{"match_all":{}}}
""".stripMargin
val xydate1: DataFrame = sparkSession.esDF("pd_snapshot_record_search/snapshot", match_all)
// 在hive中建立临时表
xydate1.createOrReplaceTempView("pd_snapshot_record_search")
sparkSession.sqlContext.cacheTable("pd_snapshot_record_search")
sparkSession.sql(
"""
create table if not exists default.zpjl_spark(
ROW string,
sbbm string,
sbmc string,
ip string,
xqbm string,
xqmc string,
tplj string,
bjtplj string,
zpsj string,
jssj string,
rybm string,
fx string,
djrbm string,
crsj string
)
""".stripMargin)
sparkSession.sql(
"""
|insert into default.zpjl_spark
|select
|jlId,
|sbbm ,
|sbmc ,
|ip ,
|xqbm ,
|xqmc ,
|tplj ,
|bjtplj ,
|cast(zpsj as string) as zpsj ,
|cast(jssj as string) as jssj ,
|rybm ,
|cast(fx as string) as fx ,
|djrbm ,
|cast(crsj as string) as crsj
|from pd_snapshot_record_search
""".stripMargin)
sparkSession.sql(
"""
insert into zpjl_hbase
select * from zpjl_spark
""".stripMargin)
sparkSession.sqlContext.uncacheTable("pd_snapshot_record_search")